Harness Blog
Featured Blogs

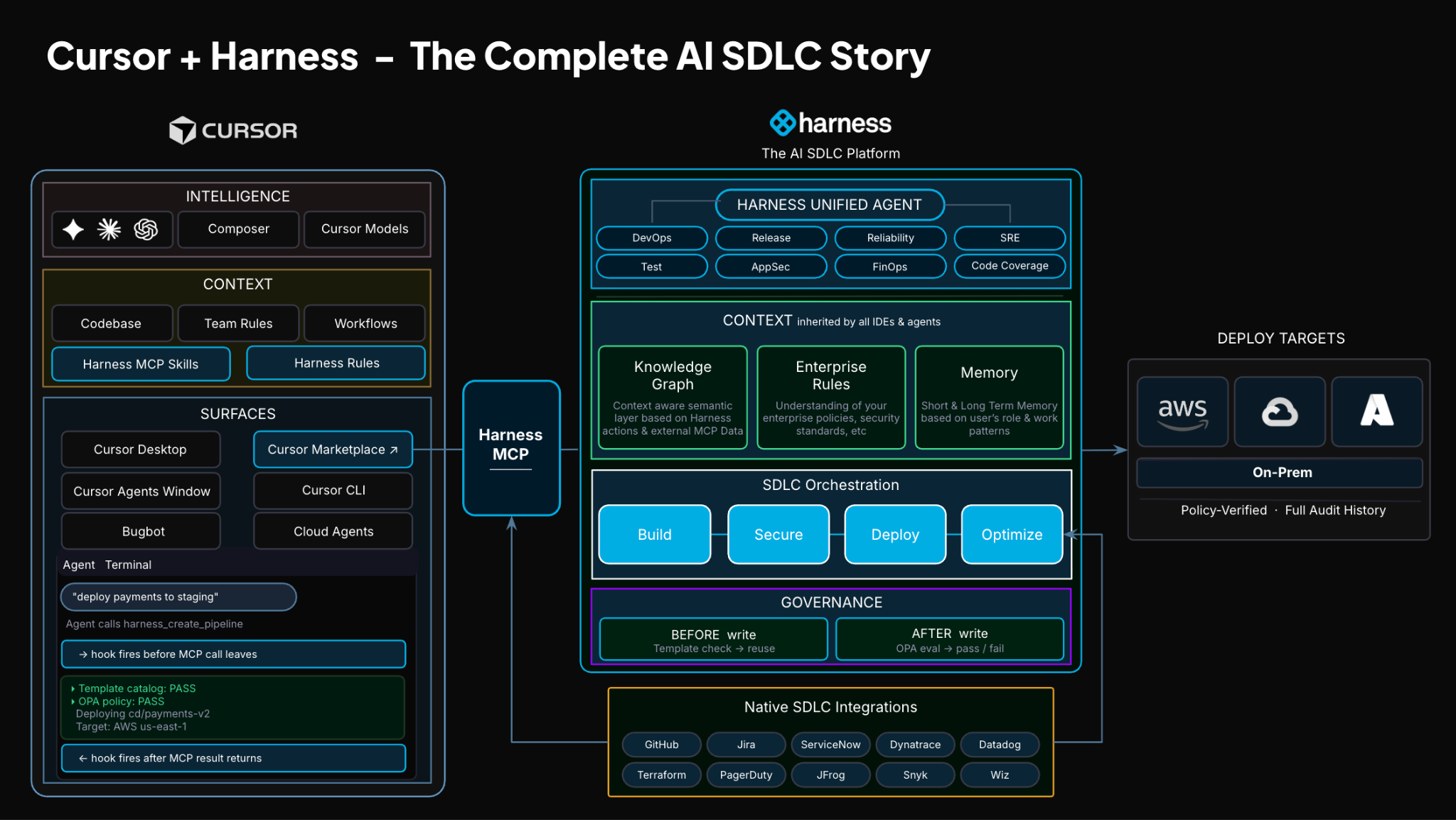
TLDR: Today, Harness is introducing the Harness Cursor Plugin, bringing the power of the Harness AI-native software delivery platform directly into Cursor. This integration, along with the Harness Secure AI Coding hook for Cursor, allows developers and AI agents to move from code changes to vulnerability detection, CI/CD execution, security validation, approvals, deployments, and operational insight without leaving the editor.
AI has completely changed how we write code. You can spin up functions, refactor entire files, and generate tests in seconds. The inner loop, writing and iterating on code, has never been faster. But the moment you try to ship that code, everything slows down. This is what we call the AI Velocity Paradox.
You are suddenly back to juggling pipelines, waiting on approvals, checking security scans, debugging failed runs, and bouncing between tools just to get a change into production.
That gap, between fast code and slow delivery, is what we kept running into. So we built something to fix it.
Today, we are introducing the Harness Plugin for Cursor, a way to go from PR to production without leaving your editor.
AI Made Coding Faster, But Delivery Did Not Catch Up
If you are using agentic coding tools, such as Cursor, you have probably felt this.
You can:
- Generate code instantly
- Understand unfamiliar repos faster
- Fix bugs and open PRs in minutes
But shipping still depends on everything outside your editor:
- CI/CD pipelines
- Security checks
- Approval flows
- Policy enforcement
- Deployment tooling
- Monitoring and debugging
And none of that got simpler just because AI showed up. In fact, AI makes the problem more obvious.
Now you can create changes faster than your delivery process can safely handle. And if those controls are not tight, you are introducing a whole new category of risk. Fast-moving code with fragmented governance.
AI did not break software delivery. It exposed how disconnected it already was.
What If You Could Just Ask
Instead of jumping between tools, what if you could just tell your editor what you want to happen?
Something like:
“Deploy PR #4821 to staging once the security scan passes, and Slack me if anything fails.”
That is the idea behind the Harness Cursor Plugin.
It connects Cursor directly to Harness, so you can trigger and manage your entire delivery workflow using natural language, right inside Cursor.
No tab switching. No manual orchestration. No guessing what is happening in the pipeline.
Some Sample Use Cases
Once connected, you can use Cursor to interact with your delivery system just as you do with your code.
For example, you can:

This builds on what we introduced last month, Secure AI Coding, which integrates directly with Cursor and scans code at the moment of generation rather than waiting for a PR review. Developers see inline vulnerability warnings with the option to send flagged code back to the agent for remediation, without leaving their workflow. Under the hood, it leverages Harness's Code Property Graph (CPG) to trace data flows across the entire codebase, surfacing complex vulnerabilities that simpler linting tools would miss.
The key thing is that you are no longer just interacting with code. You are interacting with the entire delivery system from the same place.
The Important Part: This Is Not Skipping Control
One of the biggest concerns with AI in delivery is obvious:
“Are we about to let agents push code to production without guardrails?”
No.
With Harness, everything runs through the controls that you can rely on:
- Granular RBAC permissions
- OPA policies
- Approval gates
- Audit logs
Instead of being manual checkpoints spread across tools, they are enforced automatically as part of the workflow while you stay in flow.
So AI can help move things faster, but it cannot bypass the governance that matters.
Why We Built It This Way
Most integrations today expose APIs or bolt AI onto existing systems. That is not what we wanted to do.
We designed the Harness Cursor Plugin specifically for how AI agents actually work:
- It is built around actions and workflows, not raw endpoints
- It spans the full delivery lifecycle, not just one step
- It gives agents enough context to reason about what to do next
Because shipping software is not a single action. It is a chain of decisions across CI, CD, security, approvals, and operations. If AI is going to help here, it needs access to that full picture. That’s where the Harness Software Delivery Knowledge Graph comes into play. It provides the necessary context for AI to take actions for you.
The knowledge graph models the relationships between services, pipelines, environments, policies, and operational signals in real time. Instead of treating each step in delivery as an isolated task, it creates a connected system of record that AI can reason over. This allows agents to understand not just what to do, but when and why to do it, based on dependencies, risk signals, and historical behavior.

In practice, this means smarter automation: deployments that adapt to context, approvals that are triggered based on policy and impact, and faster root cause analysis because the system already understands how everything is connected.
This Changes How Ideas Move To Prod
This is not just about convenience. It is a shift in how software actually moves from idea to production.
Instead of:
- Writing code in one place
- Managing delivery somewhere else
- And stitching it all together manually
You get a single, connected workflow:
- Code to pipeline to validation to deployment to operations
All accessible from your editor. Cursor accelerates the building. Harness governs the shipping. And the handoff between the two disappears.
Watch the demo:
Getting Started
If you want to try it:
- Install the Harness Cursor Plugin from the Cursor Marketplace
- Authenticate with Harness using OAuth. No API keys or setup headaches
- Start using natural language to run pipelines, debug issues, and manage deployments
For example:
“Run the CI pipeline for this branch, check if the security scan passed, and promote to staging if it did.”
That is it.
AI is not just changing how we write code. It is changing expectations for how fast we should be able to ship it. But speed without control does not work in real environments. What we are building toward is something simpler:
A world where every step, from PR to production, is:
- Fast
- Governed
- Observable
- Auditable
Without forcing developers to leave their flow. This plugin is one step in that direction.

- Harness IaCM introduces native Terragrunt support, enabling true enterprise-grade orchestration at scale.
- Teams can now manage Terraform, OpenTofu, and Terragrunt in a single platform without fragmented tooling.
- Built-in governance, policy enforcement, and approvals streamline secure infrastructure operations.
- End-to-end visibility and drift detection improve reliability across complex, multi-environment deployments.
- The launch marks a major step toward a unified, multi-IaC control plane for modern infrastructure teams.
Bringing First-Class Terragrunt Support to IaCM
“We’ve been operating in a hybrid environment with both OpenTofu and Terragrunt, and Harness has made it much easier to bring those workflows together into a single, consistent platform with IaCM. The addition of Terragrunt support is a valuable step toward simplifying how we manage infrastructure at scale.”
— Lead Platform Engineer, Enterprise Customer
Infrastructure as Code is now a standard for modern cloud operations, with most enterprises using IaC to provision and manage environments. However, as adoption grows, so does complexity. Teams are no longer managing a handful of environments. They are operating across multiple regions, accounts, and services, often at massive scale.
This is where traditional approaches begin to fall short.
As organizations scale their infrastructure, Terraform alone is often not enough. Teams adopt Terragrunt to manage complex, multi-environment deployments, but they are often forced to stitch together fragmented tooling that lacks visibility, governance, and consistency.
At Harness, we are changing that.
Today, we are excited to announce native Terragrunt support in Harness IaCM, bringing it to full parity with Terraform and OpenTofu while delivering capabilities that go beyond what is available in standalone tooling. This is more than support. It is about making Terragrunt a first-class platform for enterprise infrastructure management.
With Harness IaCM, teams can now:
- Orchestrate complex Terragrunt environments with full visibility across all units
- Apply cost estimation, approvals, and policy enforcement natively
- Detect and manage drift across environments with granular insights
- View infrastructure changes at the resource level across orchestrated deployments
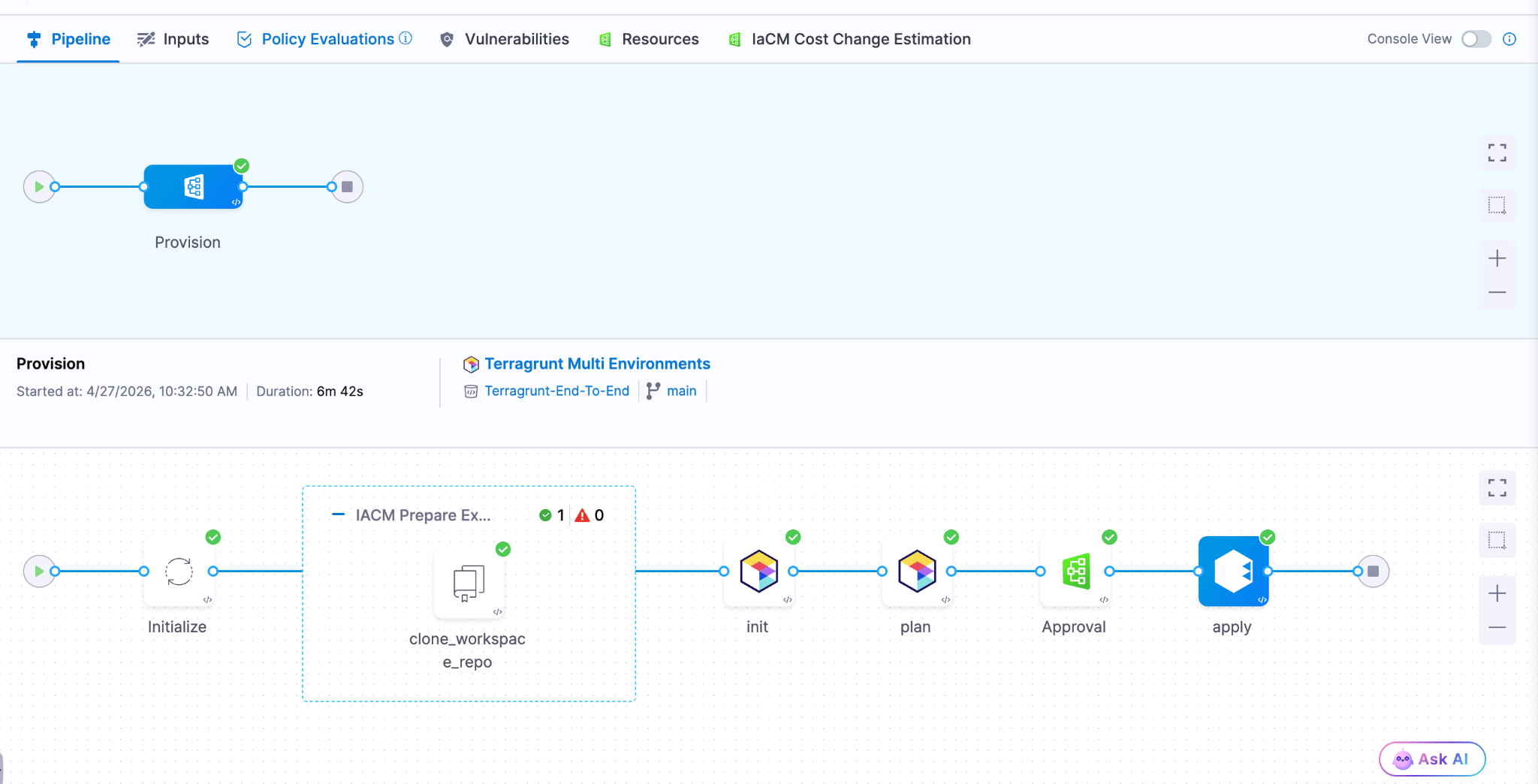
Terragrunt has become a critical layer for managing infrastructure at scale because it simplifies how teams structure and reuse configurations across environments. Harness builds on that foundation with deep, native integration, enabling platform teams to operate with both flexibility and control.
