
Implementing automated rollbacks in a Helm deployment pipeline with Harness ensures system reliability by reverting to a previous stable state upon failure, minimizing downtime and maintaining customer trust.
Modern software delivery systems are complicated and vast, and when they fail, they can take down an entire company’s ability to operate. To prevent unforeseen downtime, systems are designed with built-in failure strategies, like rollbacks. A rollback is when the system automatically reverts to a previous, known healthy state. This reversion prevents the system from continuing to function in a broken state and causing further damage.
In this post, we will be using Harness to create a deployment pipeline for a Helm chart. Helm is a package manager for Kubernetes and allows you to flexibly package and deploy your applications in a Kubernetes environment. We will be using Nginx as our Helm chart for this example. We will set up the pipeline so that it runs a Helm deployment and if something goes wrong, the Rollback will kick in and restore the previous version.
Why Do You Need a Failure Strategy?
Organizations have a responsibility to cater to their customers and provide uptime for their products and services. Whether you are a software engineer or work in customer success, the responsibility of delivering a working product lies on your shoulders. Even for the most experienced engineers, it’s impossible to anticipate every scenario and build a robust system that can withstand all possible failures.
Failure strategies are designed to minimize the impact of a failure and keep systems running at all times. A failure strategy should be automated because relying on humans to execute the strategy in a timely manner is not feasible. A human will never be as fast as a computer, and in some cases, it’s not possible for people to intervene in time to prevent a failure from happening. Moreover, it can help build trust and confidence in an organization's ability to manage failure.
What are Rollbacks?
A deployment rollback is the process of undoing a deployment. This can be done for a variety of reasons, like encountering unexpected problems that require a fix with the new deployment or when the original deployment needs to be restored.
