
This blog introduces Harness Incident Response, a next-generation solution that combines AI-driven insights, seamless integration with DevOps workflows, and proactive incident prevention. Learn how to enhance operational excellence with an AI-powered SRE, automated workflows, and real-time visibility across your software delivery lifecycle.
Most incidents begin with change, yet traditional incident response tools treat them as isolated events. What if your response was seamlessly connected to the systems, changes, and workflows that caused them—leveraging generative AI to connect the dots? Not as a replacement for your team, but as a teammate working alongside them to help prevent, triage, and resolve issues faster.
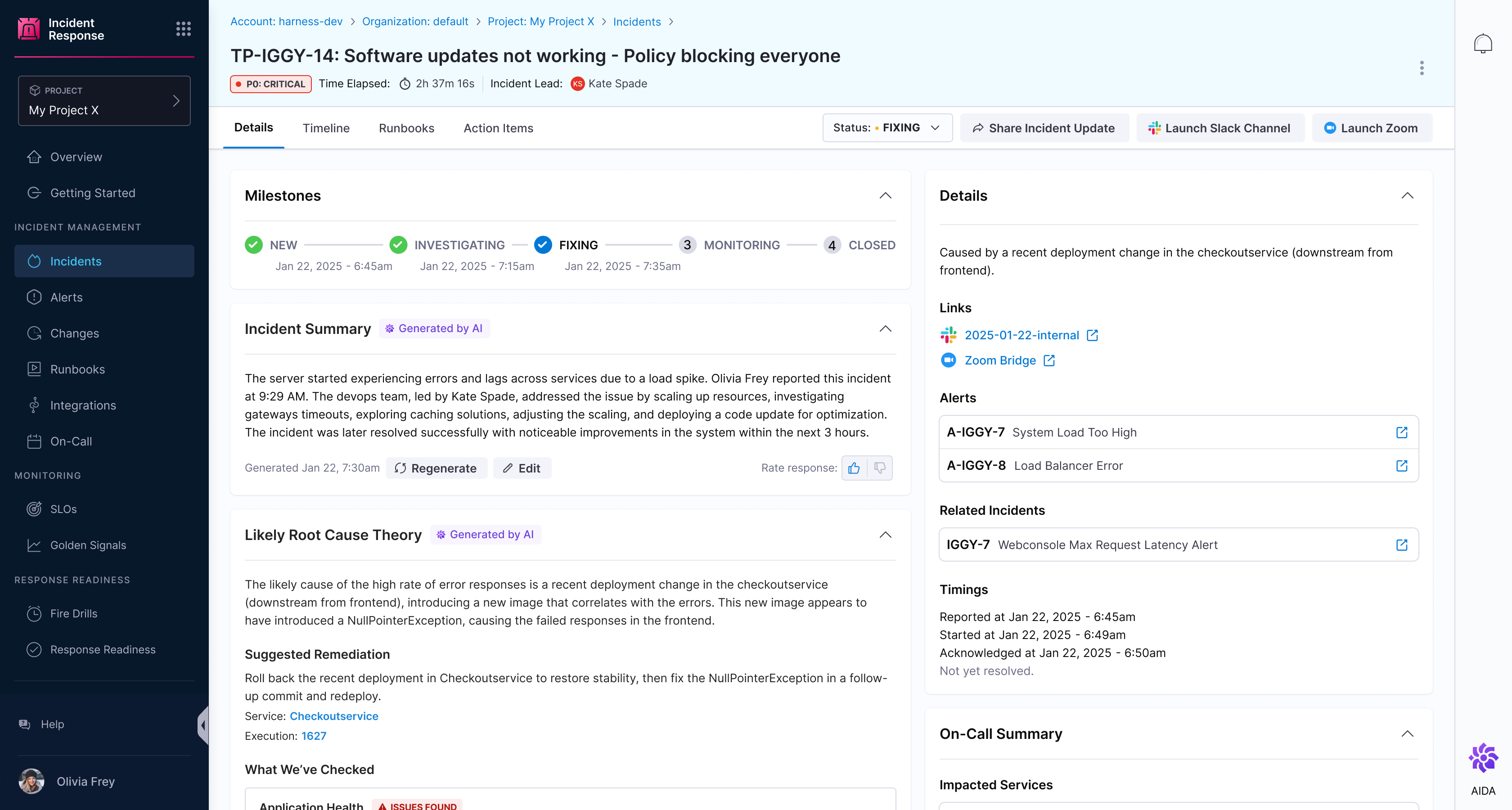
We’re thrilled to announce that Harness Incident Response (IR) is coming! This next-generation solution combines proactive issue prevention and rapid incident resolution to empower modern teams to minimize downtime, streamline workflows, and achieve operational excellence.
Harness Incident Response: AI-Powered, Human in the Loop Reliability
Harness IR builds on the foundation of Harness’s AI agent architecture, extending its capabilities beyond software delivery into the realm of incident response. At the heart of Harness IR is an always-available AI SRE agent seamlessly integrated within the Harness DevOps ecosystem. The AI SRE agent delivers actionable insights, guided triage, and tailored recommendations by connecting data across CI/CD pipelines, Feature Flags, infrastructure changes, and external updates. It doesn’t just correlate changes—it works dynamically with your team, asking questions to fill in gaps and ensuring critical context is never missing. Think of it as a dynamic runbook reimagined, where AI doesn’t act alone but collaborates with humans to drive faster, smarter decisions.
Harness IR is built on a foundation of end-to-end visibility and automation, enabling teams to track every change across the software delivery lifecycle, from code commits to deployments, and overlay that with alerts and incidents for a holistic view. It provides a single pane of glass for operational visibility, centralizing all critical data so your team can anticipate and mitigate issues before they escalate.
How Harness IR Makes Incident Response Smarter and Faster
Leverage AI for Proactive Incident Response
Harness the power of AI to detect application failures, identify root causes, and suggest actionable remediation steps. The AI SRE agent ensures faster, smarter decisions while preventing future issues by delivering actionable insights and guiding teams through triage and resolution.