This is especially important for enterprises where a single deployment spans multiple environments and services. Harness abstracts that complexity while maintaining governance, auditability, and consistency.
Extending IaCM to a Multi-IaC Future
Terragrunt is part of a broader shift toward multi-tool infrastructure strategies.
Modern teams are no longer standardized on a single IaC tool. Instead, they operate across:
- Terraform and OpenTofu for provisioning
- Terragrunt for orchestration
- CDK for developer-driven infrastructure
- Ansible for configuration and automation

This creates challenges around consistency, visibility, and governance. Harness IaCM is built for this reality. We are evolving IaCM into a unified control plane for multi-IaC workflows, where teams can manage different frameworks with a consistent experience, shared policies, and centralized visibility.
This means:
- Eliminating fragmented pipelines across tools
- Standardizing governance across environments
- Gaining full visibility into infrastructure state and changes
Instead of managing infrastructure in silos, teams can now operate from a single platform across the entire lifecycle.
What’s Next for Infrastructure as Code?
The next phase of Infrastructure as Code is not just about supporting more tools. It is about making infrastructure systems more intelligent and automated.
We are investing in two key areas:
Expanded IaC Support
We are continuing to support modern frameworks like AWS CDK, enabling developer-centric infrastructure workflows alongside provisioning, configuration, and orchestration tools.
AI-Driven Automation
We are introducing intelligence into IaC workflows to simplify tasks such as drift management and optimization. This helps teams reduce manual effort and operate more efficiently at scale.
Together, these investments move IaCM toward a unified, multi-IaC platform that combines flexibility, governance, and automation. Terragrunt has become essential for managing infrastructure at scale but until now, it hasn’t had a platform that truly supports it. As infrastructure continues to grow in complexity, our focus remains the same. Helping teams move faster, reduce risk, and scale with confidence no matter which IaC tools they use.
.png)
We’ve come a long way in how we build and deliver software. Continuous Integration (CI) is automated, Continuous Delivery (CD) is fast, and teams can ship code quickly and often. But environments are still messy.
Shared staging systems break when too many teams deploy at once, while developers wait on infrastructure changes. Test environments get created and forgotten, but over time, what is running in the cloud stops matching what was written in code.
We have made deployments smooth and reliable, but managing environments still feels manual and unpredictable. That gap has quietly become one of the biggest slowdowns in modern software delivery.
This is the hidden bottleneck in platform engineering, and it's a challenge enterprise teams are actively working to solve.
As Steve Day, Enterprise Technology Executive at National Australia Bank, shared:
“As we’ve scaled our engineering focus, removing friction has been critical to delivering better outcomes for our customers and colleagues. Partnering with Harness has helped us give teams self-service access to environments directly within their workflow, so they can move faster and innovate safely, while still meeting the security and governance expectations of a regulated bank.”
At Harness, Environment Management is a first-class capability inside our Internal Developer Portal. It transforms environments from manual, ticket-driven assets into governed, automated systems that are fully integrated with Harness Continuous Delivery and Infrastructure as Code Management (IaCM).
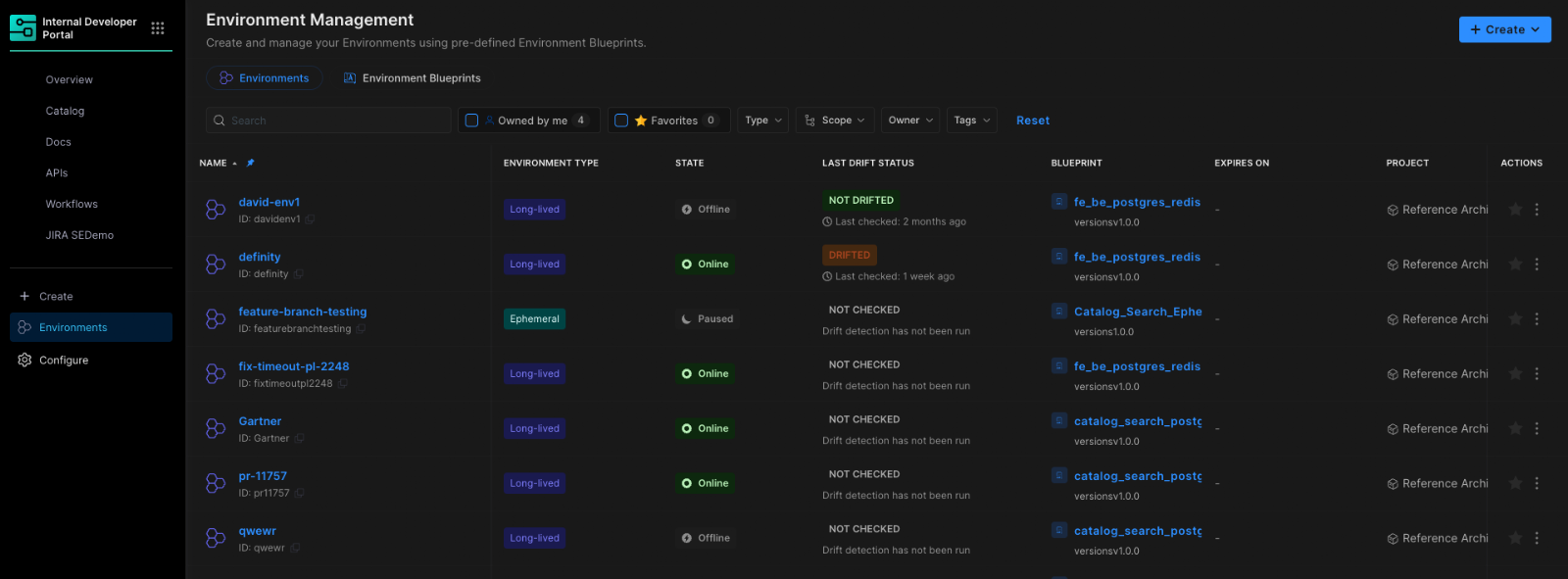
This is not another self-service workflow. It is environment lifecycle management built directly into the delivery platform.
The result is faster delivery, stronger governance, and lower operational overhead without forcing teams to choose between speed and control.
Closing the Gap Between CD and IaC
Continuous Delivery answers how code gets deployed. Infrastructure as Code defines what infrastructure should look like. But the lifecycle of environments has often lived between the two.
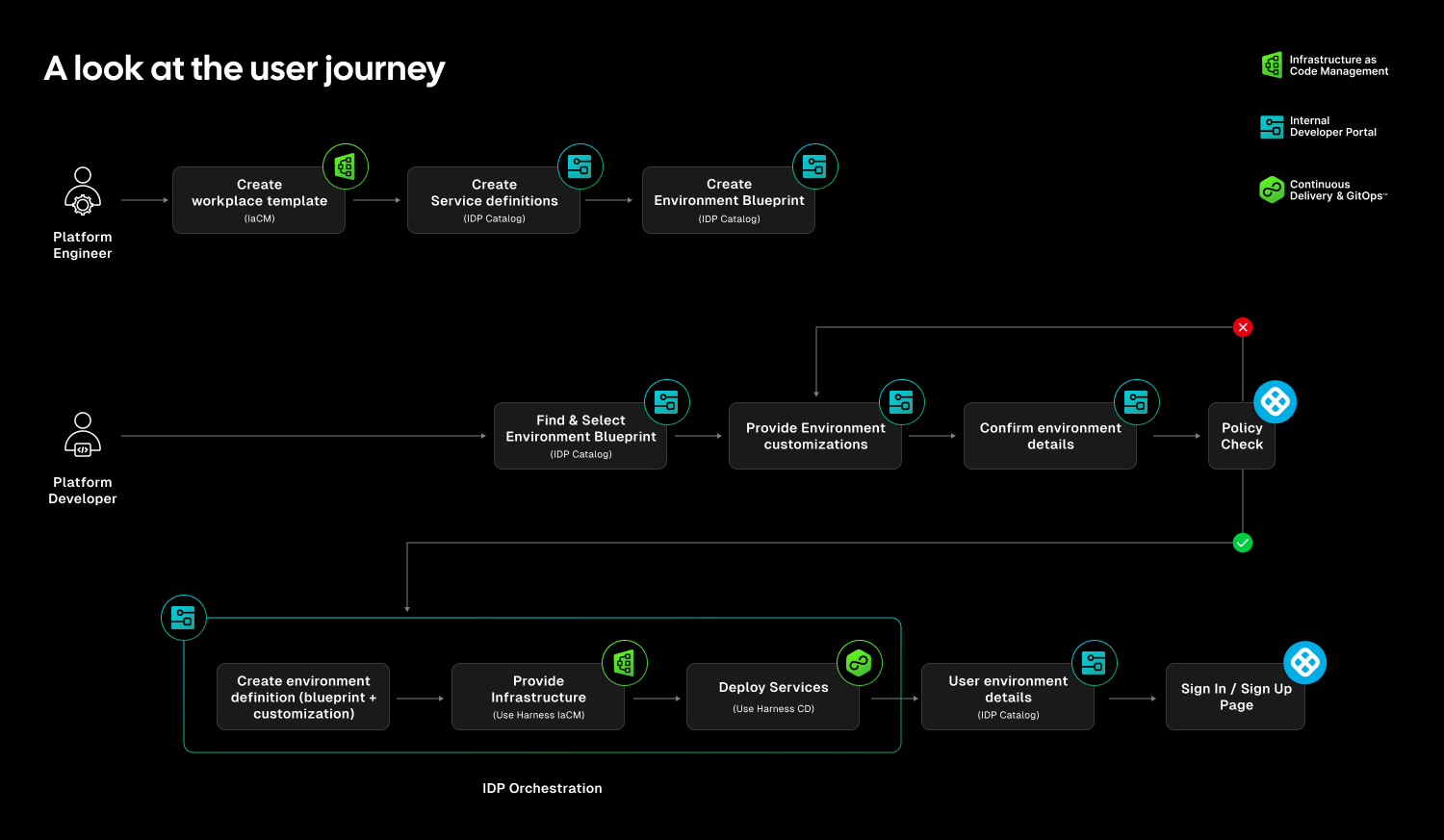
Teams stitch together Terraform projects, custom scripts, ticket queues, and informal processes just to create and update environments. Day two operations such as resizing infrastructure, adding services, or modifying dependencies require manual coordination. Ephemeral environments multiply without cleanup. Drift accumulates unnoticed.
The outcome is familiar: slower innovation, rising cloud spend, and increased operational risk.
Environment Management closes this gap by making environments real entities within the Harness platform. Provisioning, deployment, governance, and visibility now operate within a single control plane.
Harness is the only platform that unifies environment lifecycle management, infrastructure provisioning, and application delivery under one governed system.
Blueprint-Driven by Design
At the center of Environment Management are Environment Blueprints.
Platform teams define reusable, standardized templates that describe exactly what an environment contains. A blueprint includes infrastructure resources, application services, dependencies, and configurable inputs such as versions or replica counts. Role-based access control and versioning are embedded directly into the definition.
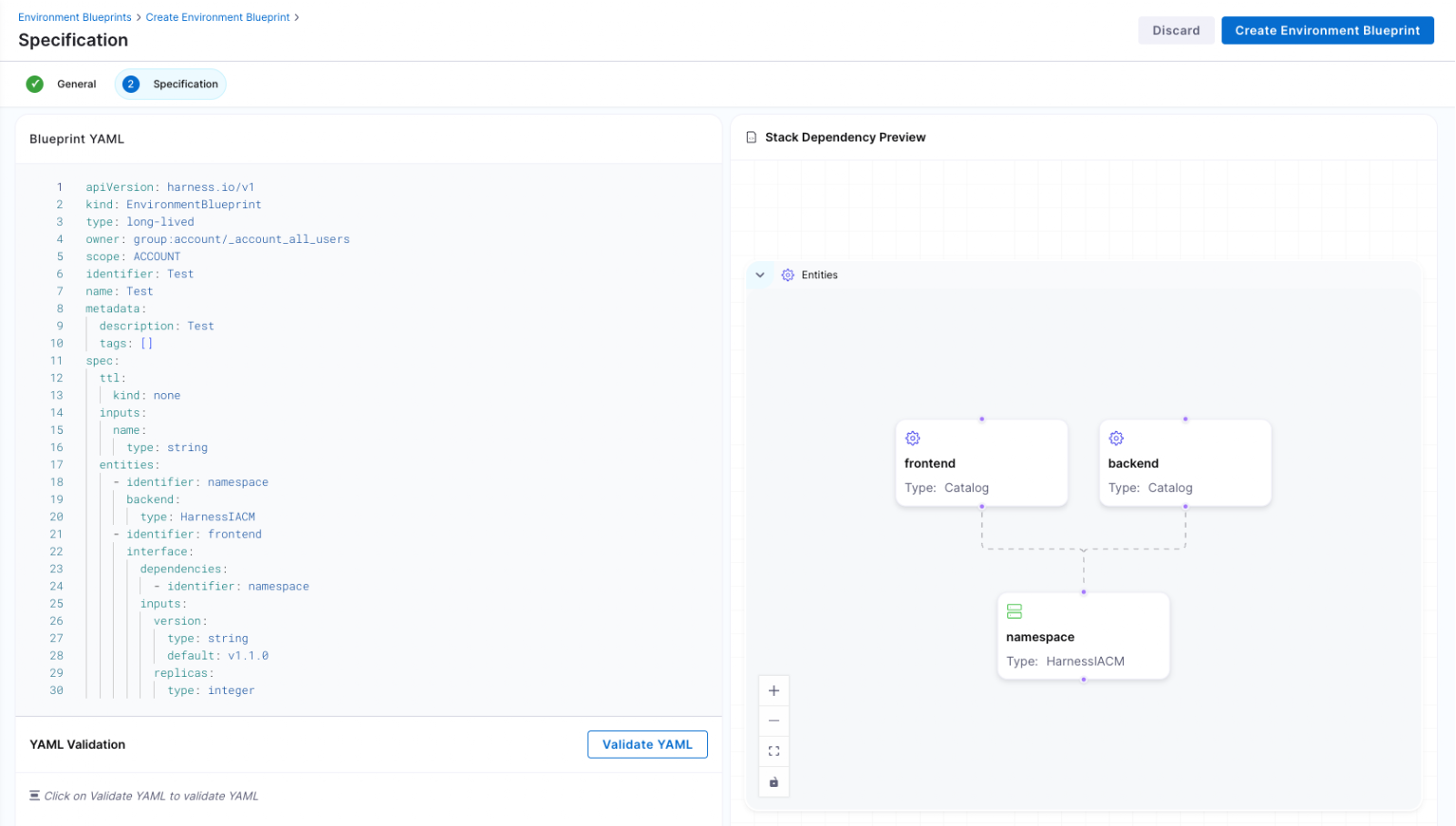
Developers consume these blueprints from the Internal Developer Portal and create production-like environments in minutes. No tickets. No manual stitching between infrastructure and pipelines. No bypassing governance to move faster.