For example, think of a software update that breaks something in your production environment. A rollback would be the process of reverting back to the previous version of the software which works as expected.
Setting up a Harness Continuous Deployment Pipeline
A Harness pipeline will contain the following parts:
- Service – Harness Services represent your microservices/apps logically. You can propagate the same Service to as many stages as you need. Learn More about key concepts
- Environment – Environments represent your deployment environments (QA, Prod, etc) and contain Infrastructure Definitions that list your target clusters, hosts, namespaces, etc.
- Execution – Execution is the instructions on how your application and infrastructure are provisioned and managed when required or when there’s a failure.
- Connectors – Connectors help you to connect to your SCMs (GitHub, GitLab, etc.), Secret Managers, Logging tools, Cloud, Ticketing systems and Tracking systems.
This demo will focus on just the Execution part and explore other parts in detail you can read the following post on Getting started with Helm.
Creating a Project
Harness supports a native helm service that you can utilize to use Helm charts in your pipeline. Set up the stage using the Native Helm Service as shown below:
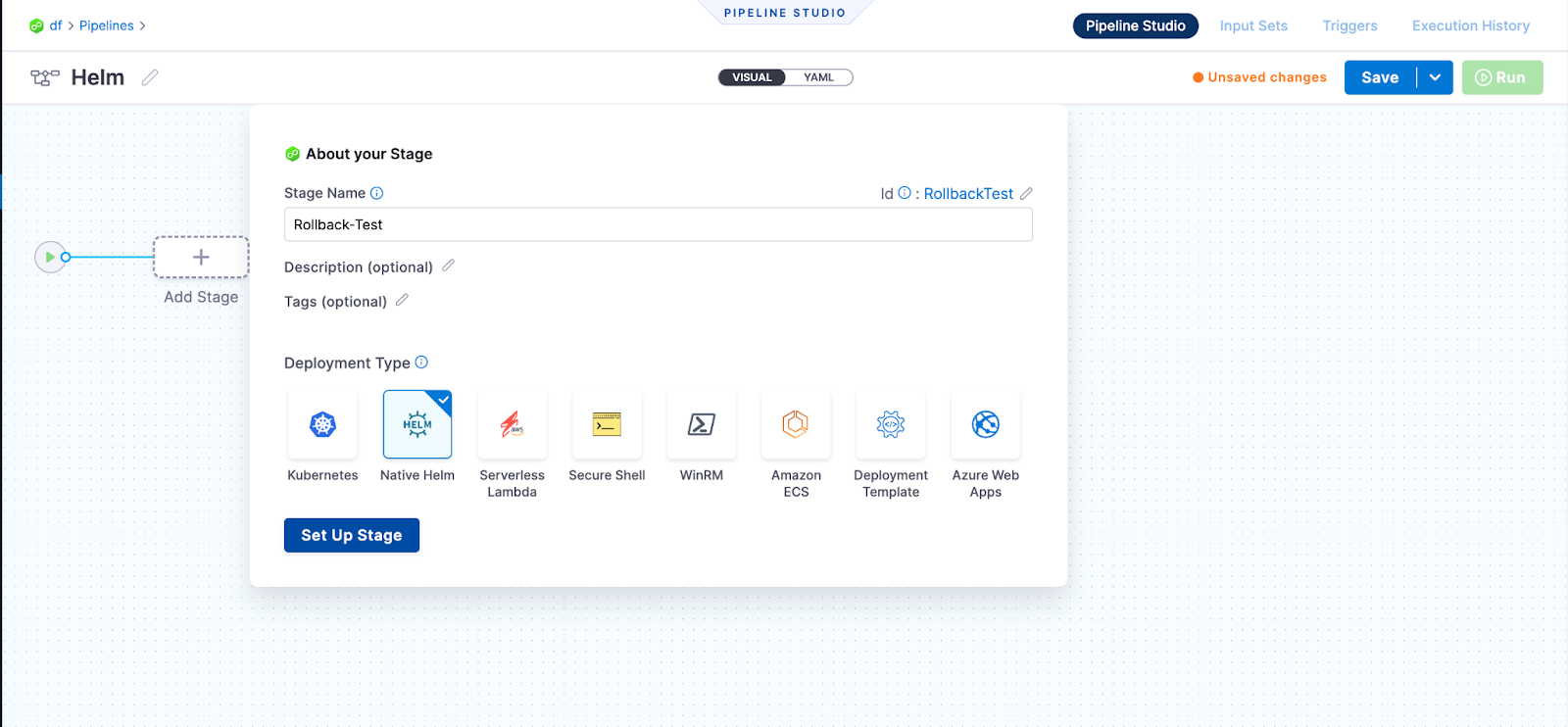
Pipeline Execution
To set up the service, use the following repository after cloning it as you will need to edit the files in the lateral stage.
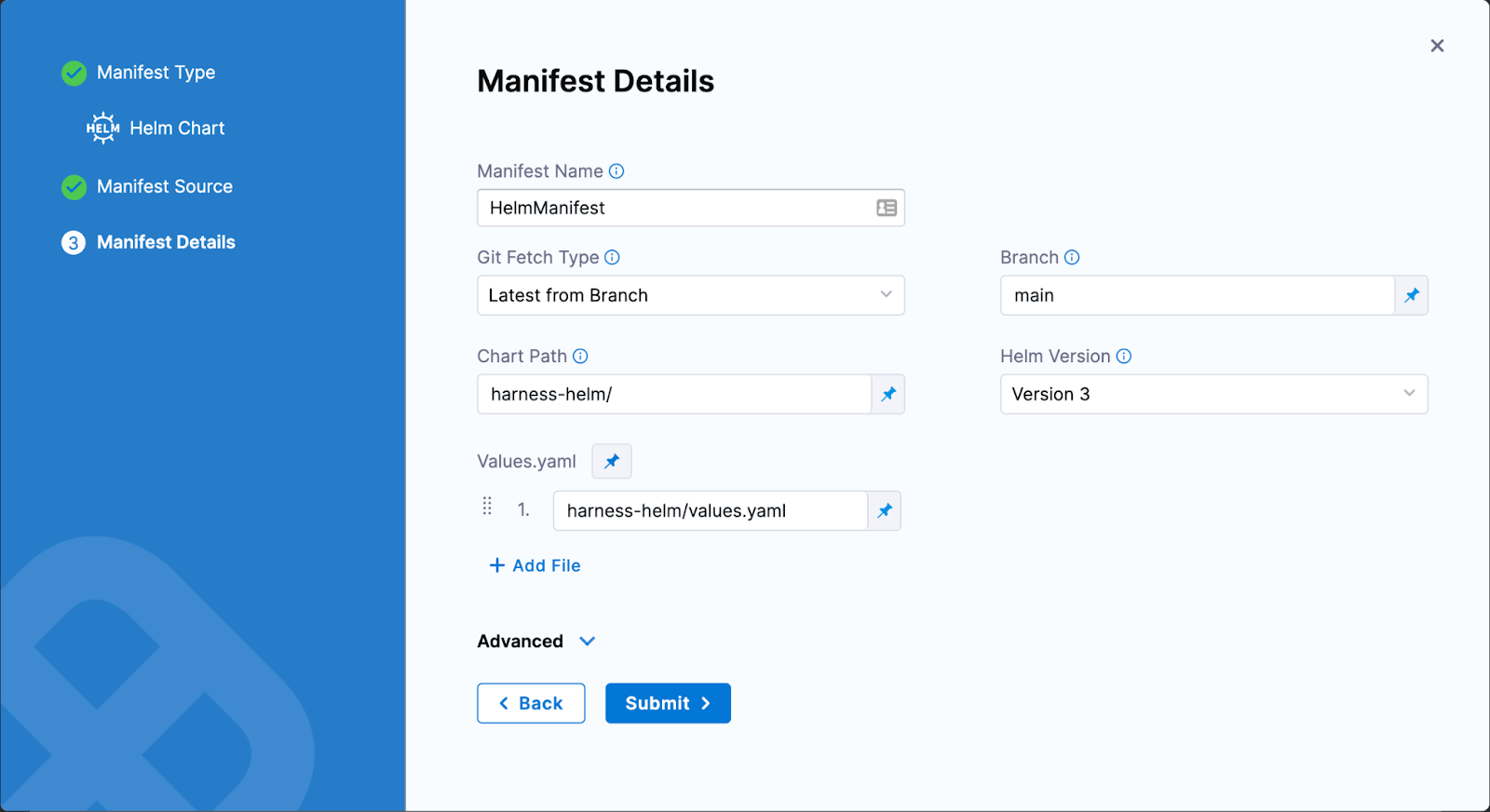
- Manifest Name – Add a name for you to reference your Manifest
- Git Fetch Type – Defines how your Charts will be pulled
- Branch – Defines what branch is your Chart in
- Chart Path – This is the root directory of your chart
- Helm Version – This is Helm’s Version and in this tutorial, you’re using Helm V3
- Values.yaml – Add files that will override your default values
Go to the execution stage and make sure you have the Helm Deployment Configured. Next, save the pipeline to execute.
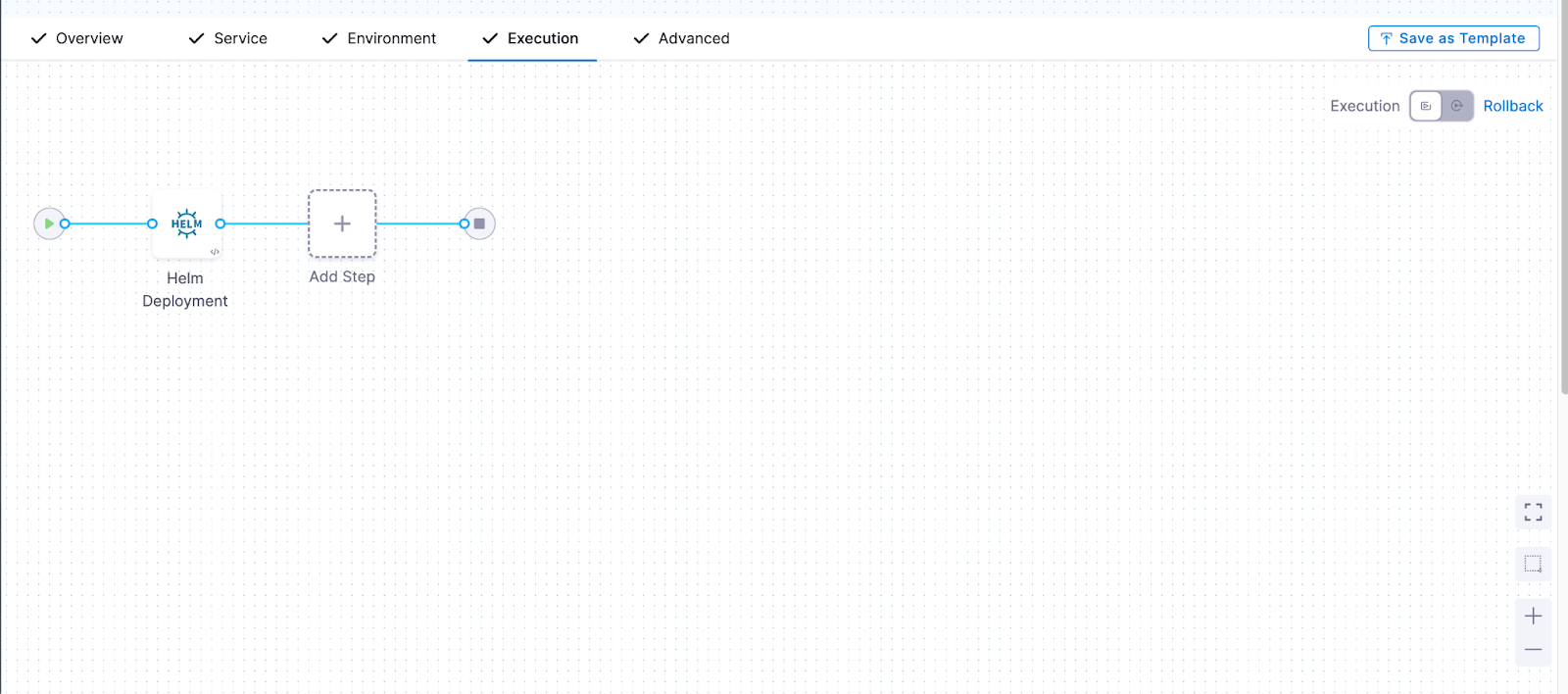
After you run the pipeline, a successful execution looks like this:
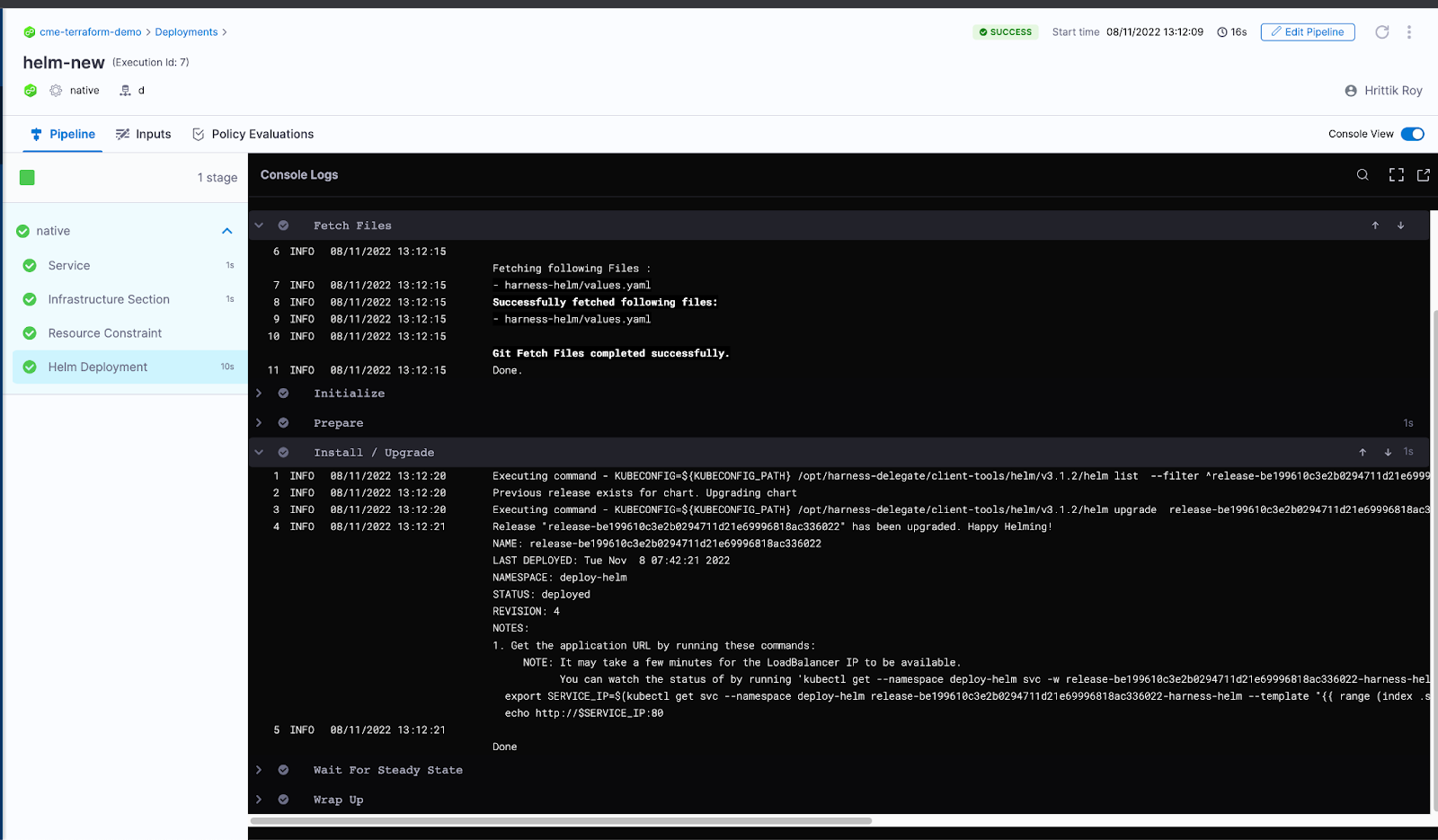
Rollback Execution
Harness offers a rollback strategy. With Helm deployments, you should use a similar rollback strategy. To implement, click on “Rollback” in the top right corner.

