

Chaos fault validation must be safe, predictable, and measurable. High setup friction blocks adoption and slows feedback loops. API-driven execution beats manual YAML workflows. Real-time logs and smart target discovery speed debugging. Dual-phase validation ensures impact and recovery. Strong DX enables faster, scalable chaos testing.
As an enterprise chaos engineering platform vendor, validating chaos faults is not optional — it’s foundational. Every fault we ship must behave predictably, fail safely, and produce measurable impact across real-world environments.
When we began building our end-to-end (E2E) testing framework, we quickly ran into a familiar problem: the barrier to entry was painfully high.
Running even a single test required a long and fragile setup process:
- Installing multiple dependencies by hand
- Configuring a maze of environment variables
- Writing YAML-based chaos experiments manually
- Debugging cryptic validation failures
- Only then… executing the first test
This approach slowed feedback loops, discouraged adoption, and made iterative testing expensive — exactly the opposite of what chaos engineering should enable.
The Solution: A Simplified Chaos Fault Validation Framework
To solve this, we built a comprehensive yet developer-friendly E2E testing framework for chaos fault validation. The goal was simple: reduce setup friction without sacrificing control or correctness.
The result is a framework that offers:
- An API-driven execution model instead of manual YAML wiring
- Real-time log streaming for faster debugging and observability
- Intelligent target discovery to eliminate repetitive configuration
- Dual-phase validation to verify both fault injection and system impact
What previously took 30 minutes (or more) to set up and run can now be executed in under 5 minutes — consistently and at scale.
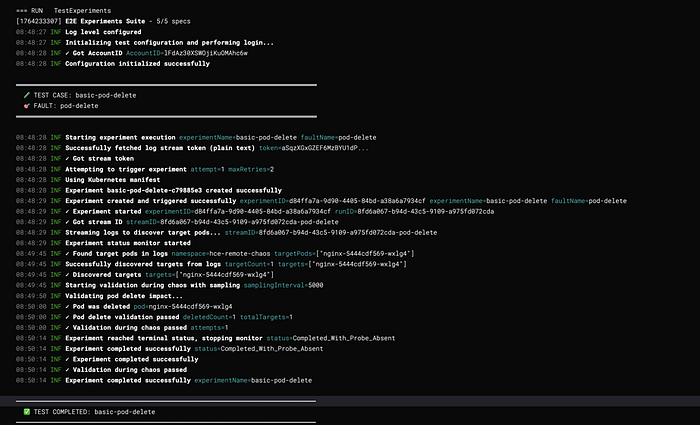
System Architecture
High-Level Architecture

Layer Responsibilities
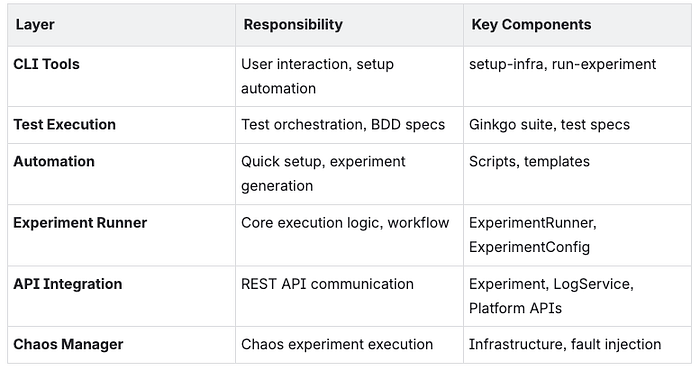
Core Components
1. Experiment Runner
Purpose: Orchestrates the complete chaos experiment lifecycle from creation to validation.