Consistency becomes the default. Governance is built in from the start.
Full Lifecycle Control
Environment Management handles more than initial provisioning.
Infrastructure is provisioned through Harness IaCM. Services are deployed through Harness CD. Updates, modifications, and teardown actions are versioned, auditable, and governed within the same system.
Teams can define time-to-live policies for ephemeral environments so they are automatically destroyed when no longer needed. This reduces environment sprawl and controls cloud costs without slowing experimentation.
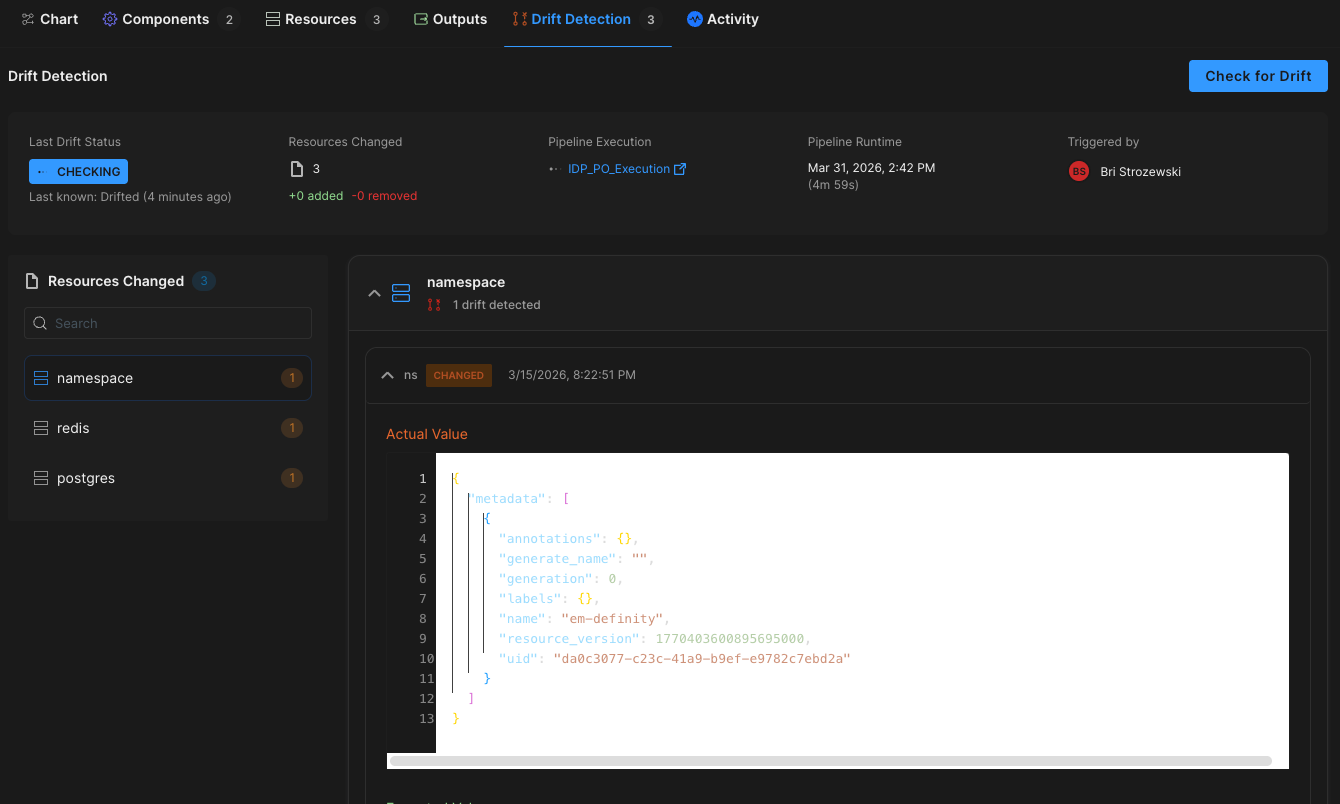
Harness EM also introduces drift detection. As environments evolve, unintended changes can occur outside declared infrastructure definitions. Drift detection provides visibility into differences between the blueprint and the running environment, allowing teams to detect issues early and respond appropriately. In regulated industries, this visibility is essential for auditability and compliance.
Governance Built In
For enterprises operating at scale, self-service without control is not viable.
Environment Management leverages Harness’s existing project and organization hierarchy, role-based access control, and policy framework. Platform teams can control who creates environments, which blueprints are available to which teams, and what approvals are required for changes. Every lifecycle action is captured in an audit trail.
This balance between autonomy and oversight is critical. Environment Management delivers that balance. Developers gain speed and independence, while enterprises maintain the governance they require.
"Our goal is to make environment creation a simple, single action for developers so they don't have to worry about underlying parameters or pipelines. By moving away from spinning up individual services and using standardized blueprints to orchestrate complete, production-like environments, we remove significant manual effort while ensuring teams only have control over the environments they own."
— Dinesh Lakkaraju, Senior Principal Software Engineer, Boomi
From Portal to Platform
Environment Management represents a shift in how internal developer platforms are built.
Instead of focusing solely on discoverability or one-off self-service actions, it brings lifecycle control, cost governance, and compliance directly into the developer workflow.
Developers can create environments confidently. Platform engineers can encode standards once and reuse them everywhere. Engineering leaders gain visibility into cost, drift, and deployment velocity across the organization.
Environment sprawl and ticket-driven provisioning do not have to be the norm. With Environment Management, environments become governed systems, not manual processes. And with CD, IaCM, and IDP working together, Harness is turning environment control into a core platform capability instead of an afterthought.
This is what real environment management should look like.
Latest Blogs

API Security Testing Just Got Easier & Smarter
Application security & engineering teams are under pressure to move faster, cover more, and reduce the operational drag that often comes with security testing. But in practice, two problems keep slowing teams down and adding friction.
- Scan setup is often more complicated than it needs to be. Teams lose time navigating fragmented configuration flows, interpreting unclear fields, and correcting setup mistakes that only surface later. Even when teams know precisely what they want to test, configuring a scan correctly becomes a project of its own.
- Test generation is only valuable when the targets behind it are actually reachable and executable. When APIs are unreachable, improperly mapped, or blocked due to missing authentication, teams end up generating tests that consume runner resources and waste time without producing meaningful results. That creates noise, extends scan times, and makes it harder to focus on other actionable results.
Harness API Testing Enhancements at a Glance
Today, we’re introducing several important enhancements to Harness API Testing that are designed to solve these exact issues and make API scans easier to configure, more reliable, and more efficient.
Improved Configuration Experience
The new scan configuration experience is built to reduce friction from the moment a user clicks “Create Scan.” It simplifies the setup flow, improves validation, and provides users with more guidance directly in context, rather than forcing them to guess or leave the page for help.
The highlights include:
- A simpler, more structured configuration flow - to reduce the cognitive load of stepping through an extensive setup process, the scan creation experience has been consolidated into three clearer sections to help you focus on what matters.
- Field-level guidance everywhere it matters - every configuration field now includes tooltips and helper text, with step-level documentation available alongside the workflow. You get immediate explanations of what each field does and how to configure it correctly.
- Stronger validation early - the new experience focuses on automatic validation to avoid invalid names, incorrect selections, and incomplete inputs before finalizing creation of a scan, which translates to fewer failed setups and less trial-and-error.
- Inline creation for dependent entities - you can now create items such as policies, authentication methods, and runners directly within the scan flow via inline panels, without navigating away in the interface and breaking momentum.
Added API Endpoint Validation
The new reachability validations in XAST Replay and DAST help you confirm whether APIs are actually reachable and properly authenticated, so scan execution stays focused on targets that can produce real results.
The highlights include:
- Dedicated Reachability Test view in scan configuration - each scan now includes a Reachability Test tab that provides a rundown of API endpoint-level readiness before test generation proceeds.
- Detailed endpoint visibility - you can see the full list of API endpoints, service mappings, reachability status, response codes, and response descriptions in one place.
- Downloadable CSV for analysis and troubleshooting - results can be exported for offline review, making it easier for you to share findings, investigate failures, and track patterns across environments.
- Smarter test generation control - helps reduce irrelevant noise by preventing test cases from being generated for APIs that are unreachable or fail authentication.
Why Teams Struggle with API Security Testing
These launches address two persistent sources of friction in API security testing: configuration complexity and execution inefficiency. Both slow teams down, create avoidable rework, and make it harder to get to meaningful security outcomes.
1. Scan setup has been too easy to get wrong
The problem is not just that the setup takes time. It is that the experience in tooling has often lacked enough structure, validation, and in-context explanation.
When configuration is too complex, users are far more likely to:
- Enter incomplete or incorrect settings
- Hesitate because they are unsure what a field requires
- Depend on internal experts or professional services to get a scan configured properly
- Spend more time troubleshooting than actually testing APIs
Security teams have long been dealing with incorrect or incomplete configurations, unclear field usage, and longer times to initially create a successful scan.
2. Weak validation delays necessary feedback
Without strong validation at the point of initial setup, users can move forward thinking a scan is correctly configured, only to discover later that something was malformed, missing, or misunderstood.
That creates a chain reaction:
- Errors are caught after setup instead of during setup
- Users have to backtrack and redo work
- Confidence in the scan creation process drops
- Time-to-value gets stretched unnecessarily
Without validations, helper text, tooltips, and field-specific guidance, it’s easy to make mistakes when entering wrong inputs and making selections.
3. Fragmented workflows break momentum
Context switching creates another major issue. If users need to leave the scan flow to create a policy, configure authentication, or add a runner, the API test setup experience becomes fragmented.
That fragmentation leads to:
- Slower scan creation
- More abandoned or half-finished workflows
- Higher odds of misconfiguration
- Less intuitive user experience
Teams often waste time bouncing between multiple pages and increase the likelihood of mistakes without inline workflows.
4. Test generation doesn’t equate to execution readiness
On the execution end of the equation, teams may encounter cases where tests are generated even when the target APIs are unreachable or not properly authenticated.
That leads to several downstream problems:
- Unnecessary test generation
- Wasted runner resources
- More noise in scan output
- Longer scan times
When API endpoint targets aren’t validated upfront, the result is unnecessary test generation and low-quality output.
5. High activity does not always mean high value
Large numbers of generated tests can look impressive on release dashboards, but if those tests are tied to unreachable APIs, they fail to create real security value.
Teams are left with:
- Inflated scan activity metrics
- Less trust in reported results
- Wasted time separating signal from noise
- Reduced confidence around coverage
Improper scan configurations that produce high volumes of poor results yield inaccurate metrics that are critical to application security programs. This reality can create a false sense of confidence in security posture.
A Closer Look at What’s New in Harness API Testing
These enhancements improve two critical parts of the API testing experience: how scans are configured and how test execution readiness is validated.
Scan Configuration Revamp & Validation Enhancement
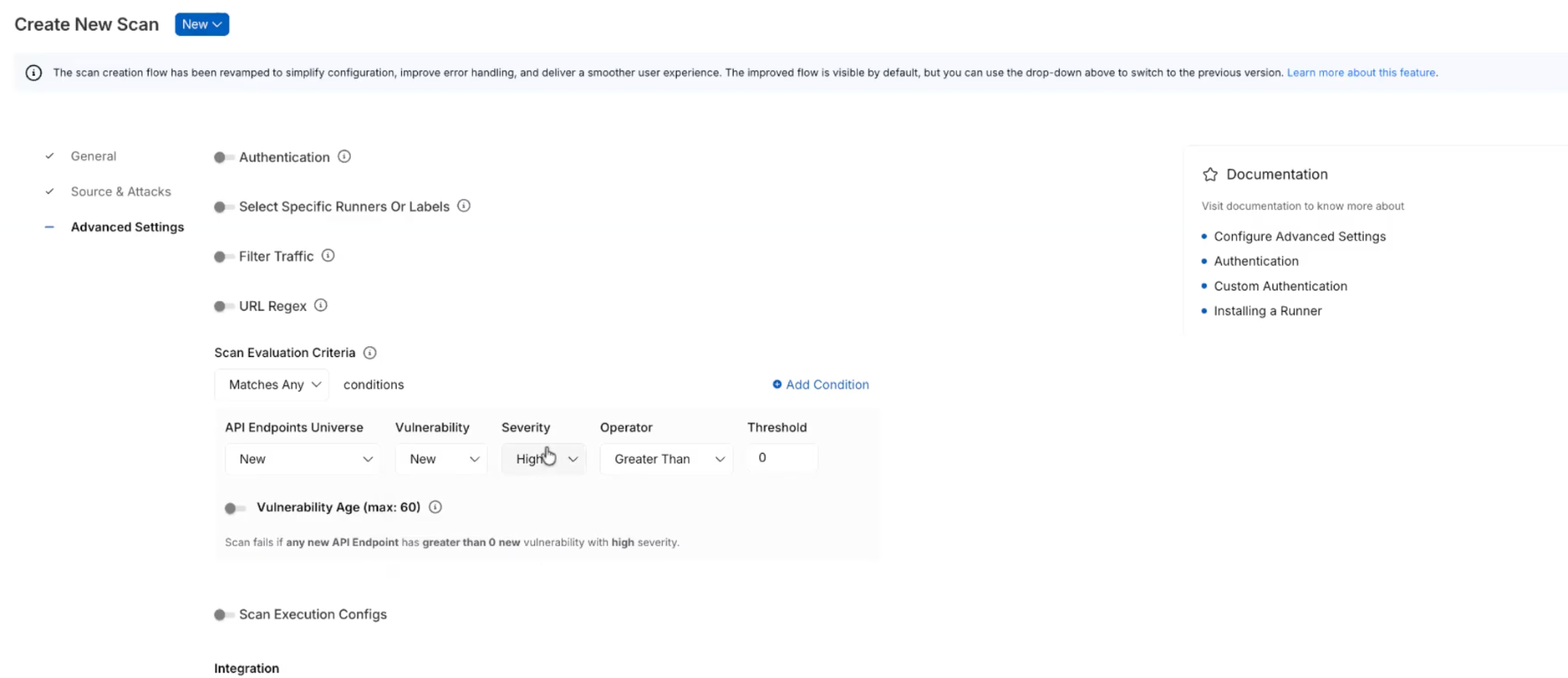
Rather than spreading configuration across a larger set of steps, the new flow reduces the experience to three main sections that are:
- General - define the basics, such as scan name, environment, frequency, and incremental scan behavior.
