
Harness leverages its own Continuous Delivery platform to manage deployments, achieving a 94% success rate across 608 deployments, and utilizes machine learning for anomaly detection to prevent regressions from reaching production, demonstrating the platform's effectiveness in real-world scenarios.
The first rule of being a software vendor? “Practice what you preach.” It's a bit hypocritical to expect customers to buy your product if you’re not using it internally to solve the same real-world problems that they are trying to solve. So, Harness uses Harness CD.
We use Harness internally to automate and accelerate how we deliver innovation and features to our customers through our CD-as-a-Service platform (we also ship on-premises software as well). This constant change comes from a tsunami of customer feedback meetings we’ve run to date, including the dozens of beta deployments we’re currently running. Listening to customers is how you build great software.
Failing Is Part and Parcel of Continuous Delivery
Last week we observed more deployment failures than normal, so I thought it would be good to document and share this experience.
Over the past 30 days...
We did a total of 608 deployments (~20/day) across our dev, QA and production environments, with a 94% success rate (36 failures) across 1,800 nodes. Some of our deployments were multi-service deployments, which is why you see 777 total service deployments in the right pane.
You can also see (above and below) that on October 31st we had more deployment failures than normal. The goal of any deployment pipeline is to kill release candidates way before they kill any of your customers in production. Detecting failure is a GOOD thing because it means you’re catching things that shouldn’t be released to production.
If we zoom into October 31st, we can see that our deployments looked like this:

Let's take a look at the first deployment failure relating to the below QA pipeline, which encompasses our Harness application and its three core services: Manager, UI, and Delegate.

You can see that our QA pipeline has 3 parallel stages that deploy our Manager and UI services while verifying their performance and quality. You can see the verification stage on this occasion failed as denoted by the red bar. Let's drill into this stage.

Here is the workflow for the verification stage, and as you can see, the deployment succeeded (phase 1). But shortly after we observed a failure in phase 2:

Identifying Failure Before Your Customers
Our QA workflow has several verification steps that help us verify the performance, quality, and security of our builds--two of which you can see are driven by the integrations with Splunk and ELK. In these verification steps, we’re basically using machine learning to identify abnormal events and exceptions that might relate to the new artifacts in each deployment. We can see that on this occasion the Splunk step is highlighted in red. Let’s drill into that step:
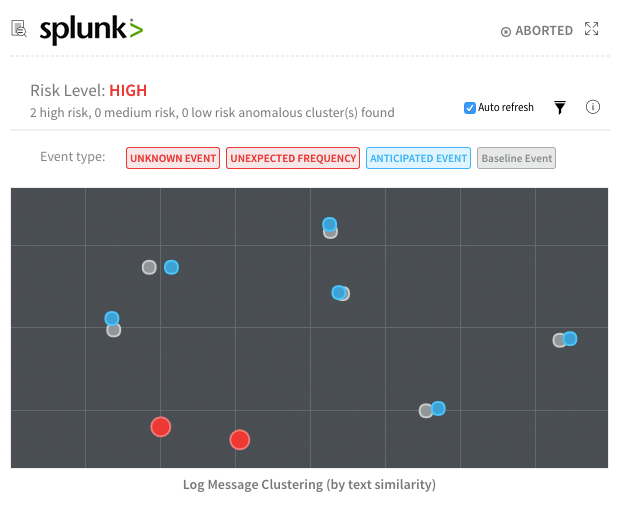
For unstructured event data (logs), we’re using unsupervised machine learning algorithms like KMeans clustering, Jacard and Cosine to understand the relationships and uniqueness of application events. For events that are observed as common, frequent and normal, we treat those as baseline events (grey dots); for unknown events and events with unexpected frequency, we treat these as anomalies (red dots).
As you can see above, our QA pipeline and verification step identified two new anomalies.
Clicking on one of the red dots then shows us the specific event/exception that triggered this anomaly:

As it happens, the Harness application started throwing new NullPointerExceptions relating to our new Encryption service that was actually introduced as part of this build/artifact. As a result, our QA pipeline was abandoned and our developers were able to identify and fix the bug so that this regression never made its way into production.
Had these exceptions not been important, our developers could simply click “ignore” or “dismiss” - and our ML algorithms would ignore similar events in future deployments.
As you can see, testing and verification is critical for any Continuous Delivery pipeline. A good deployment doesn’t just mean your application stays up and running after your artifacts and services go live.
Steve.
@BurtonSays

All this author’s posts
Harness delivers intelligent AI automation, so your team ships code faster, safer, and smarter.