Orchestrate and Visualize Operations Across Your Entire Pipeline
Coordinate workflows, automate responses, and streamline incident resolution with an end-to-end operational control plane spanning the entire software delivery lifecycle—including deployments, feature releases, security incidents, and cost anomalies. More than just orchestration, it acts as a centralized operations hub, offering a single pane of glass to monitor your pipeline and controls to take action in real-time.
.png)
Streamline the Incident Management Process
Harness IR combines on-call management, runbooks, incident workflows, readiness drills, and SLO tracking into a single, unified platform. Fully integrated into your DevOps workflows, it ensures seamless coordination across teams, clear accountability, and actionable insights. By aligning operations with software delivery, it enhances readiness, improves MTTR, and drives continuous improvement in reliability and efficiency.

Prepare for the Unexpected with Incident Response Readiness
Plan, prepare, and respond to incidents with confidence. Simulate real-world scenarios through fire drills to test processes, train teams, and evaluate performance. Gain organization-wide readiness ratings, identifying strengths and areas for improvement to ensure your team is always prepared to respond effectively, minimize downtime, and enhance collaboration during critical incidents.
.png)
Empower Developers in Production
Equip developers with integrated tools, actionable insights, and runbooks designed to debug and resolve application issues in production environments.
With native integrations for tools like Slack, MS Teams, and ServiceNow, Harness IR bridges the gap between automation, collaboration, and AI, empowering your team to focus on what matters most—delivering value to your customers.
.png)
Take Part in the Incident Response Revolution
Join the waitlist today and help shape the future of AI-powered incident response with Harness! Check out our website for more information on our key features and capabilities.

All this author’s posts
Tina Huang is the VP of Product and Engineering for AI SRE at Harness, focused on building AI-native incident response and on-call systems. Previously, he founded and served as CTO of Transposit, where they engineered automation and AI-assisted platforms for DevOps and operations teams.

All this author’s posts
Ryan Taylor is the Director of Product for AI-SRE at Harness, with 20 years of experience in ProdOps and SaaS innovation.