Click on add a step and select Helm Rollback from the Step Library.
After the Helm Rollback is added to your step, you’re ready to process the pipeline execution with a failure strategy.
Testing the Failure Strategy
Rollbacks work by moving back to the previous version. For example, if you have one pod and you scale it to two, when a failure is detected it can go back to one pod again. Generally, instead of pods, a new image is used. For simplicity, you can think of pods being used as the visual data to investigate through your terminal.
Open your terminal and use `kubectl get pods –watch` while making sure you’re on the namespace which you have defined in your service.
The next step will be to edit your values.yaml file to make your replica count to two.
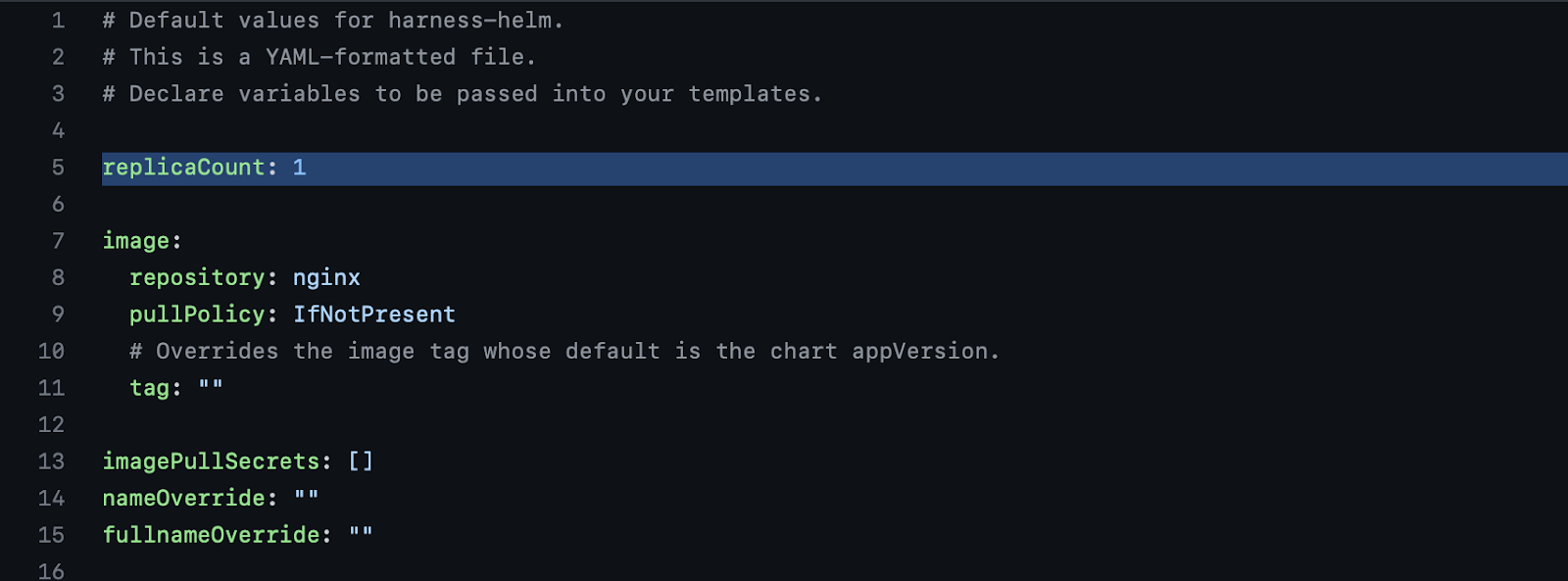
Once you deploy, your cluster will have two pods. We then want to inject a failure so we see the rollback in action.