Key Responsibilities:
- Experiment creation with variable substitution
- Log streaming and target discovery
- Concurrent validation management
- Status monitoring and completion detection
- Error handling and retry logic
Architecture Pattern: Template Method + Observer
type ExperimentRunner struct {
identifiers utils.Identifiers
config ExperimentConfig
}
type ExperimentConfig struct {
Name string
FaultName string
ExperimentYAML string
InfraID string
InfraType string
TargetNamespace string
TargetLabel string
TargetKind string
FaultEnv map[string]string
Timeout time.Duration
SkipTargetDiscovery bool
ValidationDuringChaos ValidationFunc
ValidationAfterChaos ValidationFunc
SamplingInterval time.Duration
}Execution Flow:
Run() →
1. getLogToken()
2. triggerExperimentWithRetry()
3. Start experimentMonitor
4. extractStreamID()
5. getTargetsFromLogs()
6. runValidationDuringChaos() [parallel]
7. waitForCompletion()
8. Validate ValidationAfterChaos2. Experiment Monitor
Purpose: Centralized experiment status tracking with publish-subscribe pattern.
Architecture Pattern: Observer Pattern
type experimentMonitor struct {
experimentID string
runResp *experiments.ExperimentRunResponse
identifiers utils.Identifiers
stopChan chan bool
statusChan chan string
subscribers []chan string
}Key Methods:
start(): Begin monitoring (go-routine)subscribe(): Create subscriber channelbroadcast(status): Notify all subscribersstop(): Signal monitoring to stop
Benefits:
- 80% reduction in API calls
- 92% faster failure detection
- Single source of truth
- Easy to add new consumers
3. Validation Framework
Purpose: Dual-phase validation system for concrete chaos impact verification.
ValidationDuringChaos
- Runs in parallel during experiment
- Continuous sampling at configurable intervals
- Stops when validation passes
- Use case: Verify active fault impact
ValidationAfterChaos
- Runs once after experiment completes
- Single execution for final state
- Use case: Verify recovery and cleanup
Function Signature:
type ValidationFunc func(targets []string, namespace string) (bool, error)
// Returns: (passed bool, error)Sample Validation Categories:

