
Harness Chaos Engineering enables teams to create and manage failure scenarios, improving system resilience. It offers extensive chaos experiments, integrates with CI/CD pipelines, and ensures data security, helping organizations prevent costly downtime and enhance reliability.
Today, we launched our latest module in the Harness Software Delivery Platform – Harness Chaos Engineering (CE) – into public preview. Harness Chaos Engineering empowers teams to deliver more resilient systems, helping organizations avoid downtime that can be costly, both financially and in lost reputation.
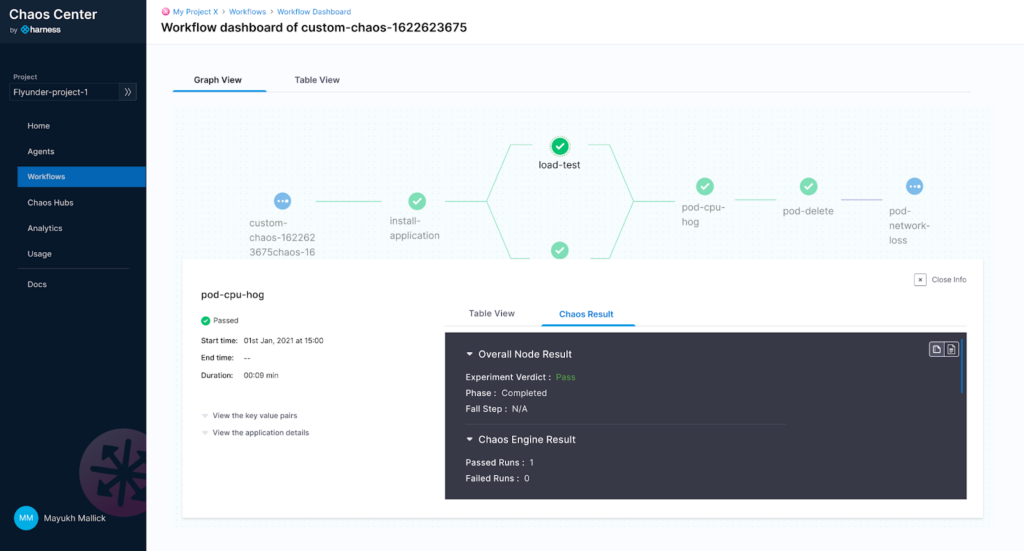
Harness Chaos Engineering enables DevOps and SRE teams to purposely create failure scenarios (“chaos”) to identify potential resiliency and reliability issues in their deployments. These scenarios go beyond traditional unit, integration, and system tests, more closely representing what random failures in a production operating environment would look like. This insight into how your systems behave under defined failure scenarios equips teams to understand weak links that exist in the applications and infrastructure, and proactively create resilience to help prevent costly downtime.

Chaos Engineering – Making Your Systems More Resilient
Some of the systems-level failure scenarios for which Harness Chaos Engineering provides chaos experiments include:
- The ability to validate systems remains available as Kubernetes pods are deleted.
- CPU and Memory hogs at the pod, node, application, and infrastructure levels.
- Injection of network challenges, such as increased latency and network corruptions, and DNS failures.
- Virtual machines in VMware environments can be stopped for a defined time period and then restarted.

The Next Evolution of Chaos Engineering
Chaos Engineering is a concept that is rapidly gaining popularity in software delivery. Harness CE is far more than just another solution to meet the chaos engineering need. Here are a few ways in which Harness is unique in helping companies deliver reliable systems with Chaos Engineering:
- Coverage of as many real-world failure experiments as possible leads to more reliable deployments and therefore less downtime. Harness CE includes – by far – the most experiments available through any provider (48 at the time of publishing), but also the ability for users of Harness CE and the open-source project Litmus to contribute experiments back to the project. This means that you will have access to a continually growing library of different chaos experiments to use to protect against the effects of downtime.
- Creating reliable systems is a team sport. Many teams need information from chaos experiments to help create reliability. To ensure that all involved can get the access and information they need, Harness CE provides integration to CI/CD, GitOps, and integration with your existing observability tools. Other chaos solutions in today’s market aren’t as pipeline-aware or pipeline-integrated as Harness Chaos Engineering, excluding teams outside of SRE that are necessary to help accelerate the effort to make systems more reliable.
- Information about where vulnerabilities exist in systems is highly sensitive information. Harness enables enterprise-grade security and privacy controls of all experiments run, as well as the results of those experiments through support for our self-hosted, on-premises, and air-gapped deployments of CE. Additionally, Harness CE provides support for fully private chaos experiment repos (called ‘Private Chaos Hubs’) to contain both the included experiments you desire to run and those you have created - even the experiments you’re running to fortify your systems can be entirely private.
Getting Started With Harness Chaos Engineering
Harness CE provides the most complete, comprehensive, and inclusive Chaos Engineering solution in the market today to help you avoid systems-level downtime.
To get started or for more information, click here.
Checkout Harness Chaos Engineering

All this author’s posts
Tom Bressie is a proven marketing executive with a deep technology background, having led teams to success in high growth SaaS environments with digital customer acquisition to enterprise software environments acquiring and growing business with fortune 50 multi-national customers.