
Harness's Test Intelligence significantly reduces unit test cycle times by 20-60% by selectively running only necessary tests, enabling developers to merge PRs faster without compromising on quality. This innovation was validated through internal testing and open-source projects, showcasing substantial time savings and efficiency gains.
This post was written in collaboration with Uri Scheiner and Shivakumar Ningappa.
In the current day and age, everyone wants to move fast - especially developers. There have been multiple studies done about developers’ efficiency and how to help them move faster, and the most common conclusion is that testing is the biggest bottleneck of the software delivery process, because developers never compromise on quality. They want to make sure that the new code that is being merged is working as expected and the old code that was already working is still working.
After realizing the above, we asked ourselves the following: How do we solve this? How can we help developers move fast without compromising on test quality and coverage?
The solution is Test Intelligence. Test Intelligence is a capability in our CI module that, at runtime, selects the tests that need to be run. Instead of running all the tests, which can take hours, the system selects a subset of tests and skips the rest. It also provides visibility into which tests were selected and why. This doesn’t require any change in the source code, build, or test process as we instrument the byte code on the fly.
Test Intelligence: How Do We Do It?
Initially, we decided to focus on unit tests. Although other types of tests (functional, APIs, UI tests, etc.) might be more time-consuming, therefore the savings are greater, not all dev teams have adopted Continuous Testing (running tests as part of CI/CD pipeline). But since everyone runs unit tests, we started with that. Other types of tests will be supported later.
We built our solution around a model called “Test Graph.” It’s a model that correlates between the class methods and test methods that cover them. By using smart instrumentation, we make sure that the model is always up to date, and that we always sync the model when developers merge code to the main branch.
When a developer opens a pull request and runs unit tests, we use the Test Graph to understand which tests should be executed based on the following metrics:
Changed Code: By querying git, we know exactly which code has changed in the specific build, and we use this data to select all tests that are associated (directly or indirectly) with these changes. These tests become part of the subset of tests that is selected. Assuming the changes are frequent and incremental, the list of tests should not be too long, because it skips the tests that are not needed as no changes were made in the code.
- Changed Tests: Another metric that we use is whether a specific test has changed. When such a change is identified in a test, it is picked even if the code that covers the test didn’t change. This is done to make sure the code is working as expected.
- New Tests: As soon as we identify a new test, we automatically select it. It helps us to make sure it is running successfully, and helps find correlations between the test and new/existing code. This also keeps our Test Graph up to date.
After each test cycle, the user has full visibility into which tests were selected and why (based on the metrics above) and can see the Test Graph of the app.
Cool Story! But Does it Actually Work?
To make sure this approach worked, we tested it on one of our biggest backend repositories called “Portal.”
Before we used Test Intelligence, our unit test cycles were quite long. We had ~16,300 tests running on every PR and it usually took about 5 hours to complete. We were able to run the tests in parallel (5 jobs at a time), and that helped us to reduce it to ~60 minutes. Great improvements, but still - quite a long time to wait for your PR to merge, right?

We saw amazing improvements that even we didn’t anticipate after using Test Intelligence. The graph above shows the time savings between average cycle time without using Test Intelligence, and a cycle time with Test Intelligence (during the evaluation phase, we executed each PR build twice - with and without Test Intelligence, to do the benchmark). Using Test Intelligence, we were able to gain somewhere between 20-60% in savings, which is time that goes back to developers!
It’s important to note that currently, we’re taking a very conservative approach. We are running all the tests whenever we are not certain about the changes in the PR. We are constantly improving our selection model, which will help to increase savings.
Within the Harness CI UI, this is an example of what Test Intelligence shows. On the right, you can see a breakdown of the selection of tests, based on the metrics mentioned earlier:

Harness also provides a full visualization of the Test Graph, so users can see why a specific test was selected.
By clicking on a specific test (the purple node), users can see all the classes and methods covered by this test that were changed in this build (the blue nodes), which led to the selection of that test:

But Wait, There’s More!
To further test the success of Test Intelligence, we wanted to see the savings from common open-source projects. We were able to provide significant savings for each PR cycle on these projects, which further validated our approach. Below were the results that we found:
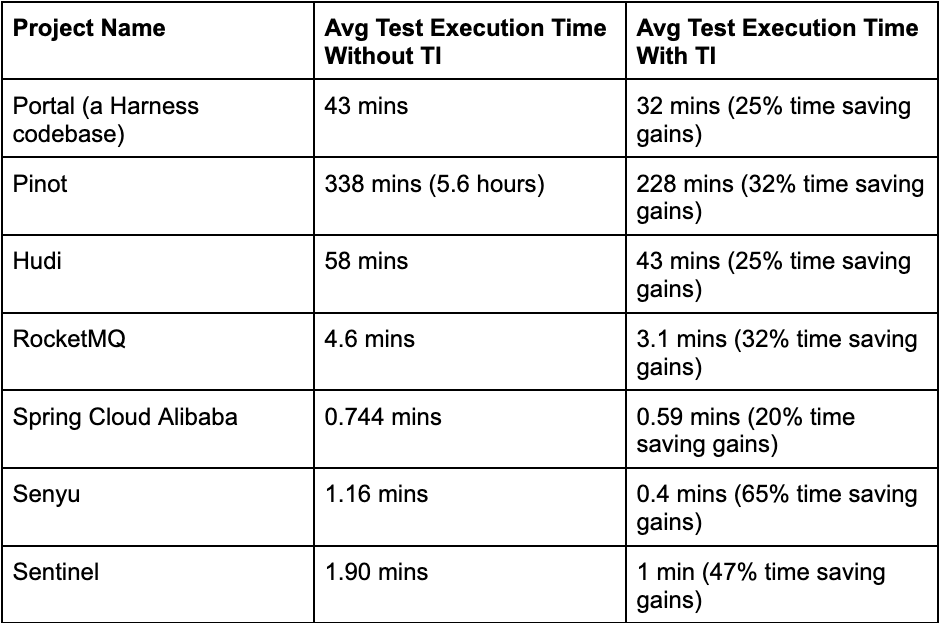
What’s Next
We are currently working on expanding the languages that Test Intelligence supports, as of this blog post, it only supports Java. In addition, we’re designing and doing research on many things - test ordering (to reduce time to the first failure), flaky test detection and mitigation, supporting local builds, and more! We’d love to hear from you on what your challenges are when it comes to testing - and CI/CD bottlenecks in general. Please feel free to send us an email and we can discuss further.
If you are interested in trying Test Intelligence, it is available as part of our CI Enterprise free trial - sign up and give it a spin!

All this author’s posts
Since the Digital Transformation - our lives are completely online - and in order to deliver smooth, uninterrupted services and apps while constantly improving user experience and quality of their offerings - companies MUST adopt Continuous Delivery/Testing solutions