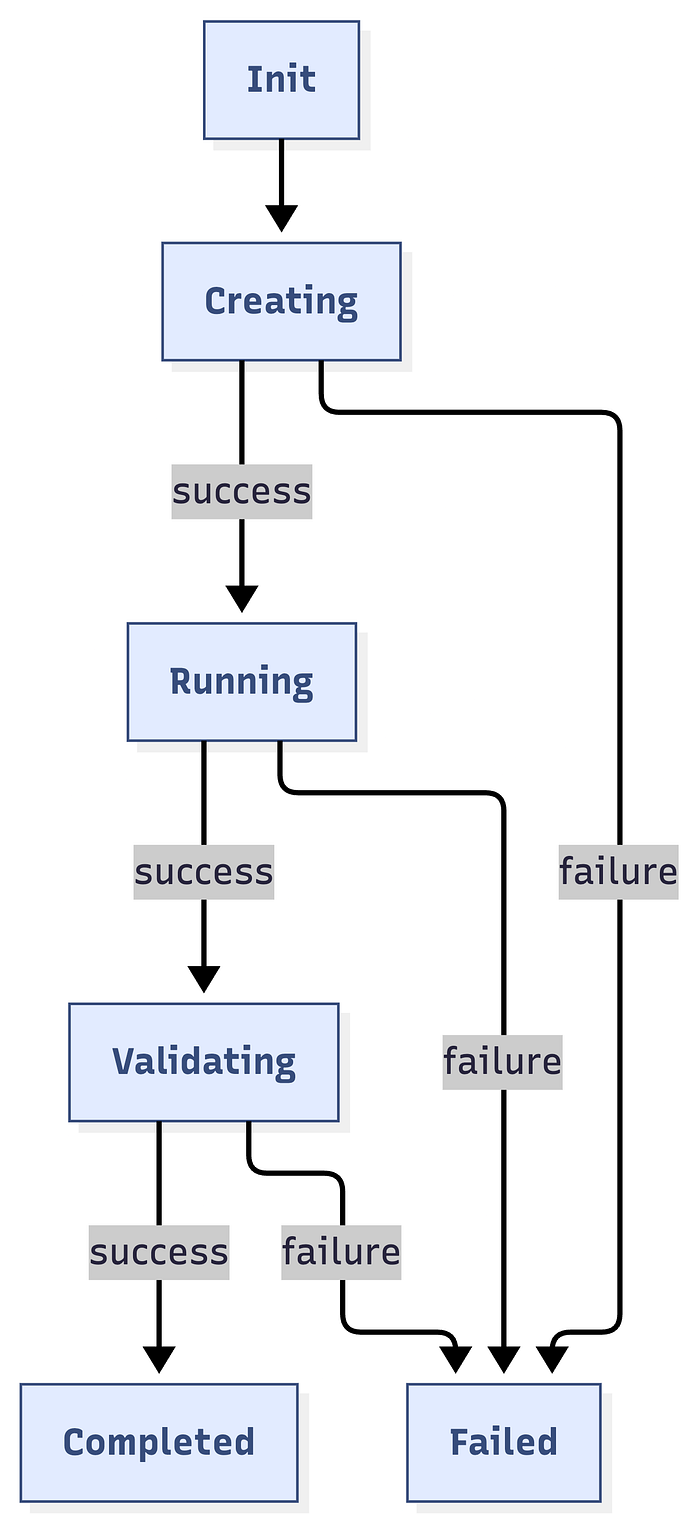
Experiment Execution Engine
Execution Phases
Phase 1: Setup
├─ Load configuration
├─ Authenticate with API
└─ Validate environment
Phase 2: Preparation
├─ Get log stream token
├─ Resolve experiment YAML path
├─ Substitute template variables
└─ Create experiment via API
Phase 3: Execution
├─ Trigger experiment run
├─ Start status monitor
├─ Extract stream ID
└─ Discover targets from logs
Phase 4: Validation (Concurrent)
├─ Validation During Chaos (parallel)
│ ├─ Sample at intervals
│ ├─ Check fault impact
│ └─ Stop when passed/completed
└─ Wait for completion
Phase 5: Post-Validation
├─ Validation After Chaos
├─ Check recovery
└─ Final assertions
Phase 6: Cleanup
├─ Stop monitor
├─ Close channels
└─ Log resultsState Machine
Concurrency Model
Main Thread:
├─ Create experiment
├─ Start monitor goroutine
├─ Start target discovery goroutine
├─ Start validation goroutine [if provided]
└─ Wait for completion
Monitor Goroutine:
├─ Poll status every 5s
├─ Broadcast to subscribers
└─ Stop on terminal status
Target Discovery Goroutine:
├─ Subscribe to monitor
├─ Poll for targets every 5s
├─ Listen for failures
└─ Return when found or failed
Validation Goroutine:
├─ Subscribe to monitor
├─ Run validation at intervals
├─ Listen for completion
└─ Stop when passed or completedAPI Integration Layer
API Client Architecture

Variable Substitution System
Template Format: {{ VARIABLE_NAME }}
Built-in Variables:
INFRA_NAMESPACE // Infrastructure namespace
FAULT_INFRA_ID // Infrastructure ID (without env prefix)
EXPERIMENT_INFRA_ID // Full infrastructure ID (env/infra)
TARGET_WORKLOAD_KIND // deployment, statefulset, daemonset
TARGET_WORKLOAD_NAMESPACE // Target namespace
TARGET_WORKLOAD_NAMES // Specific workload names (or empty)
TARGET_WORKLOAD_LABELS // Label selector
EXPERIMENT_NAME // Experiment name
FAULT_NAME // Fault type
TOTAL_CHAOS_DURATION // Duration in seconds
CHAOS_INTERVAL // Interval between chaos actions
ADDITIONAL_ENV_VARS // Fault-specific environment variablesCustom Variables: Passed via FaultEnv map in ExperimentConfig.