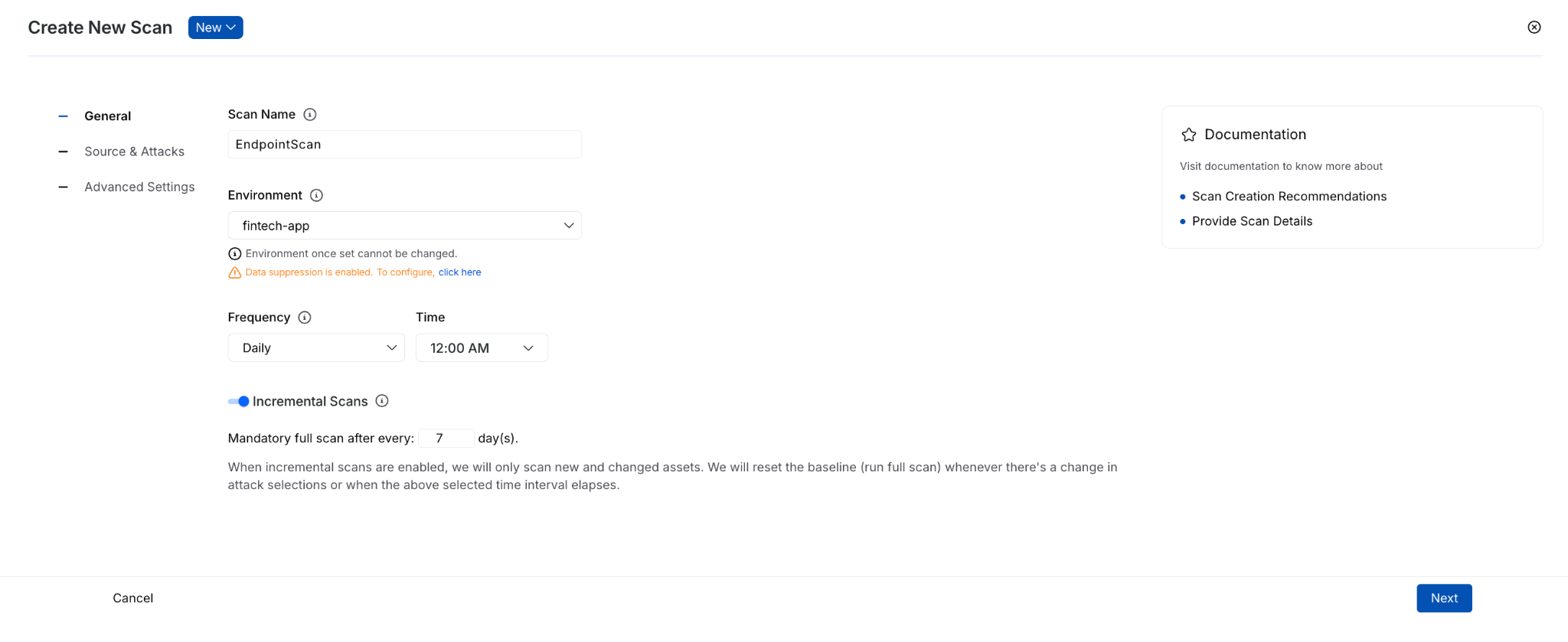
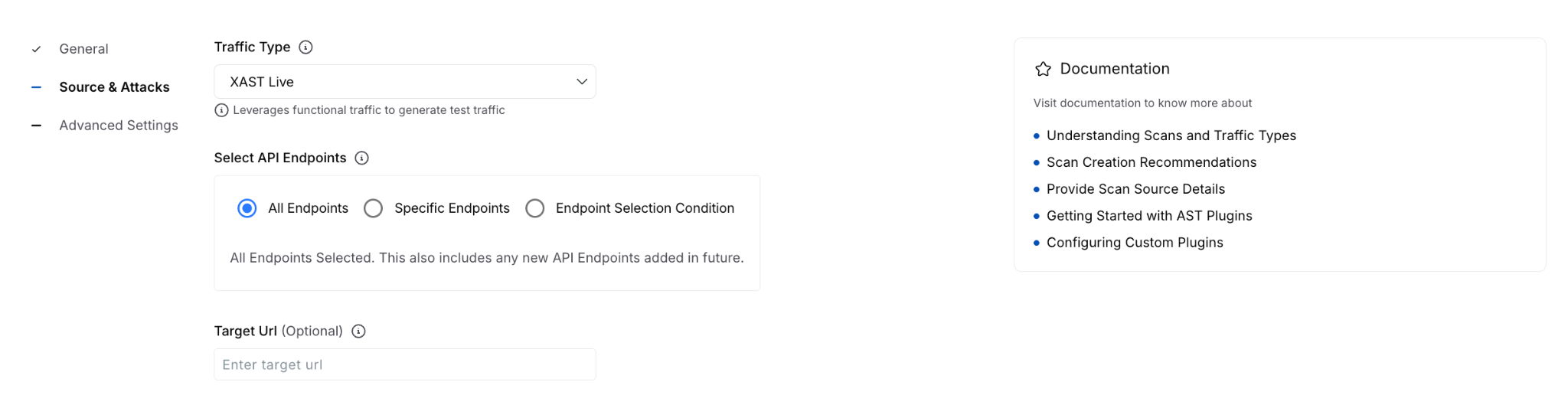
- Source & Attacks - select traffic and policy.
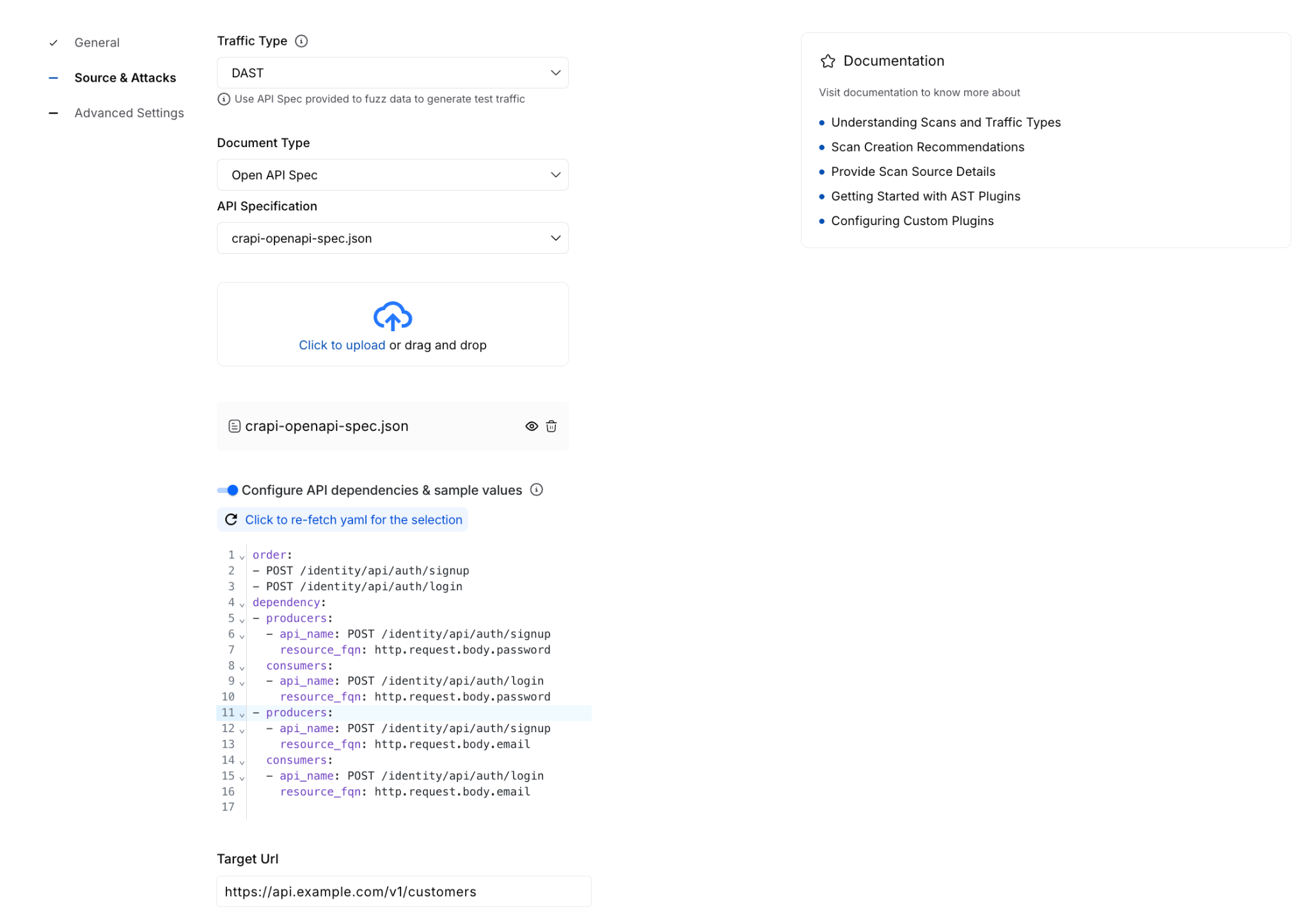
- Advanced Settings - configure optional items such as authentication, runners, traffic filters, URL regex, evaluation criteria, timeout behavior, and integrations.
That reorganization does more than simplify the UI. It separates required setup from optional tuning, helping you complete scan creation with more confidence and less guesswork.
With these enhancements, you can now more easily:
- Understand fields in context through tooltips, helper text, and side-panel documentation available during setup.
- Create policies inline without leaving the scan configuration flow.
- Configure authentication inline, including form-based and AI-based authentication options, then immediately select them for use.
- Create or select runners from the same page instead of navigating out to separate workflows.
This enhancement is especially important for teams that want to move quickly without sacrificing correctness. Keeping these dependent tasks in a single flow reduces interruptions and lowers the risk of setup errors.
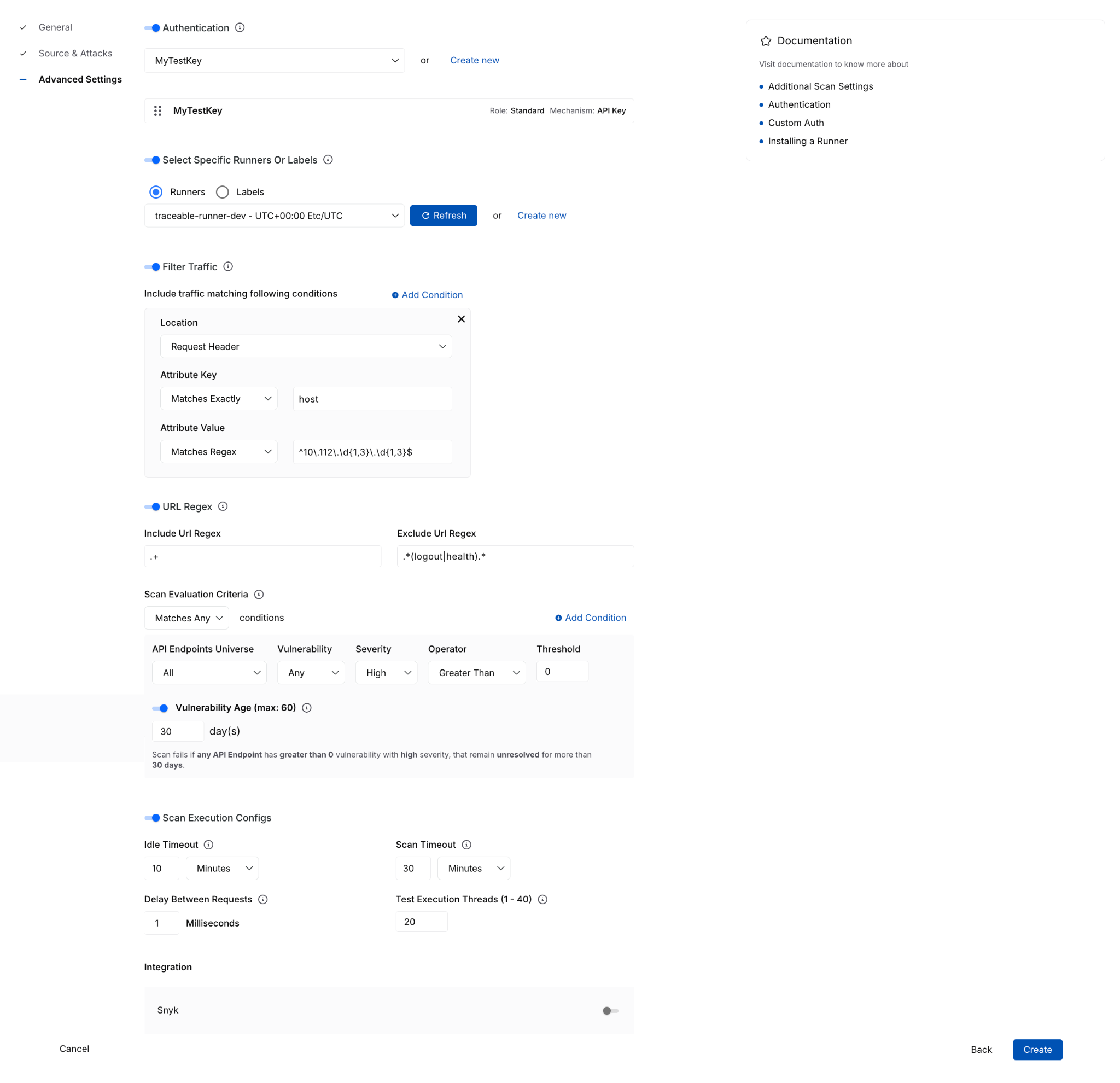
The advanced settings experience also adds more clarity around complex configuration options, where you can now work with:
- Traffic filter conditions
- URL regex settings
- Scan evaluation criteria with dynamic explanatory text
- Idle timeout and scan timeout execution controls
- Integrations
These details matter because they turn a complex setup from opaque to guided and actionable. You can find more technical documentation here.
