
Harness leverages neural networks to reduce false positives in log analysis by 50%, enhancing anomaly detection accuracy for production deployments, despite a slight increase in false negatives and performance challenges.
Analyzing Application Log Data With Harness
For the past 10 months at Harness, we have been analyzing application log events to help customers detect anomalies and verify their production deployments. To do this our algorithms have been based on textual similarity and occurrence frequencies. Harness has native integration for popular log aggregation tools such as Splunk, ELK, Sumologic and so on.
Our algorithms are a form of unsupervised machine learning, and we use conventional Natural Language Processing (NLP) tokenizers and a word frequencies-based approach.
We found that log events contain a fair amount of noise compared to natural language text, which significantly affects the rate of false positives.
See this example below:

The red circles are anomalies that the algorithm detected based on textual similarity. Looking at their respective texts on the left, the differences can be attributed to account IDs.
Although these messages are textually different (the alerts are generated for different accounts), they are contextually similar; i.e. they both are generated during some sort of alerting in the service.
Can Neural Nets Help?
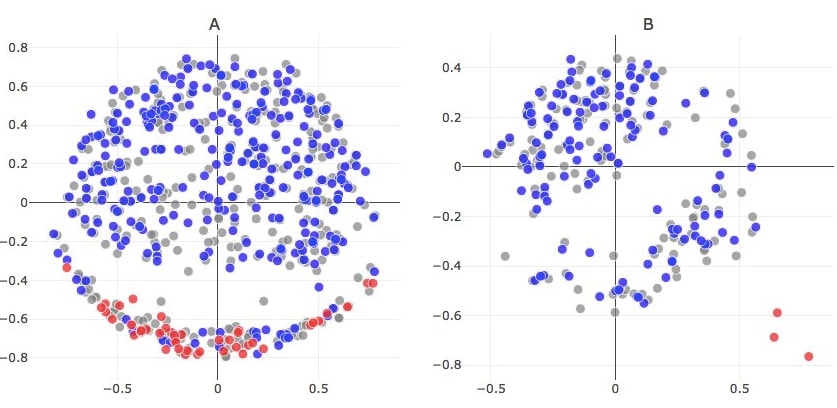
Recently we have been investigating the power of neural nets in text analysis. Neural nets can convert variable size log messages to fixed size vectors in a high dimensional space. Here is a side-by-side comparison with results from Neural Nets:

The chart on the left is what we showed above. The 2 gray circles are messages relating to alerts in the baseline data. They are shown separately due to the differences in account IDs. The 2 red circles are also alert messages but predicted as anomalies.
The chart on the right is what the Neural Nets predict. The 2 gray circles are merged into a single cluster, and the 2 red circles are replaced with a single blue circle indicating that it matches the grey underneath. Nice!
We have been running A/B experiments for a while to understand how Neural Nets impact false positives and have seen positive results.
Here is an example of some of the results/benefits we have seen:
The chart on the right is based on Neural Nets. By now, it should be self-explanatory.
Is It All Green On This Side of The River?
There are downsides to using Neural Nets for analyzing contextual similarity. For one, we saw a slight tick up in false negative rates--meaning, we saw a certain amount of failure in our ability to detect anomalies because the context is not always easy to discern.
The other obvious elephant in the room is performance. To deliver real-time anomaly detection, we have to train the Neural Net and use it as a predictive solution in real-time, an interesting challenge in itself.
Where To Next?
We think we are in a good shape to roll out our Neural Net based solution under feature flag control to select customers. With their real-life log inputs, we can learn and train our models well and can overcome the negatives. Over the coming months, we'll share updates on what we're learning from our experiments and customer verifications.
Thanks for reading!
Parnian Zargham, Raghu Singh, & Sriram Parthasarathy
Harness Data Science Team