Validation Framework
Architecture
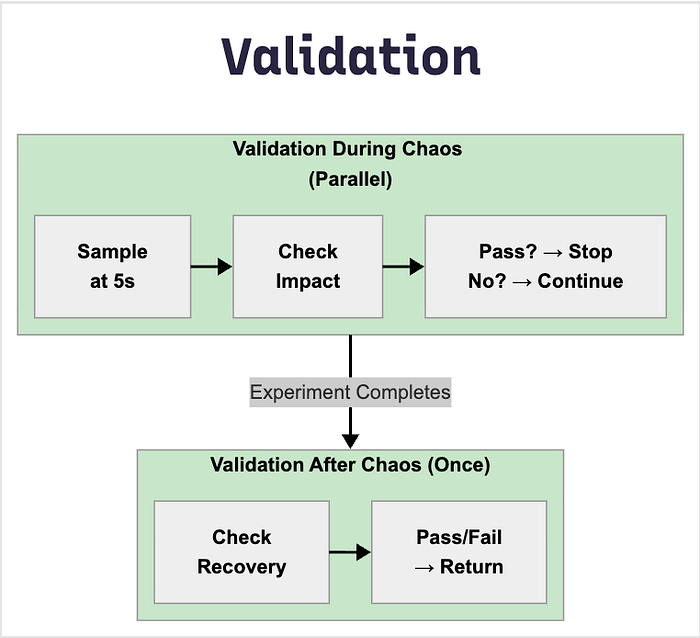
Validation Categories
1. Resource Validators
ValidatePodCPUStress(targets, namespace) (bool, error)
ValidatePodMemoryStress(targets, namespace) (bool, error)
ValidateDiskFill(targets, namespace) (bool, error)
ValidateIOStress(targets, namespace) (bool, error)Detection Logic:
- CPU: Usage > baseline + 30%
- Memory: Usage > baseline + 20%
- Disk: Usage > 80%
- I/O: Read/write operations elevated
2. Network Validators
ValidateNetworkLatency(targets, namespace) (bool, error)
ValidateNetworkLoss(targets, namespace) (bool, error)
ValidateNetworkCorruption(targets, namespace) (bool, error)Detection Methods:
- Ping latency measurements
- Packet loss percentage
- Checksum errors
3. Pod Lifecycle Validators
ValidatePodDelete(targets, namespace) (bool, error)
ValidatePodRestarted(targets, namespace) (bool, error)
ValidatePodsRunning(targets, namespace) (bool, error)Verification:
- Pod age comparison
- Restart count increase
- Ready status check
4. Application Validators
ValidateAPIBlock(targets, namespace) (bool, error)
ValidateAPILatency(targets, namespace) (bool, error)
ValidateAPIStatusCode(targets, namespace) (bool, error)
ValidateFunctionError(targets, namespace) (bool, error)5. Redis Validators
ValidateRedisCacheLimit(targets, namespace) (bool, error)
ValidateRedisCachePenetration(targets, namespace) (bool, error)
ValidateRedisCacheExpire(targets, namespace) (bool, error)Direct Validation: Executes redis-cli INFO in pod, parses metrics
Validation Best Practices

Data Flow & Lifecycle
Complete Experiment Lifecycle
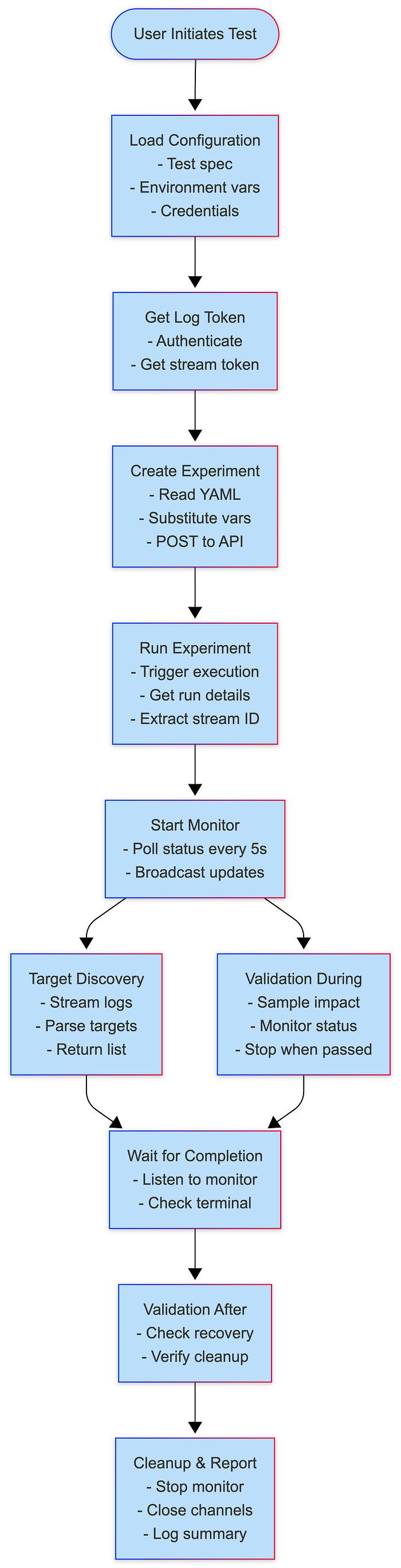
Data Structures Flow
// Input
ExperimentConfig
↓
// API Creation
ExperimentPayload (JSON)
↓
// API Response
ExperimentResponse {ExperimentID, Name}
↓
// Run Request
ExperimentRunRequest {NotifyID}
↓
// Run Response
ExperimentRunResponse {ExperimentRunID, Status, Nodes}
↓
// Log Streaming
StreamToken + StreamID
↓
// Target Discovery
[]string (target pod names)
↓
// Validation
ValidationFunc(targets, namespace) → (bool, error)
↓
// Final Result
Test Pass/Fail with error detailsPerformance & Scalability
Performance Metrics

