.png)
As AI agents become ubiquitous across the software development lifecycle, engineering teams must do more than adopt new tools; they must redesign how they build, verify, and operate software. This post distills the vision, priorities, and best practices that guide engineering excellence at Harness.
Different products sit at the heart of the Harness platform. As Harness Engineering started leveraging AI coding assistants and agents, a common thread ran across all products: code coverage is too low, operational metrics and dashboards are lacking, and failure mode testing is underutilized. These weren't just technical gaps. They are compounding risks as customer workloads grow in complexity.
Engineering Excellence
Over a period of 4 months, we planned, executed, and continuously improved our engineering processes until we achieved engineering excellence. Here are the core pillars for that process.
Spec-Driven Development
The introduction of agentic IDEs and coding assistants changes how specifications are authored and consumed. A shared Spec Repository, version-controlled in Git-based Harness Code Repository, gives every Harness builder a common library of patterns: resilient API specs, scalable async executors, sweeper/consistency checker blueprints, and latency contracts. Specs become the entry point for every new feature, not an afterthought.
Agent-Driven Workflows & Dynamic UI
As agent-based development becomes common practice, the user experience model shifts. Rather than hard-coded UI flows, agent responses can deliver dynamic UI elements, described through A2UI-type specifications, that adapt to user intent in real time. This accelerates the delivery of new experiences without requiring full frontend release cycles.
Designing for Scale, Resilience & Availability
Every service and agent must be designed with production realities in mind from day one. Key considerations include availability guarantees, multi-tenant fairness, data residency, drift detection, and cost-effective dependency selection. For agents specifically, the guiding principle is simple: do one thing exceptionally well, operate through standard SDKs (Harness base agents, Google ADK, AWS Strands, LangChain), and avoid deep sub-agent meshes that introduce non-determinism and operational complexity.
Success Criteria
- Spec Driven Development is the basis of all feature development, and Agent-driven workflows build UI responses dynamically in the presentation layer.
- Agents implement a feedback/verification loop (e.g., does the code build?)
- All LLM calls pass through a rate limiter with toxicity guardrails.
- Agent prompts are stored independently from application logic.
- Isolated environments for all code builds and execution.
- All agent responses and corrections logged.
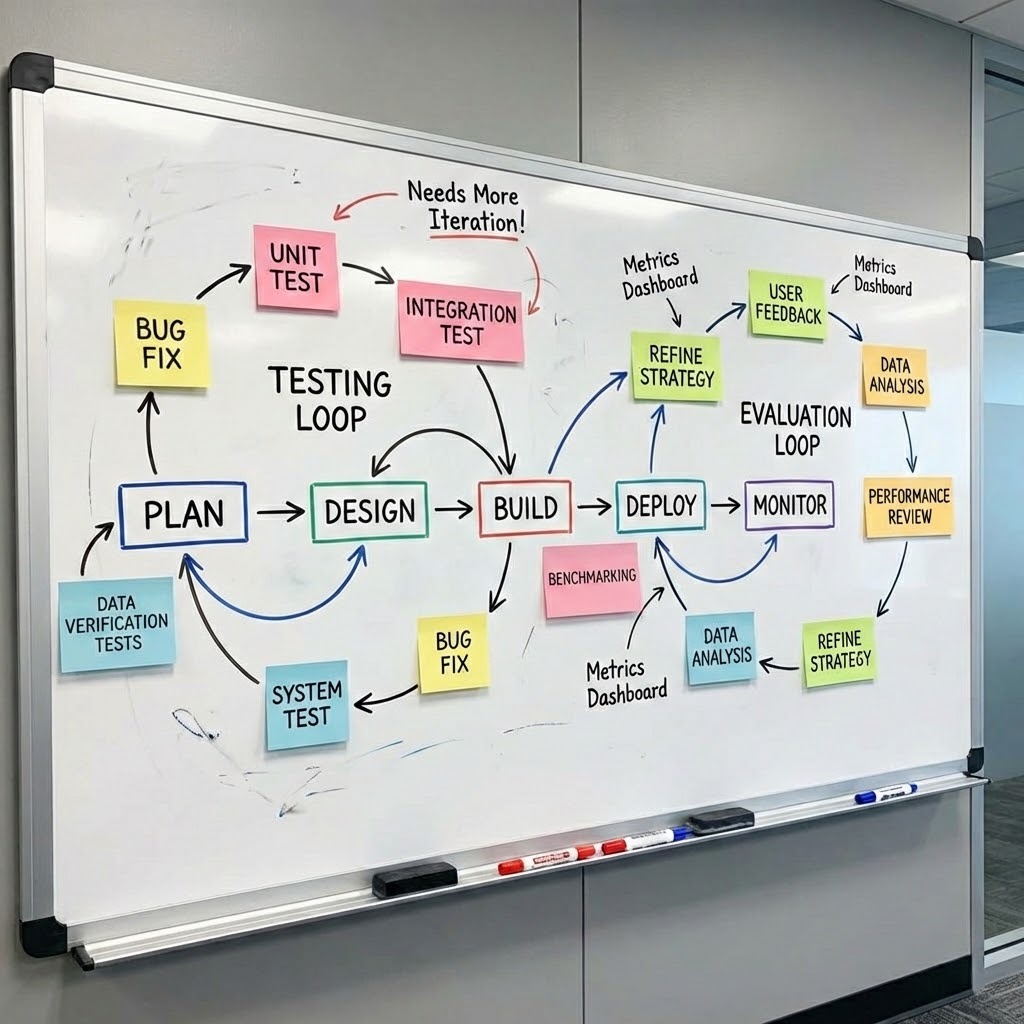
Quality and Verification
Reducing regressions requires a multi-layered testing strategy that spans APIs, agents, and the full product surface. Coverage isn't just about line counts. It's about qualifying the right behaviors at the right level.
