.png)
Knowledge graphs and RAG (Retrieval-Augmented Generation) are complementary techniques for enhancing large language models with external knowledge, and each brings unique strengths for DevOps use cases. While they are often mentioned together, they are fundamentally different systems, and combining them delivers far better outcomes than relying on either approach alone.
Core Differences
A knowledge graph is a semantic model composed of entities and relationships that reflect how systems, services, code, environments, and people connect. These entities may come from Harness or from third-party DevOps tools. Retrieval from a knowledge graph can be:
- Structured: via graph queries that traverse relationships
- Unstructured: via semantic indexing of graph-connected content
The foundation of the knowledge graph is its semantic layer, which serves as the source of truth for the structure and meaning of the data. This semantic layer defines what an “application,” “pipeline,” “service,” “environment,” “deployment,” or “policy” means - not just how it is stored. This enforces consistent definitions across tools, eliminates ambiguity, and grounds all reasoning in shared meaning.
Because the semantic layer governs how data flows into the graph, it ensures the graph scales cleanly, remains governable, and can incorporate new tools, relationships, and metadata without becoming chaotic.
RAG, by contrast, retrieves unstructured text (documents, runbooks, incident notes, commit messages, architecture diagrams) using embedding similarity and feeds the retrieved content to an LLM. RAG does not model structure or relationships; it retrieves relevant fragments of text.
The fundamental distinction lies in structure:
- A knowledge graph encodes explicit, machine-interpretable relationships.
- RAG retrieves text based on semantic similarity, without understanding how the connections work.
This is why the two approaches excel at different types of problems.
Strengths and Limitations
Knowledge Graph Strengths
Knowledge graphs excel at multi-hop reasoning, where answering a question requires walking multiple relationships — linking a failing service to its owning team, its CI pipeline, the associated environment, and the policies governing that environment.
They offer:
- strong explainability
- traceable reasoning
- lineage and dependency analysis
- organizational context awareness
- consistent governance enforced by the semantic layer
The primary limitation is that a knowledge graph is limited by the data it models.
RAG Strengths
RAG systems shine when working with unstructured information at scale. They are excellent for:
- documentation search
- incident history retrieval
- architecture and API references
- runbook guidance
- open-ended queries
However, RAG struggles with questions that require:
- relationship reasoning
- ownership inference
- dependency mapping
- policy or environment constraints
- multi-step chains of logic
RAG retrieves text. It does not understand structure.
Hybrid Approaches
Modern DevOps AI systems increasingly combine both approaches:
- RAG provides breadth — rich unstructured context.
- The knowledge graph provides depth — structured reasoning and grounding.
- The semantic layer provides stability — consistent meaning and scalable governance.
The result is retrieval and reasoning that are not only relevant but also organized, contextualized, and aligned with the real structure of the software delivery environment.
Why Knowledge Graphs Excel in DevOps
DevOps environments are inherently relationship-heavy: pipelines, services, environments, teams, approvals, policies, artifacts, and dependencies all interact tightly.

A knowledge graph captures these interactions explicitly.
The semantic layer ensures that as systems evolve, definitions remain consistent.
This gives AI agents true organizational context — not just textual familiarity.
With a graph-backed semantic model, agents can reason about:
- ownership
- dependency chains
- deployment pathways
- policy enforcement
- environment behavior
- compliance boundaries
This is essential for generating pipelines, validating changes, automating deployments, and performing impact analysis.
Limitations of RAG for DevOps
RAG is excellent for retrieving documentation, API references, runbooks, and historical incidents. But it cannot reliably infer:
- which team owns a service
- which pipeline deploys that service
- which environments are impacted
- which policies apply
- what dependencies exist and how they cascade
RAG retrieves text; it does not reason across structured relationships.
This limits RAG-only approaches to “chatbots over docs,” which is useful but insufficient for deeper automation.
Hybrid Approaches Emerging
A hybrid system uses both unstructured retrieval (RAG) and structured context (knowledge graph) to produce highly accurate, domain-aware answers. The semantic layer ensures that the graph remains consistent and scalable even as the organization grows.
This combination enables:
- context-aware pipeline generation
- graph-grounded debugging
- multi-step orchestration
- data-driven governance
- safe automation across tools
Knowledge Graphs Benefit More Than AI
Knowledge graphs — and especially the semantic layer behind them — benefit the entire engineering ecosystem, not just AI.
They provide:
- a unified, shared set of definitions across the SDLC
- governance and data quality enforcement
- lineage and dependency mapping
- centralized metadata consistency
- better observability and reporting
- clean integration across tools
AI simply leverages this foundation to become more grounded, less error-prone, and deeply contextual.