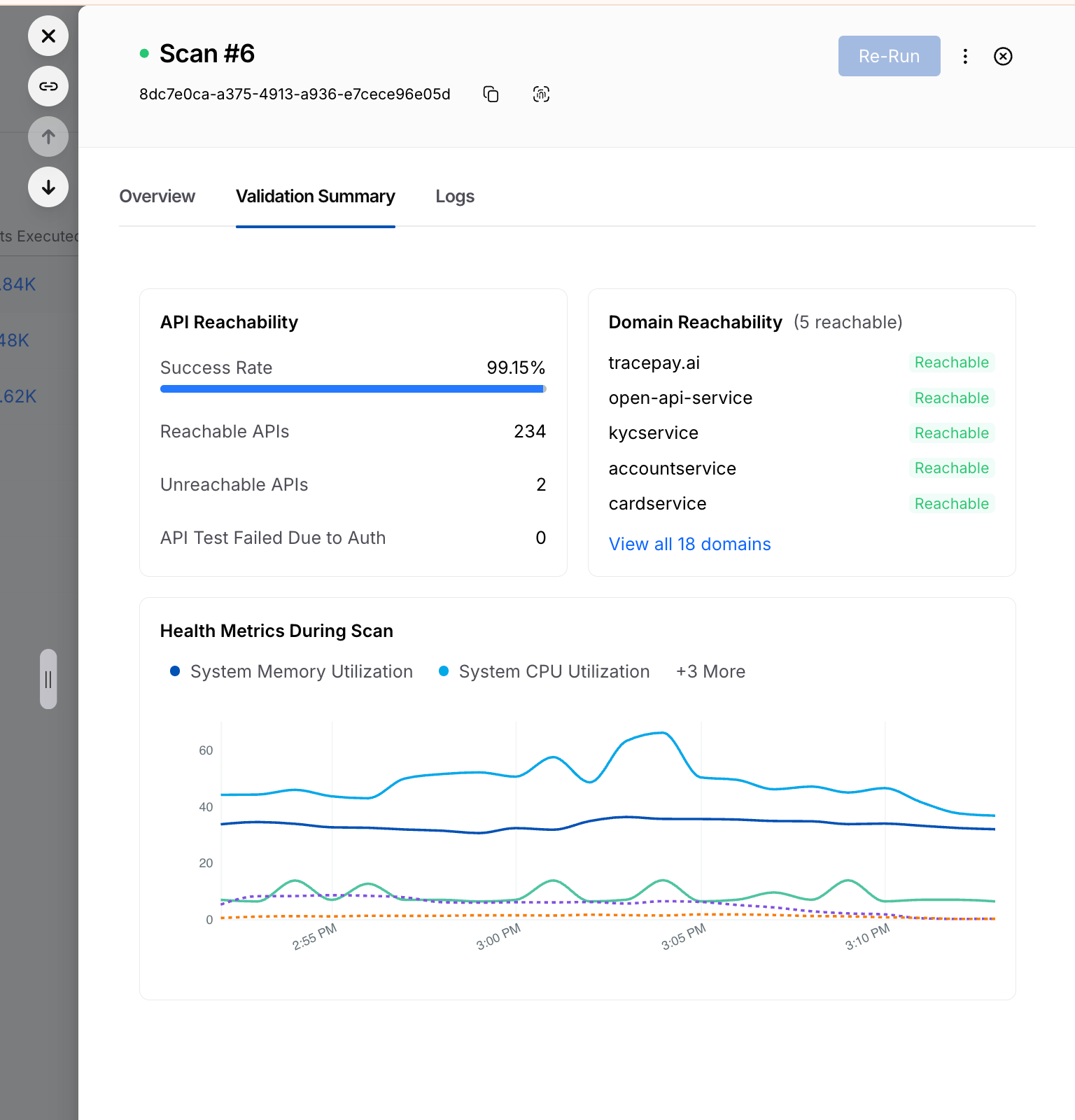
For every running or completed scan, you will now see a Validation Summary tab that highlights critical details and the overall health of the configured API testing. Information here includes:
- Total number of reachable and unreachable APIs
- Number of tests failed due to auth issues
- Domain reachability
- Resource utilization during the scan window
Reachability Test for XAST Replay and DAST
The Reachability Test enhancement brings that same philosophy to execution: validate earlier, execute smarter. Before generating tests, the Harness platform now provides clearer visibility into whether APIs are actually ready to be tested.
The new Reachability Test tab gives you a dedicated place to inspect endpoint readiness before test generation begins. It surfaces:
- the full list of API endpoints
- service mapping details
- reachability status
- response codes
- response descriptions
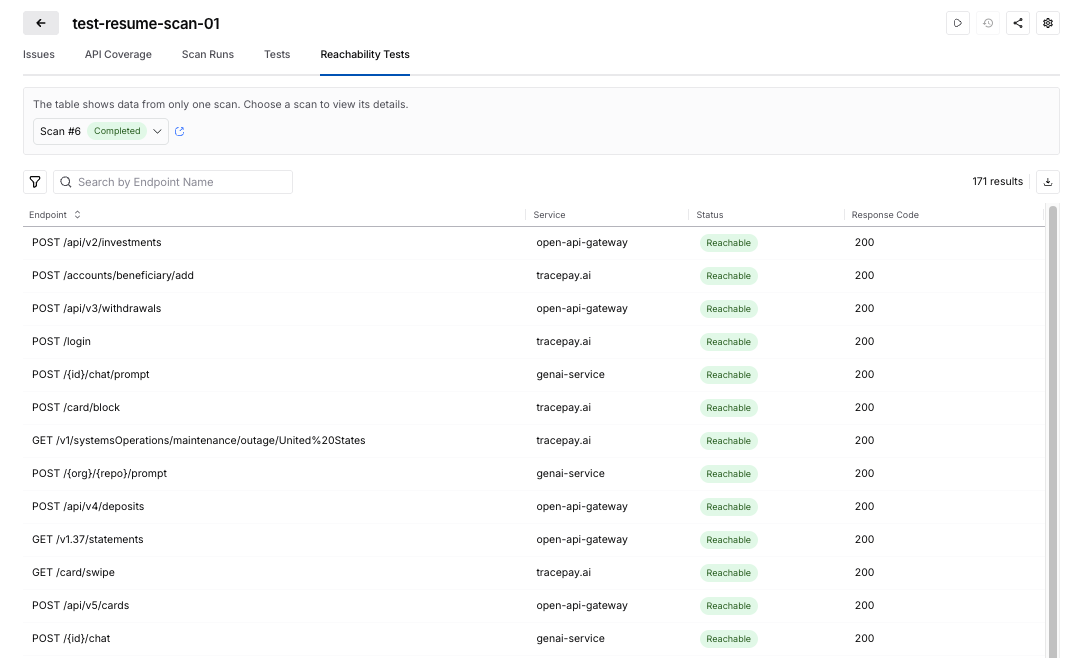
This enhancement turns what was previously harder to diagnose into something visible and actionable.
The Harness platform now uses reachability and authentication readiness as part of test generation control.
That means that no test cases are generated when:
- API endpoints are unreachable
- authentication is missing
- authentication fails
The reachability tests help ensure execution resources are spent on APIs that can actually produce meaningful results. For security teams, this creates a more efficient and trustworthy scan lifecycle with:
- less wasted runner consumption
- fewer irrelevant or misleading test artifacts
- cleaner signal in scan results
- better alignment between reported coverage and executable coverage
You can read more technical details here.
Taken together, these enhancements make API security testing more usable at the front end and more efficient at the back end. Teams can configure scans faster, with fewer errors and less dependency on expert intervention, while also improving the quality of what gets executed once a scan runs.
Get Started Today
These Harness API Testing features are available immediately with your existing Harness subscription. There is no additional cost or setup required.
- Current Customers: Log in to your dashboard today to test the security of your APIs seamlessly and more effectively.
- New to the Platform? If you aren't yet validating your API security, contact us to schedule a personalized demo of Harness API Testing in action.

Google Cloud Next ’26 Recap: AI, Efficiency, and the Rise of Frictionless Delivery
Summary: Google Cloud Next ’26 focused on the future of software delivery, emphasizing that AI, platform consolidation, and an urgent push toward efficiency are reshaping the Software Development Life Cycle (SDLC). The key takeaway from the event was that organizations are moving from AI experimentation to operationalization, actively consolidating fragmented tools onto end-to-end platforms that embed AI for control, intelligence, and speed.
Google Cloud Next 2026 made one thing clear: the future of software delivery is being reshaped in real time by AI, platform consolidation, and an urgent push toward efficiency. From the show floor to executive roundtables, the conversations we had reinforced a consistent theme: teams are looking to tackle the AI Velocity Paradox by simplifying, modernizing, and intelligently automating every stage of the SDLC.
Strong Signal from the Event
We had hundreds of meaningful conversations with engineering, platform, and cloud leaders. The patterns were unmistakable.

Across industries, organizations are grappling with:
- Fragmented CI/CD pipelines
- Manual or inefficient release processes
- Rising cloud costs without clear accountability
- Early, but serious, exploration of AI in the SDLC
These challenges mapped directly to Harness’ core solution areas:
- Software delivery & CI/CD modernization
- Database management & deployments
- AI-powered DevOps & FinOps
And the urgency is real. We spoke with teams:
- Still running homegrown deployment systems, shipping just twice a year due to regulatory constraints, but now exploring AI agents to orchestrate each pipeline step
- Deep in Jenkins-based environments, actively evaluating how to standardize pipelines and modernize security
- Managing multi-cloud footprints and searching for better cloud cost visibility and control
- Using CI tools with agents, but needing help scaling automation across build, test, and deploy workflows
- Leaning into AppSec integrations within CI/CD as security shifts further left
A recurring thread:
“We’re already experimenting with AI, but we need a platform that brings it all together.”
AI in the SDLC: From Curiosity to Commitment
If 2025 was about AI experimentation, 2026 is about operationalization.
We saw a sharp increase in:
- Interest in AI-assisted pipeline orchestration
- Discussions around AI-driven security and compliance workflows
- Demand for intelligent cost optimization tied to engineering activity
Multiple attendees explicitly mentioned:
- Building or planning AI agents across delivery pipelines
- Evaluating vendors based on AI capabilities within CI/CD and DevSecOps
- Wanting to understand how AI can reduce toil without sacrificing control
This shift aligns perfectly with Harness’ vision of AI-native software delivery, where intelligence is embedded, not bolted on. In fact, at Next, we announced a major step forward in making that vision real through our expanded partnership with Google Cloud. By integrating Google Cloud Developer Connect with the Harness Software Delivery Knowledge Graph, we’re enabling a unified layer of AI intelligence across the entire SDLC.
This means AI in Harness isn’t operating in silos. It has full, real-time context across code, pipelines, infrastructure, and runtime signals. The result is smarter automation, faster root cause analysis, and AI agents that can act with confidence, not guesswork. It’s a foundational step in moving from AI-assisted workflows to truly AI-native delivery systems, which is exactly what attendees told us they’re looking for.
A great example of this is Keller Williams. Keller Williams leveraged the Harness platform to transform their software delivery, increasing deployment frequency from a few times a year to over 20+ annual releases. By automating manual pipelines, the platform eliminates operational bottlenecks and allows its developers to focus on rapid innovation rather than deployment logistics.
DevOps Panel: The Future is Frictionless
Harness’s Martin Reynolds joined leaders from Atlassian, Datadog, LangChain, and Google to explore what’s next in a session titled: The Future of Developer Experience is Frictionless
The takeaway?
The next leap in productivity won’t come from isolated tools. It will come from connected, intelligent systems that remove friction entirely. With 150+ attendees on the final day, it was clear this message resonated.
The Bigger Picture: Platform Consolidation is Accelerating
Across every conversation, one strategic shift stood out:
Teams want fewer tools and smarter ones.
Organizations are actively:
- Replacing point solutions and legacy CI/CD tools
- Consolidating onto end-to-end platforms
- Prioritizing security, cost, and delivery in a single workflow
Jenkins modernization alone came up repeatedly. Not as a question of if, but when.
Recognition That Matters
The event kicked off with Google Cloud recognizing its partners. We were proud to be named Google Cloud’s 2026 Technology Partner of the Year, a reflection of the innovation and impact we’re delivering together with GCP.

Final Takeaway
Google Cloud Next ’26 wasn’t just about cloud. It was about control, intelligence, and speed.
The organizations moving fastest right now are:
- Embedding AI into their delivery workflows
- Rethinking how pipelines, security, and cost intersect
- Investing in platforms that eliminate—not add—complexity
Harness is uniquely positioned at that intersection.
And based on what we saw in Vegas, the demand for that future is only accelerating. Here’s the event recap video.

If you connected with us at the event or want to continue the conversation, we’d love to dive deeper.
.png)
Get Ship Done: Everything We Shipped in April 2026
It’s becoming increasingly clear that AI-generated code can create real challenges once it reaches production. At Harness, we’ve been focused on innovating fast and solving those problems, so teams can move quickly without sacrificing reliability.
In the past 30 days, we delivered 70+ new features. These features enable our users to ship fast, not by cutting corners, but by sharpening the feedback loops: faster builds, integrated security checks within the pipeline, deeper visibility into AI across discovery and testing, and deployment tools that are intuitive enough to use without a runbook.
Here’s a look at everything we shipped.