Testing Layers
- Data Verification: Output is as good as the input. Our data verification checks cross-check data sources.
- APIs: Unit tests, integration tests, and service sanity checks
- Agents: Critical functional tests and customized workflow checks
- Product level: Key business workflows automated at the API level
- Frontend: Functional verification of both fixed and dynamic UI elements
- Agentic systems: Feedback loop efficacy monitoring as part of baseline evaluations
Operational Excellence
Shifting Ops Left with ORR
One of the most impactful process changes introduced this year is the Operational Readiness Review (ORR). Historically, operational concerns surface too late, after development is complete, forcing expensive rework. The ORR shifts this earlier, introducing review immediately after design reviews. The ORR checklist covers the full operational surface of a feature or product: architecture, dependencies, region build plans, availability, datastores, security (AppSec, GDPR), test coverage, logging, load test results, cost factors, and operational dashboards.
Severity tiers govern post-ORR action items: High items block launch, Medium items must be resolved within 90 days, and Low items enter the long-term backlog.
Operational Reviews
Operational excellence isn't a launch milestone. It's a continuous practice. Taking a page from AWS (where I used to work before joining Harness), Google, and other hyperscalers, our service teams meet weekly to review operational dashboards covering service availability, customer-impacting metrics, data-plane and control-plane health, and ticket trends. At Harness, we run product-level ops reviews and cross-org reviews at VP level. Cross-organization "spin the wheel" Ops Reviews create a mechanism for cross-calibration and shared learning, catching regressions before they become customer incidents and surfacing patterns that inform leadership-level investment decisions.
Engineering for What's Next
The shift to the agentic era isn't just a technology change. It's an engineering culture change. Larger customers, more complex workflows, and AI-powered systems demand higher standards at every layer: how we specify, build, test, and operate. The practices laid out here, from the Spec Repository and ORR process to agent design principles and weekly ops reviews, create the scaffolding for predictable product delivery and operational resilience. These enable Harness to scale to the customers and workloads of tomorrow without losing speed or quality along the way.
Spec-driven development. Agent-ready architecture. Proactive operational excellence. These aren't aspirations. They are the new baseline.

All this author’s posts
Juveria Kanodia is a Senior Director of Software Engineering at Harness, where she leads engineering across the Continuous Integration (CI), Test Intelligence (TI), and Harness Code product areas.