
Implementing Git branching in Harness entities like Pipelines and Connectors enables isolated testing and seamless merging, enhancing CI/CD pipeline development and maintenance efficiency. Utilizing MongoDB as a cache and Git webhooks ensures low latency and real-time updates, significantly improving the user experience and operational workflow.
Version control systems have brought in the concepts of tracking file versions, and making changes in isolation by branching, modifying, testing, and then merging to the main branch after approvals and CI checks.

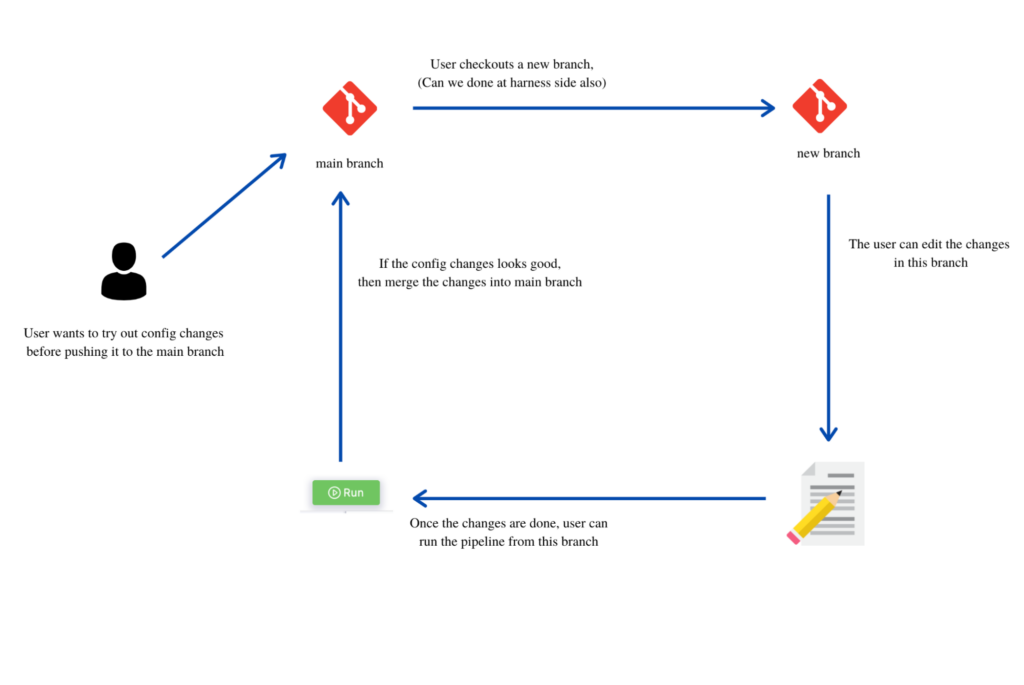
The Git Experience supports the branching concept where we can follow a similar paradigm for Harness entities, such as Pipelines, Connectors, etc. We can fork out from the main branch, make changes without breaking it for others, test it in isolation, and then merge it back to the master branch – just like any other code change.
Requirements
We had the following requirements for Git Branching:
- A rich user experience with a separate section for every entity type.
- Support pagination and advanced filtering of entities.
- Low latency for rendering entities.
- Provide the same experience, even with Git experience disabled.


Challenges and Solutions
To align with these requirements, we had the following challenges:
- Git is a file system-based storage. To retrieve the data from Git every time that someone provides a filter, you would have to scan over all of the files in Git and then parse them to serve the UI request. This would lead to long wait times.
- Even if we keep the state of Git in Harness, it would be a challenge to align the change from Git to Harness.
- Users can continue creating branches with no configuration change, and sometimes they don’t want those to reside in Harness.
MongoDB as a Cache
To optimize, we use Mongo as a cache, parse all of the entities, and keep them in the database. This lets us overcome the performance bottleneck that we would have faced while fetching it from Git.
Git Webhooks
Since all of the Git providers have webhooks for different events on Git, we use them to update our Mongo. Once the Git Experience is enabled, we auto-register the webhook in Git. This results in Harness receiving different kinds of events in Git.
Upon receiving events, we queue them, then asynchronously update our system. For example, when we receive a branch-create event, we update the branch list that we show in the UI. Similarly, when we receive a branch-delete event, we delete that branch from the Harness Mongo cache. Furthermore, when we receive a push-event, we fetch the content of every file in the commit and update the Harness entities.
To optimize the branch and repo filters, we store them along with other data in our entities.
Branch Shortlisting
Any new branch creation in Git wouldn’t always mean a change in the configuration. We offer on-demand sync in case a user wants to sync a specific branch. On triggering a sync, we pull every entity of that branch, parse them, and then store them in Mongo.

User Experience
We have provided a similar user experience as git providers for users who want to add/modify entities from the Harness UI.
User Credentials for Git Operations
To identify the commits that users make to and from Harness, we use the concept of the user profile. Under the user profile, we have a source code manager where the user must provide their personal access token to make any changes to Git. An SCM is useful for auditing the person who is making changes to a Project and its Pipeline, Connectors, etc. This also helps honor the branching rules set in a repo.

Branch Fork and PR Creation
While pushing to Git from the Harness UI, we have provided users with the ability to push to a new branch or to an existing branch, as well as create a PR. This will help users fork branches and get them reviewed before merging. Moreover, this will allow others to continue working on Pipelines from the main branch while the config changes are still under review.

Entity Listing
For users to have a seamless experience in multi-repo scenarios, we list the default branch entities, and then users can filter by repo branch to get the entity. Furthermore, in the case of multiple branches, users can filter on any branch and see all of the entities, as well as apply advanced filters.

Switching Entities Across Branches
To switch seamlessly across branches and compare them, we let users switch branches while in the details section of any entity.


Conclusion
Git Sync and Git Branching promise a lot of potential to modern DevOps solutions. They provide an easy way to make config changes and help developers reduce the overall time to develop, test, and maintain CI/CD pipelines. In particular, branching lets all of the config changes in a branch be tested in isolation before pushing them to production. Moreover, it keeps them from blocking anyone because of incorrect config changes.
Further your reading journey with us! See how we’re doing GitOps at Harness. And if you missed the sister article, Git Sync Experience, feel free to read it now.
This article was written in collaboration with Abhinav Singh, Akash Nagarajan, Rama Tummala, and Deepak Patankar.

All this author’s posts
Abhinav Singh is a Senior Staff Software Engineer at Harness with expertise in DevOps platforms, cloud infrastructure, and developer tooling.