April Highlights
- Harness now lives inside the Cursor IDE. Developers and AI agents go from code change to vulnerability detection, CI/CD execution, security validation, approvals, deployments, and operational insight without leaving the editor.
- Google Cloud Developer Connect now integrates with our Software Delivery Knowledge Graph, giving teams a unified, AI-ready view of the entire software delivery lifecycle.
- With Warehouse Native Experimentation, you can run A/B tests and feature experiments directly in Snowflake, Redshift, or BigQuery, using your existing assignment and metric data as the source of truth. No data exports, no duplication outside your warehouse.
- With SLSA provenance for non-container artifacts, supply chain attestation now covers Helm charts, JAR/WAR files, and standalone binaries, not just container images. If you ship more than Docker images, your provenance story just got complete.
- When an incident closes, Harness AI SRE generates a structured six-section retrospective automatically. What typically takes 2-4 hours comes out in seconds, with action items captured in real time from Slack during the incident.
AI-Powered Development and Delivery
Cursor Plugin
Harness is introducing the Cursor Plugin, bringing AI-native software delivery directly into the Cursor editor. Developers and AI agents move from code changes to vulnerability detection, CI/CD execution, security validation, approvals, deployments, and operational insight without leaving the IDE. The integration includes the Harness Secure AI Coding hook for Cursor. Download the plugin.
Google Cloud Partnership for a unified AI for Software Delivery
We partnered with Google Cloud to integrate Developer Connect with our Software Delivery Knowledge Graph, giving teams a unified, AI-ready view of the entire software delivery lifecycle.
This enhanced context enables smarter, faster AI-driven decisions, helping engineering teams troubleshoot issues, improve accuracy, and deliver software with greater confidence and efficiency. Learn more.
Harness MCP Server Updates
The biggest additions to this version of the MCP server are pipeline YAML support so agent-driven pipelines work with the current schema, OSS vulnerability lookup for supply chain security with anti-fabrication extractors, and added resilience support. Download and get started.
Security Baked Into the Pipeline
SLSA Provenance for Non-Container Artifacts
Supply chain attestation via SLSA now covers Helm charts, JAR/WAR files, standalone binaries, and other artifact types, not just container images. Generate and verify provenance across the full artifact portfolio. Learn more.
OSS Remediation for Code Repositories
Automated and manual remediation for vulnerable open-source components now runs directly against code repositories. When a dependency has a fix available, the tooling can apply it.
API Security Scan Configuration Revamp
The scan creation flow has been simplified into three logical groups: General, Source and Attacks, and Advanced Settings. Every field now has a tooltip and step-level documentation. Field-level validation catches misconfigurations before a scan runs.
Reachability Test for DAST and API Security Scans
Before generating test cases, a new Reachability Test validates that each API endpoint is actually reachable. Endpoints that don't respond don't generate test cases. Reduces wasted scan time against dead endpoints.
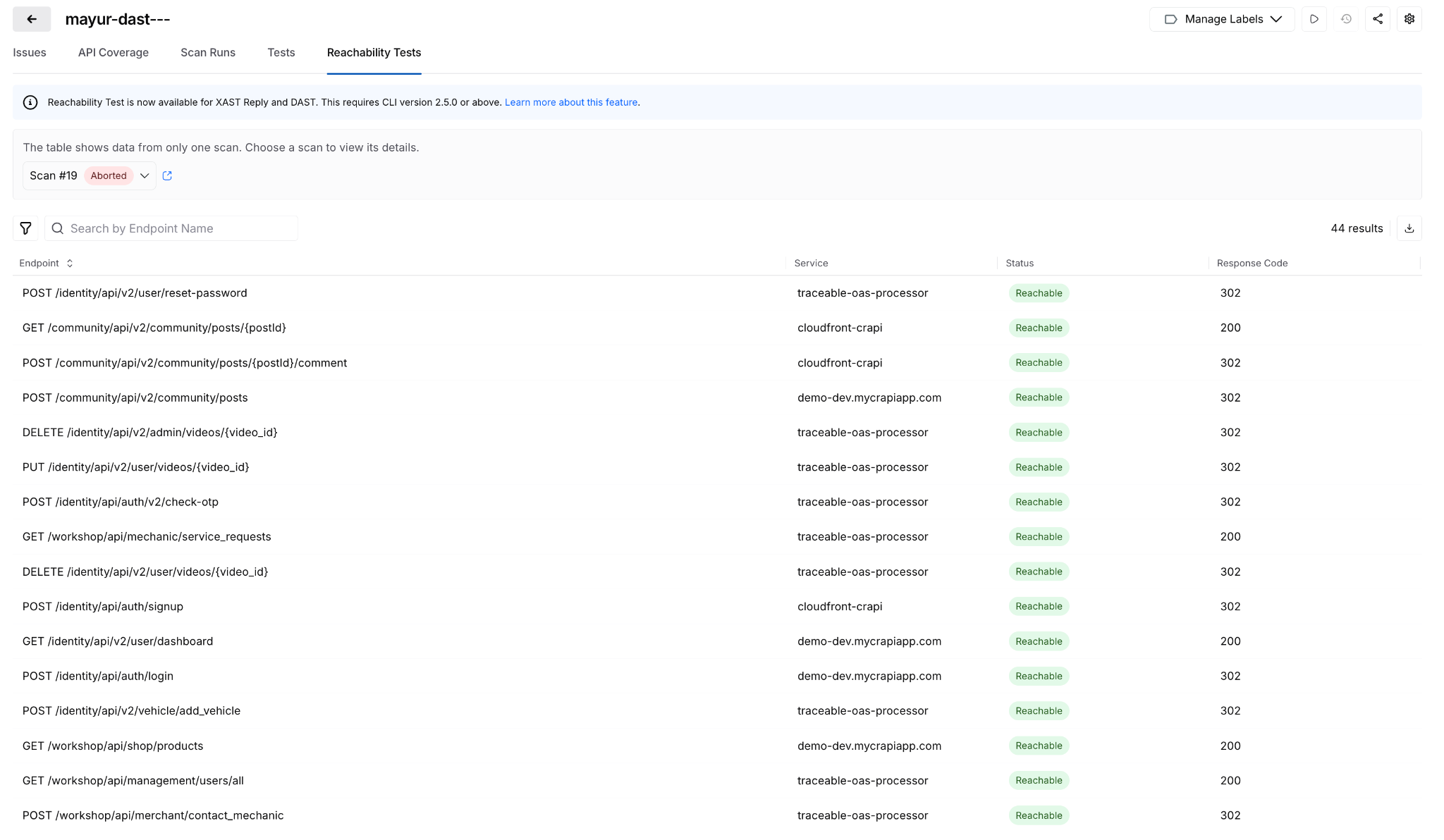
Posture Events: Sensitive Data Evidence
When a posture event involves sensitive data exposure, the finding now shows exactly where: which parameter, in the request or response, with the classification and dataset inline. Previously required navigating across modules to get this context.
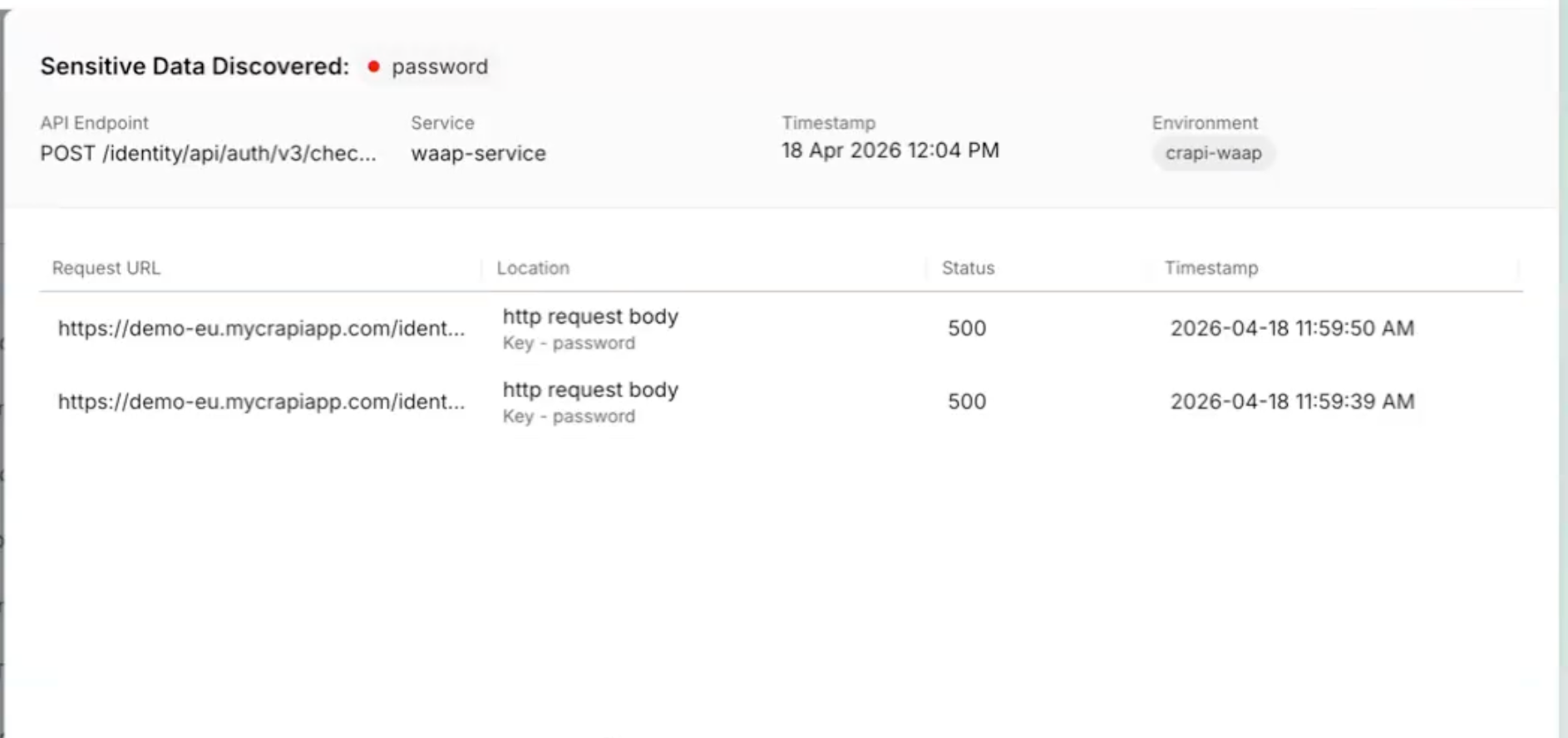
All Occurrences Dashboard
A new account-level dashboard surfaces every raw vulnerability finding across all pipelines, not just the rolled-up view. Filter, export, and drill into file paths, line numbers, and repos. Useful when you need to understand whether a scanner finding is one instance or fifty. Release notes.
Prisma Cloud Scan Result Enhancements
Prisma Cloud (formerly Twistlock) scan results now include File Name, Distro, and Distro Release fields. The file name is derived from packagePath to improve traceability when the same vulnerability appears across multiple package locations.