Inject Failure
Go back to your execution stage and add a step again.
Select the “Shell Script” step.
Configure it with a Script with `exit 1` so there’s a forceful exit. Apply changes.
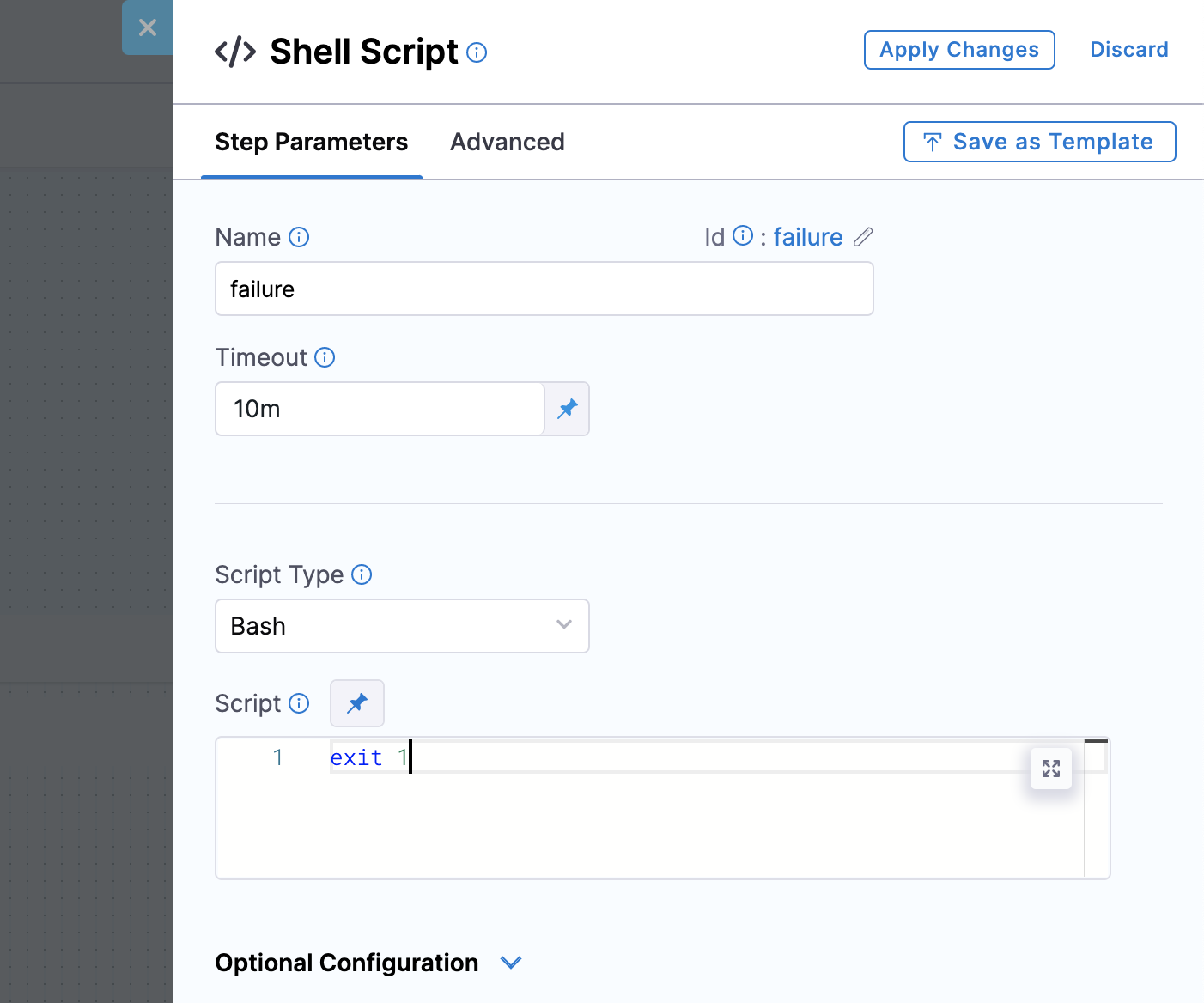
The new steps will look like the following:

Save, run your pipeline, and watch your terminal. You will see your replicas increase to two and then revert back to one as it reaches the exit step. When the exit step fails, then your rollback step triggers.