Concurrent Test Execution
- Each test gets isolated namespace
- Separate experiment instances
- No shared state between tests
- Parallel execution supported
Example Usage of Framework
RunExperiment(ExperimentConfig{
Name: "CPU Stress Test",
FaultName: "pod-cpu-hog",
InfraID: infraID,
ProjectID: projectId,
TargetNamespace: targetNamespace,
TargetLabel: "app=nginx", // Customize based on your test app
TargetKind: "deployment",
FaultEnv: map[string]string{
"CPU_CORES": "1",
"TOTAL_CHAOS_DURATION": "60",
"PODS_AFFECTED_PERC": "100",
"RAMP_TIME": "0",
},
Timeout: timeout,
SamplingInterval: 5 * time.Second, // Check every 5 seconds during chaos
// Verify CPU is stressed during chaos
ValidationDuringChaos: func(targets []string, namespace string) (bool, error) {
clientset, err := faultcommon.GetKubeClient()
if err != nil {
return false, err
}
return validations.ValidatePodCPUStress(clientset, targets, namespace)
},
// Verify pods recovered after chaos
ValidationAfterChaos: func(targets []string, namespace string) (bool,error) {
clientset, err := faultcommon.GetKubeClient()
if err != nil {
return false, err
}
return validations.ValidateTargetAppsHealthy(clientset, targets, namespace)
},
})Knowledge Sharing and Learning
While this framework is proprietary and used internally, we believe in sharing knowledge and best practices. The patterns and approaches we’ve developed can help other teams building similar testing infrastructure:
Key Takeaways for Your Team
Whether you’re building a chaos engineering platform, testing distributed systems, or creating any complex testing infrastructure, these principles apply:
- Measure your baseline — Know how long things take today
- Set ambitious goals — 10x improvements are possible
- Prioritize DX — Developer experience drives adoption
- Automate ruthlessly — Eliminate manual steps
- Share your learnings — Help others avoid the same pitfalls
- Collect user feedback
- Celebrate improvements!
We hope these insights help you build better testing infrastructure for your team!
Questions? Feedback? Ideas? Join Harness community. We’d love to hear about your testing challenges and how you’re solving them!