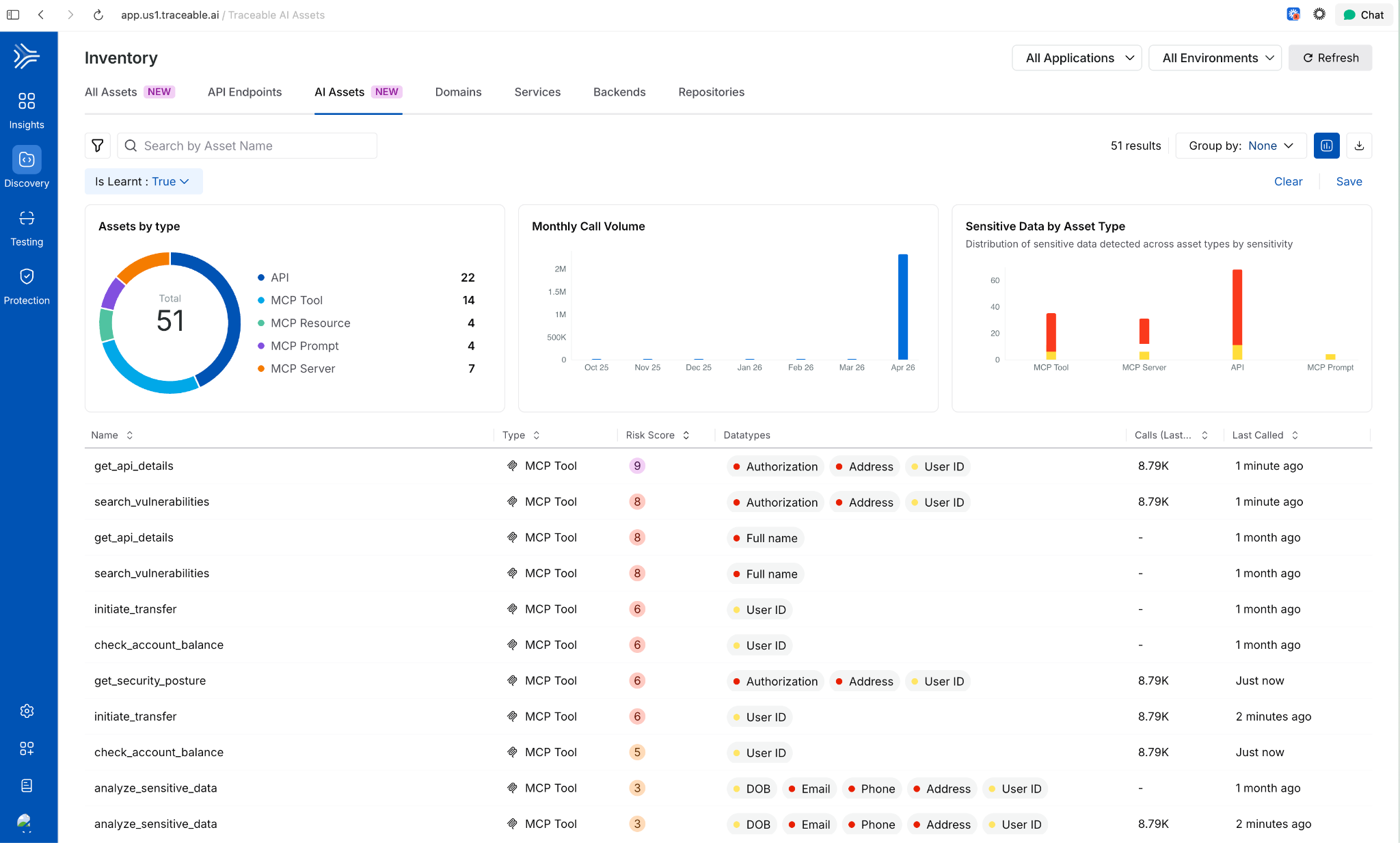
AI Asset Discovery and Risk Visibility
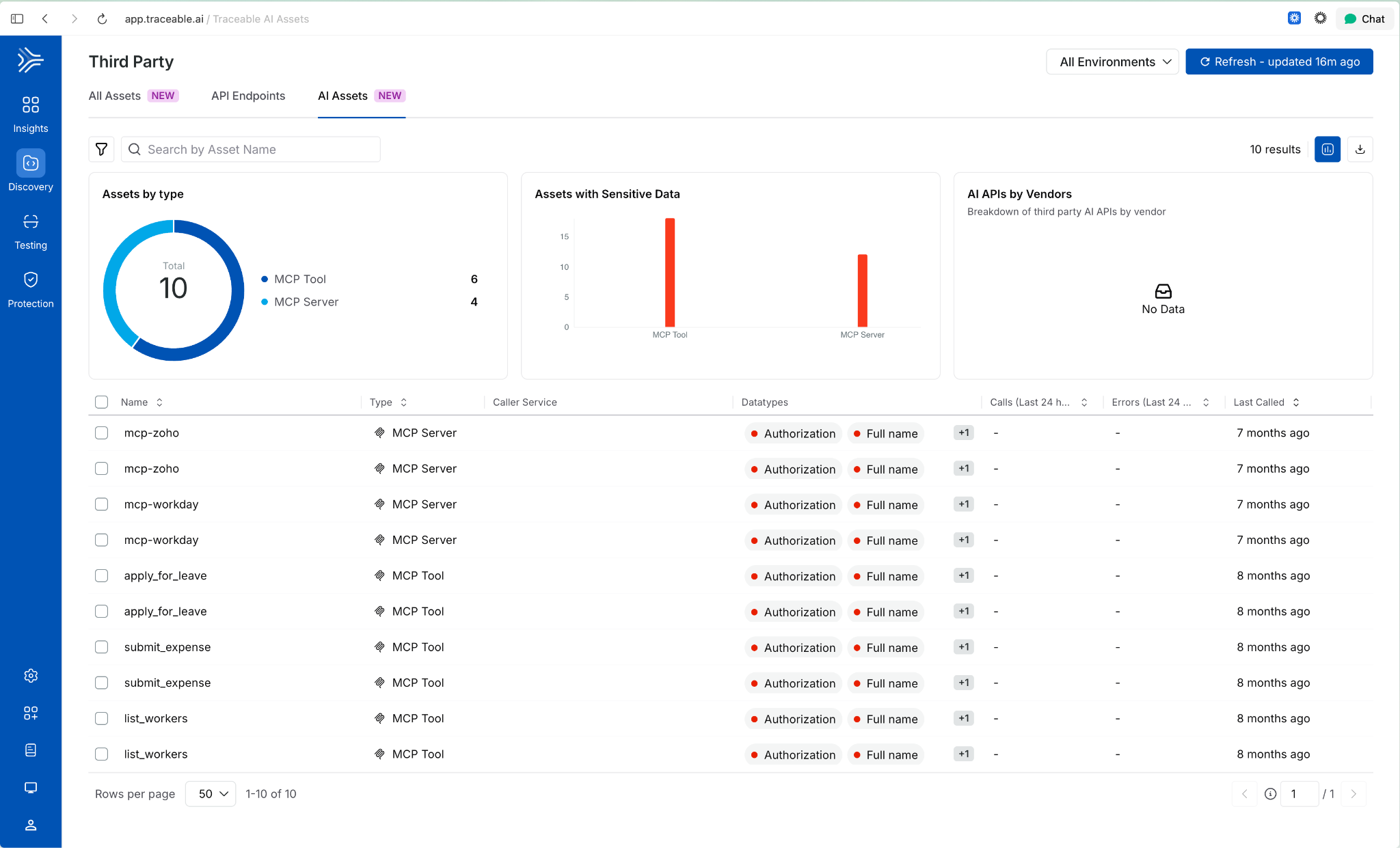
Third-Party MCP Discovery
Extends AI asset discovery beyond your own application ecosystem. Harness now surfaces external MCP servers and the AI assets they expose, giving security and platform teams visibility into AI interactions that originate outside their direct control.
Behavioral Insights Extended to MCP Tools
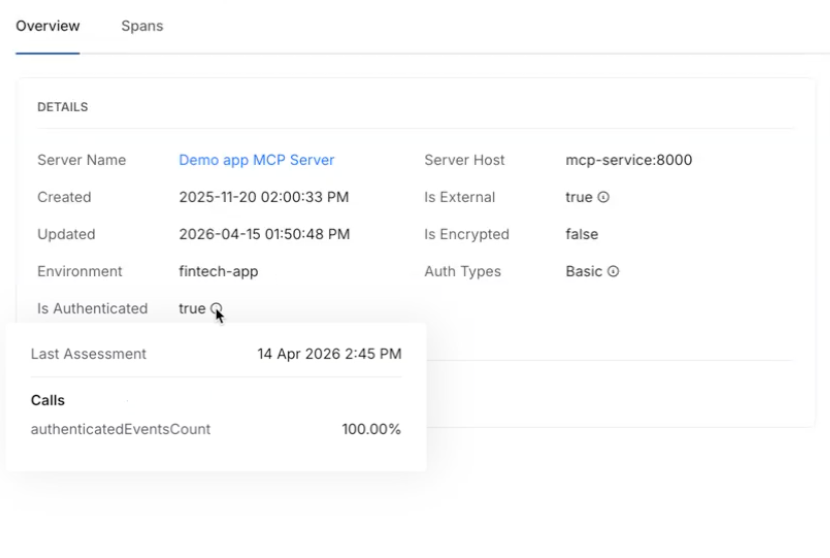
Internet exposure, encryption status, and authentication usage were previously available for APIs only. Those same behavioral signals now apply to MCP tools. View them via the info tooltip on any MCP tool in the inventory. Helps identify high-risk tools based on actual usage patterns, not configuration alone
Risk Score Enhancements for APIs and MCP Tools
Two changes in one release: API risk now shows a unified view with contributing factors, the Likelihood vs. Impact calculation, and direct links to underlying issues. MCP tools now have their own dedicated risk scores using the same model. Side-sheet editing means you can act on a finding without leaving context.
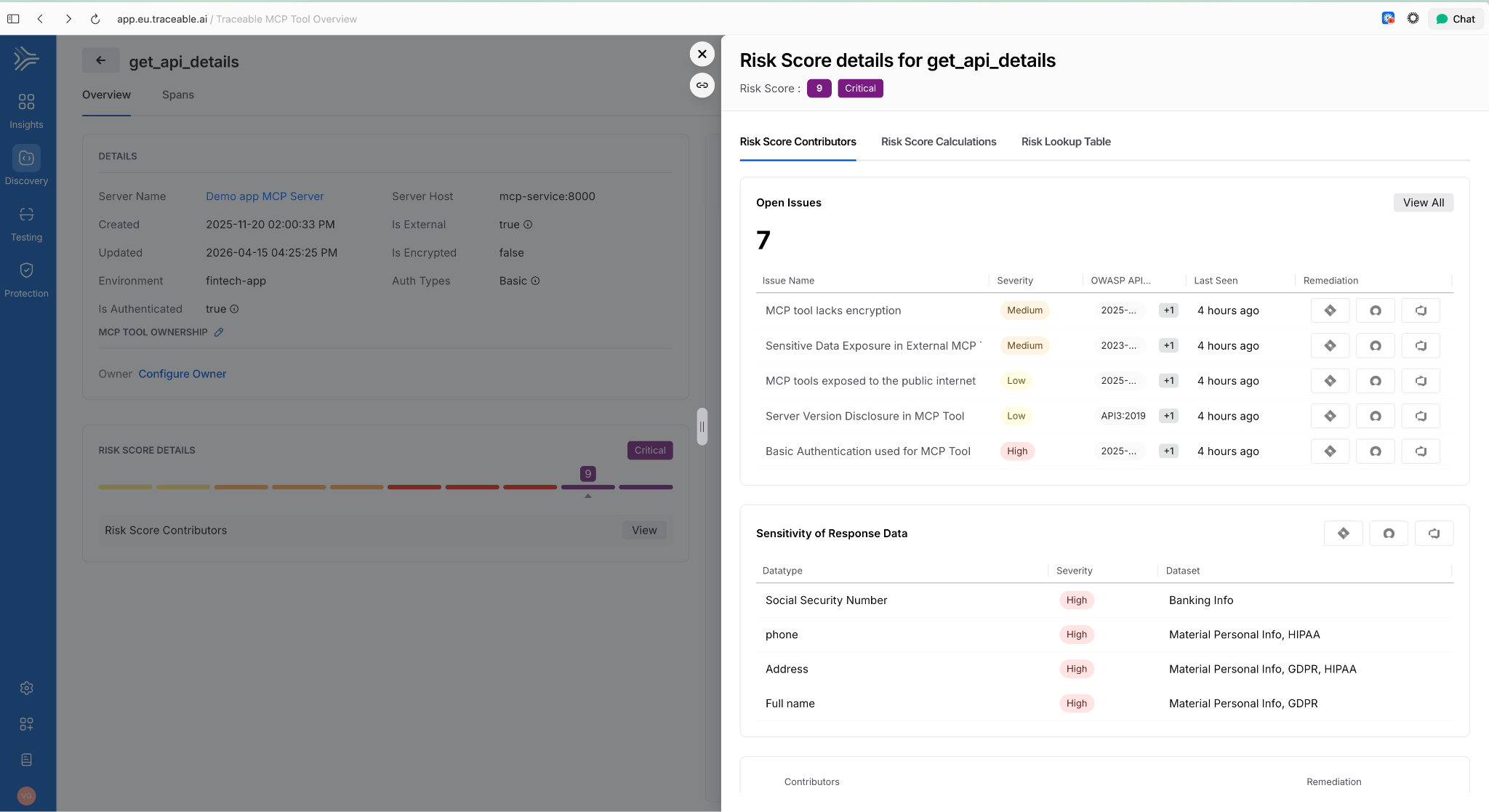
AI Assets Tab and Licensing Visibility
A dedicated AI Assets tab provides a single view of all AI-related assets discovered in customer environments: AI APIs, MCP tools, models, and their usage patterns. Licensing visibility is included so teams can track AI consumption against entitlements.
Deploy Faster and More Reliably
Improved Pipeline Execution Layout
The pipeline execution listing page now uses a card-based layout. The Service and Environment columns are replaced by an Update Summary column showing service-to-environment mappings for CD stages and schema-to-instance mappings for Database DevOps stages, i.e., more signal per row!
AWS Connector Validation Without ec2:DescribeRegions
AWS connector validation now uses sts:GetCallerIdentity instead of ec2:DescribeRegions. The new call requires no IAM permissions, which means tighter least-privilege configurations no longer block connector setup.
ApplicationSet TemplatePatch Support
TemplatePatch configuration in GitOps ApplicationSets is now preserved in the Manifest Edit panel. Previously, setting TemplatePatch in the UI and saving caused the configuration to disappear.
Faster Builds
Cache Storage Connector Override in YAML
Self-hosted builds can now specify a stage-level connector override for cache storage in YAML. If not set, the connector from Default Settings is used. Useful when different stages need to read from different cache backends.
Containerless Step Binary Path
Containerless CI steps now use app.harness.io as the default download path for step binaries. This reduces egress dependencies on external sources.
Feature Flags and Experimentation
Warehouse Native Experimentation
Run experiments directly in your data warehouse using your own assignment and metric data. No exporting, no duplicating data outside your analytics source of truth. Supports Snowflake, Amazon Redshift, and Google BigQuery. Release notes.

Reallocate Traffic API
A new Reallocate Traffic endpoint lets you reset the bucketing seed for a feature flag in a specific environment via the API. Useful when you need to re-randomize user assignments without changing the flag configuration.
Infrastructure as Code
Native Terragrunt Support and Multi-IaC Orchestration
Teams can now orchestrate complex deployments across Terraform, OpenTofu, and Terragrunt in a single platform. A unified multi-IaC control plane eliminates fragmented tooling, standardizes workflows, and covers provisioning, configuration, and deployment consistently. Read the blog post.
AWS CDK Support (Beta) Define AWS infrastructure in TypeScript or Python using the AWS Cloud Development Kit and let Harness handle provisioning, state, and pipeline integration. Engineers who already write CDK don't need to learn HCL or adopt a separate tool.
Module Registry 2.0 Store IaC modules as artifacts natively in Harness, auto-sync new versions as they're published, and run module onboarding directly on Harness pipelines. A single place to manage the full module lifecycle: publishing, versioning, and consumption, without stitching together a registry, a pipeline tool, and a version tracker.
Terraform Sensitive Output Masking (Beta)
Output fields marked sensitive = true in your main.tf are now automatically masked in the pipeline Output tab during Terraform Apply step execution. Sensitive outputs remain accessible in downstream steps via Harness expressions, but don't appear in plain text in the UI.
Artifact Management
Swift Package Registry
Artifact Registry now supports Swift packages with full SwiftPM compatibility. Authenticate, publish, and resolve dependencies using the registry URL directly. Existing SwiftPM workflows work without changes. Release notes.
Raw File Registry
A new Raw File registry stores and retrieves arbitrary files by path: archives, reports, configuration files, binaries, anything that doesn't belong to a package manager. Upload and download via HTTP and curl. No specialized client required.
Copy Version Between Registries
Promote a specific package version from one Harness registry to another directly from the UI. No re-pushing from your machine, no scripts to move artifacts between project or organization registries.
Soft Delete for Artifacts and Versions
Deleting a package or version now moves it to a Deleted view where it remains recoverable until the retention window expires. Permanent delete is available from the same dialog when that's the intent.