The execution flow is as follows:
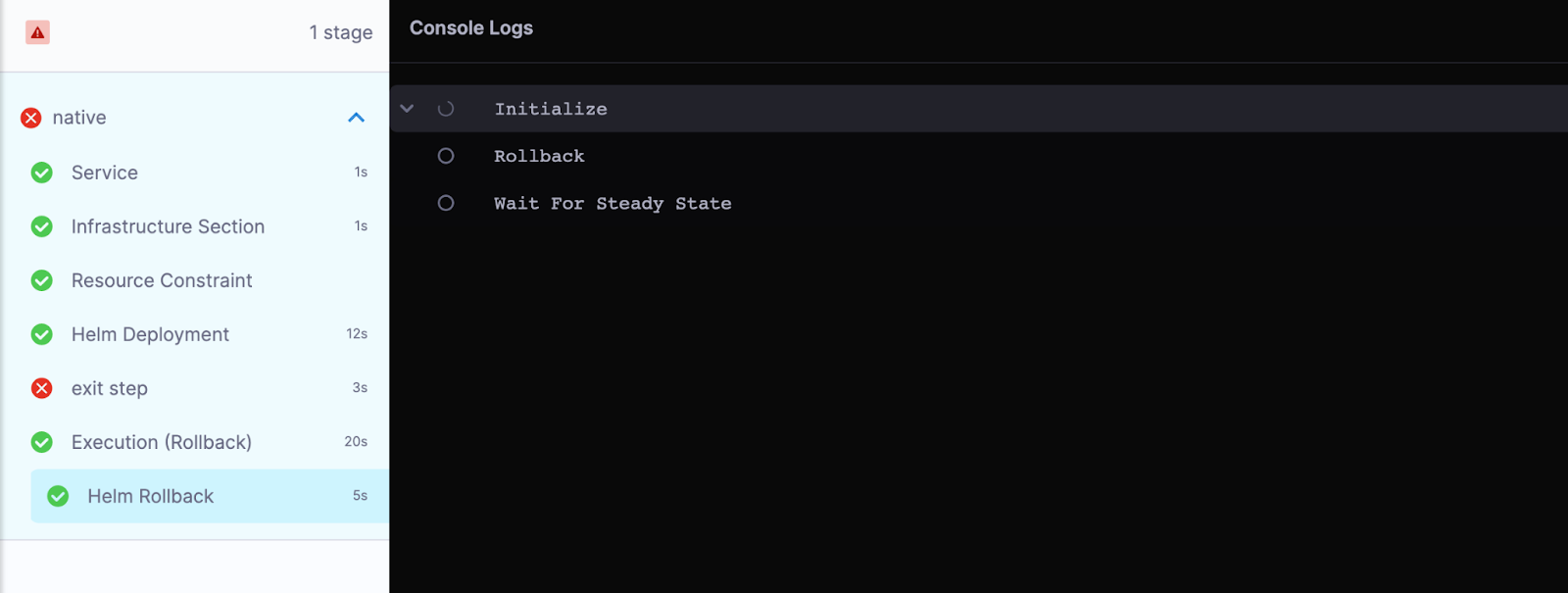
Congratulations! You have successfully implemented rollbacks.
Next Steps
Now that your cluster is operational, you may add resources to it by using the kubectl utility. Check out our Start Deploying in 5 Minutes with a Delegate-first Approach tutorial to install the delegate, and move forward with creating your CI/CD pipeline.
See How Harness Manages Rollbacks
Get started for free with Harness Continuous Delivery.
Feel free to ask questions at community.harness.io or join community slack to chat with our engineers in product-specific channels like:
- #continuous-delivery Get support regarding the CD Module of Harness.
- #continuous-integration Get support regarding the CI Module of Harness.
- # cloud-cost-management Get support regarding the CCM module of Harness

All this author’s posts
Hrittik Roy has worked at various startups, assisting them in scaling their content efforts.