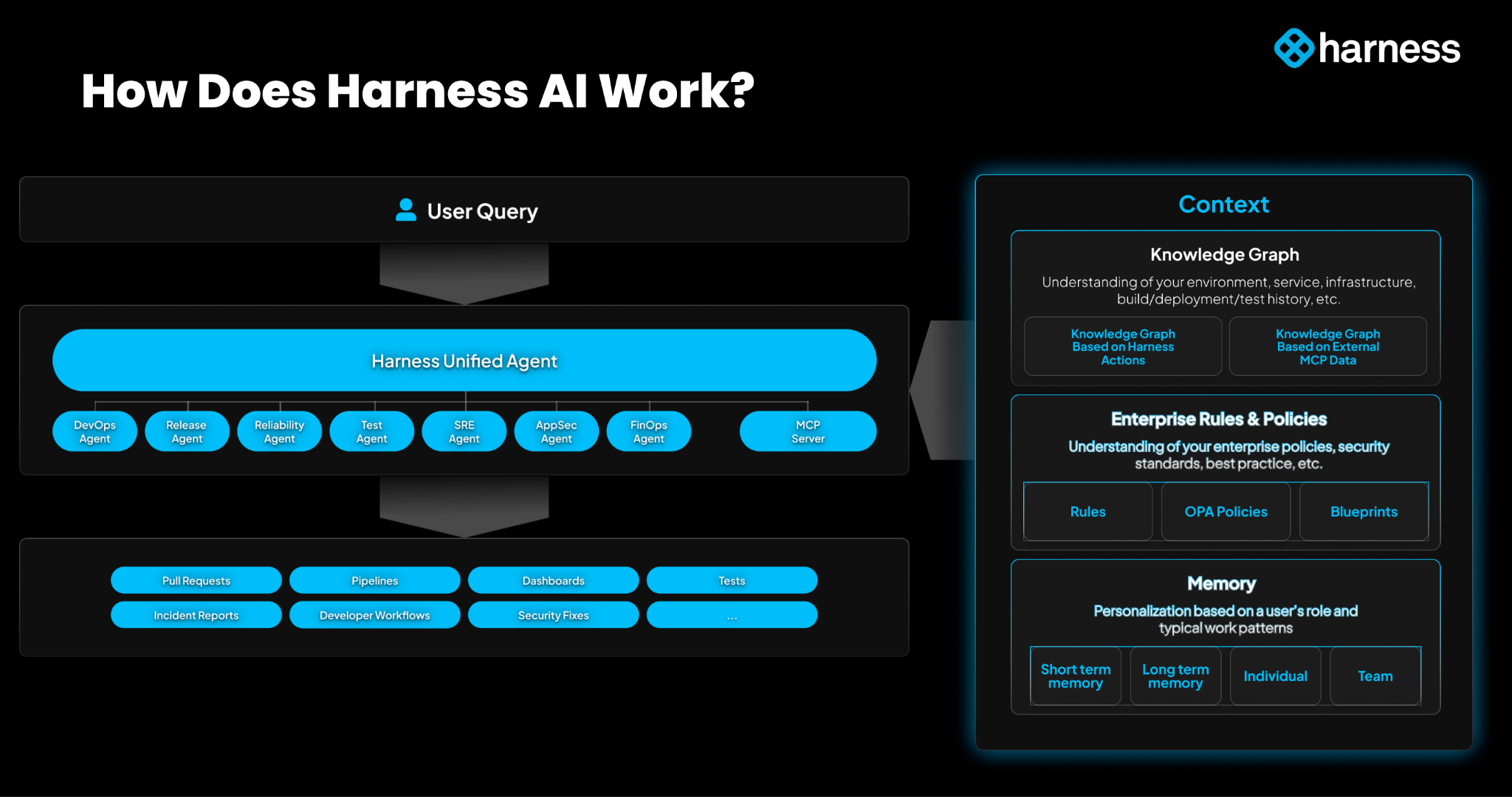
Harness’s Hybrid Implementation
Harness uses a Software Delivery Knowledge Graph built on a semantic model that continuously synchronizes entities and relationships across Harness modules and third-party DevOps tools. The semantic layer defines meaning and ensures structure, while RAG enriches the system with unstructured context.
This enables AI agents to:
- generate pipelines aligned with org standards
- automatically debug issues with traceable reasoning
- execute root-cause analysis across dependencies
- perform safe rollbacks constrained by policies
Results include:
- 85% faster pipeline onboarding
- 7x faster issue resolution
- 50% less debugging time
This is possible because the system blends semantic structure (knowledge graph), meaning (semantic layer), and breadth of context (RAG), producing far more reliable DevOps automation than any single method alone. We'll be writing more about Knowledge Graph in upcoming blog posts.

All this author’s posts
Sunil is an Engineering Architect focused on building production-grade AI and data platforms at scale.