Artifact Registry Audit Dashboard
An out-of-the-box dashboard records every artifact upload and download across all Harness Artifact Registries. Provisioned and maintained automatically for accounts with Artifact Registry enabled. No setup required.
Webhooks Extended to Python, Maven, and NuGet
Artifact Registry webhooks now cover Maven, NuGet, and Python (PyPI) in addition to existing package types. Use artifact events to trigger CI/CD, security scans, or notifications for more of your package ecosystem.
Database Changes Without the Drama
IBM DB2 Support
Database schema changes and migrations now work across all DB2 variants: DB2 LUW, DB2 for iSeries, and DB2 for z/OS. Mainframe and midrange databases now fit in the same pipeline workflow as everything else. Release notes.
Google BigQuery Support
Deploy database changes to BigQuery using the same Liquibase-based workflow used for relational databases. No separate tooling or custom scripting required.
Percona Toolkit for MySQL
Use Percona Toolkit natively in Harness Database DevOps to make MySQL schema changes safer and virtually downtime-free. Read the blog post.
ECS Support for Database Jobs (Early Access)
Database DevOps can now run deployment jobs on ECS Fargate instead of Kubernetes. For teams not running Kubernetes, this removes the requirement to stand up a cluster just to run database migrations. Contact Harness to enable. Read the docs.
Keyless Authentication for Google CloudSQL
Authenticate to CloudSQL (Postgres and MySQL variants) using the delegate's service account. No credentials to rotate, no secrets to manage. Read the docs.
OIDC Authentication for Google Cloud Databases
Authenticate to CloudSQL (Postgres and MySQL), Google Spanner, and Google BigQuery using OIDC. Works with any OIDC-compatible identity provider already in use for the rest of your Google Cloud infrastructure. Read the docs.
Engineering Metrics and Developer Portal
Environment Management
Developers can now self-serve dev, test, staging, and production environments directly from the developer portal. Platform teams configure the governance rules; developers provision within those bounds without opening a ticket. Read the blog post.
ServiceNow Integration for Engineering Metrics (Beta)
DORA metrics in the Efficiency Insights dashboard can now be calculated from ServiceNow incident and change management data. Deployment Frequency, Change Failure Rate, and MTTR all supported. Useful for teams where ServiceNow is the system of record for incidents, not a secondary tool.
Custom Dashboards in Engineering Metrics (Beta)
A new Canvas page (being renamed to Studio) lets teams build custom Insights dashboards using HQL queries across all data sources. Dashboards support Draft and Published states. Query Variables allow dashboards to adapt dynamically per team or environment.
Custom Entity Kinds in Developer Portal
Platform engineers can now define entity kinds beyond the built-in set (Component, API, Resource, Environment, System). Model domain-specific software components that don't fit existing kinds, with their own name, icon, and JSON Schema for validation. Release notes.
SonarQube Integration in Developer Portal
Harness connects to SonarQube Server (self-hosted) or SonarQube Cloud and brings projects into the developer portal catalog as catalog entities. Code quality data surfaces alongside the rest of your software catalog.
Scorecard Aggregation
Scorecard data can now be aggregated across multiple catalog entities. Roll up compliance and health metrics from individual components to systems or domains without manually combining reports.
Custom Dashboard Data Retention Extended to 12 Months
The data retention period for custom dashboards increased from 3 months to 12 months. Longer historical windows for trend analysis and compliance reporting.
Code Repository Language Breakdown
Developers can now see the language composition of any repository directly in the list view and repo detail page. Particularly useful when migrating off other source control systems and auditing what you're moving.
Code Repository Tags Repositories can now be tagged with metadata like team, intent, or domain, consistent with how pipelines, connectors, and other Harness entities are tagged. Useful for filtering, governance, and search at scale.
AI SRE
AI-Generated Post-Mortems with Action Item Detection
When an incident closes, AI SRE automatically generates a structured six-section retrospective: Summary, Impact, Root Cause, Resolution, Insights, and Lessons Learned. The AI synthesizes the full incident context: timeline events, Slack conversations, RCA theories, and responder actions. What typically takes a lead engineer 2-4 hours to write comes out in seconds. Action items are detected in real time from Slack conversations and meeting transcripts during the incident, with each item including a description and the responsible person extracted from context. They carry forward into the post-mortem automatically, so nothing gets reconstructed from memory days later. Release notes.
ServiceNow Change Record Correlation in RCA
When an incident fires, the AI Investigator automatically pulls recent ServiceNow change records and correlates them to the incident timeline. If your organization already has a Harness ServiceNow connector configured for pipelines or approvals, change data flows into root cause analysis immediately with zero additional setup. Change records appear alongside deploy events and code changes in the AI's correlation engine, reducing manual cross-referencing between tools. Documentation.
Stakeholder Status Updates
Incident commanders can now broadcast structured status updates to subscribed stakeholders (executives, customer support, dependent teams) without flooding the war room. Stakeholders subscribe to the services they care about and receive updates triggered by the Incident Lead. The system pre-populates a branded email with incident ID, title, summary, impacted services, and current status. The sender reviews, edits if needed, and sends. Eliminates the "what's the status?" interruptions that pull responders out of active response. Release notes.
Google Chat Integration
Teams running Google Workspace can now run incident response directly from Google Chat: create incident channels, post updates, receive notifications, and collaborate in real time. Uses a Pub/Sub-based architecture for reliable message delivery. Bring incident collaboration to Google Chat on par with the existing Slack integration. One-time admin setup per organization.
Runbook Slug Commands in Slack
On-call responders can now trigger runbook automations from Slack using short slug commands: /harness run <slug>. No UI navigation during high-pressure response. Common actions like restart-pods or scale-up become muscle memory. Removes a context switch from the critical path during active incidents. Release notes.
Chaos Engineering and Resilience Testing
MCP support for Resilience Testing
MCP support for Resilience Testing improves extensibility across chaos and resilience workflows.
Pipeline Integration with Chaos Step Templates
Any experiment template can now be referenced and used from any scope in a pipeline. Makes it easier to standardize chaos execution across delivery workflows.
Probes and Observability Splunk Enterprise and Datadog APM Probes
APM probes now support Splunk Enterprise and Datadog. Teams can validate system behavior during experiments using the observability tools they already rely on.
Namespace Label Filters in ChaosGuard
ChaosGuard conditions now support namespace label filters, giving teams finer-grained control over which namespaces chaos experiments can target. Release notes.
Experiment Run Reports
Experiment run reports are now available in the UI and accessible via a new API endpoint that returns report data as JSON. Useful for integrating chaos results into external dashboards or compliance workflows.
Docker Labels-Based Chaos Injection on ECS
Added support for targeting ECS in-VM SSM chaos injection using Docker labels. Expands targeting flexibility for teams running mixed ECS workloads.
Other Updates
- Service account token notifications: Configure alerts for token creation, rotation, updates, expiration, deletion, and upcoming expiration across your notification channels.
- Cloud cost RBAC enforcement: Users with CCM Viewer (view-only) access no longer see an enabled Save Preferences button in Cost Settings. RBAC is now consistently enforced across the Recommendations and Anomalies pages. Release notes.
- Rejected and Ignored recommendations moved to main view: These lists are now in the Recommendations list itself, enabling direct export without extra navigation.
- AI test automation task nesting limit: Tasks can now nest at most two levels deep, preventing runaway task hierarchies. Enforced in both UI and backend. Release notes.
- Chaos Engineering LLM optimization: Recommendation calls are now processed in chunks instead of one-by-one, reducing latency for experiment recommendation generation.
- IDP sync and delete for integrations: Integration instances (ServiceNow, Kubernetes, SonarQube, GitHub) now include sync and delete actions directly in the UI.
- IDP separates create and edit permissions: Environment and Blueprint permissions are split into distinct Create and Edit actions for finer-grained access control.
- IDP custom user identifiers: The saveDiscoverEntities API now accepts an explicit action_identifier field when registering catalog entities.
Closing
70+ features in 30 days. The teams using AI to accelerate code generation are now running into the same reality we tracked in March: the bottleneck isn't writing code, it's everything downstream. Artifact management, security posture, deployment reliability, incident response, and AI asset governance. April's releases push the feedback loop tighter at each of those stages. Post-mortems that took 4 hours now take seconds. The change record correlation that required manual cross-referencing now happens automatically.
The velocity compounds when the whole software delivery moves together, not just the part where the AI writes code.
See you in May!
From PR to Production Without Leaving Your Cursor IDE
TLDR: Today, Harness is introducing the Harness Cursor Plugin, bringing the power of the Harness AI-native software delivery platform directly into Cursor. This integration, along with the Harness Secure AI Coding hook for Cursor, allows developers and AI agents to move from code changes to vulnerability detection, CI/CD execution, security validation, approvals, deployments, and operational insight without leaving the editor.
AI has completely changed how we write code. You can spin up functions, refactor entire files, and generate tests in seconds. The inner loop, writing and iterating on code, has never been faster. But the moment you try to ship that code, everything slows down. This is what we call the AI Velocity Paradox.
You are suddenly back to juggling pipelines, waiting on approvals, checking security scans, debugging failed runs, and bouncing between tools just to get a change into production.
That gap, between fast code and slow delivery, is what we kept running into. So we built something to fix it.
Today, we are introducing the Harness Plugin for Cursor, a way to go from PR to production without leaving your editor.
AI Made Coding Faster, But Delivery Did Not Catch Up
If you are using agentic coding tools, such as Cursor, you have probably felt this.
You can:
- Generate code instantly
- Understand unfamiliar repos faster
- Fix bugs and open PRs in minutes
But shipping still depends on everything outside your editor:
- CI/CD pipelines
- Security checks
- Approval flows
- Policy enforcement
- Deployment tooling
- Monitoring and debugging
And none of that got simpler just because AI showed up. In fact, AI makes the problem more obvious.
Now you can create changes faster than your delivery process can safely handle. And if those controls are not tight, you are introducing a whole new category of risk. Fast-moving code with fragmented governance.
AI did not break software delivery. It exposed how disconnected it already was.
What If You Could Just Ask
Instead of jumping between tools, what if you could just tell your editor what you want to happen?
Something like:
“Deploy PR #4821 to staging once the security scan passes, and Slack me if anything fails.”
That is the idea behind the Harness Cursor Plugin.
It connects Cursor directly to Harness, so you can trigger and manage your entire delivery workflow using natural language, right inside Cursor.
No tab switching. No manual orchestration. No guessing what is happening in the pipeline.
Some Sample Use Cases
Once connected, you can use Cursor to interact with your delivery system just as you do with your code.
For example, you can:
This builds on what we introduced last month, Secure AI Coding, which integrates directly with Cursor and scans code at the moment of generation rather than waiting for a PR review. Developers see inline vulnerability warnings with the option to send flagged code back to the agent for remediation, without leaving their workflow. Under the hood, it leverages Harness's Code Property Graph (CPG) to trace data flows across the entire codebase, surfacing complex vulnerabilities that simpler linting tools would miss.
The key thing is that you are no longer just interacting with code. You are interacting with the entire delivery system from the same place.
The Important Part: This Is Not Skipping Control
One of the biggest concerns with AI in delivery is obvious:
“Are we about to let agents push code to production without guardrails?”
No.
With Harness, everything runs through the controls that you can rely on:
- Granular RBAC permissions
- OPA policies
- Approval gates
- Audit logs
Instead of being manual checkpoints spread across tools, they are enforced automatically as part of the workflow while you stay in flow.
So AI can help move things faster, but it cannot bypass the governance that matters.
Why We Built It This Way
Most integrations today expose APIs or bolt AI onto existing systems. That is not what we wanted to do.
We designed the Harness Cursor Plugin specifically for how AI agents actually work:
- It is built around actions and workflows, not raw endpoints
- It spans the full delivery lifecycle, not just one step
- It gives agents enough context to reason about what to do next
Because shipping software is not a single action. It is a chain of decisions across CI, CD, security, approvals, and operations. If AI is going to help here, it needs access to that full picture. That’s where the Harness Software Delivery Knowledge Graph comes into play. It provides the necessary context for AI to take actions for you.
The knowledge graph models the relationships between services, pipelines, environments, policies, and operational signals in real time. Instead of treating each step in delivery as an isolated task, it creates a connected system of record that AI can reason over. This allows agents to understand not just what to do, but when and why to do it, based on dependencies, risk signals, and historical behavior.
In practice, this means smarter automation: deployments that adapt to context, approvals that are triggered based on policy and impact, and faster root cause analysis because the system already understands how everything is connected.
This Changes How Ideas Move To Prod
This is not just about convenience. It is a shift in how software actually moves from idea to production.
Instead of:
- Writing code in one place
- Managing delivery somewhere else
- And stitching it all together manually
You get a single, connected workflow:
- Code to pipeline to validation to deployment to operations
All accessible from your editor. Cursor accelerates the building. Harness governs the shipping. And the handoff between the two disappears.
Watch the demo:
Getting Started
If you want to try it:
- Install the Harness Cursor Plugin from the Cursor Marketplace
- Authenticate with Harness using OAuth. No API keys or setup headaches
- Start using natural language to run pipelines, debug issues, and manage deployments
For example:
“Run the CI pipeline for this branch, check if the security scan passed, and promote to staging if it did.”
That is it.
AI is not just changing how we write code. It is changing expectations for how fast we should be able to ship it. But speed without control does not work in real environments. What we are building toward is something simpler:
A world where every step, from PR to production, is:
- Fast
- Governed
- Observable
- Auditable
Without forcing developers to leave their flow. This plugin is one step in that direction.

AI writes the code. Who delivers it safely?
The question for enterprise AI in 2026 is no longer just which model. It’s which harness.
An agent harness is the system around the model. It decides what the agent remembers, what context it sees, what tools it can call, what it is allowed to do, and what happens when it is wrong.
The model provides intelligence. The harness provides control.
This is where the real engineering is happening. When Claude Code's source was accidentally exposed earlier this year, reports put it at more than half a million lines. None of that was the model. All of it was the system around the model.
The model gets you started. The harness gets you to production.
In software engineering
Software engineering is one of the first places this plays out. AI coding tools are writing and editing code. Autonomous agents are starting to deploy, operate, and respond to incidents. These are not suggestions anymore. They are changes to running software, made by agents acting on their own.
And one harness is not enough.
Two loops, two harnesses
Software engineering has two halves at the level that matters for agent harness design. Software development, where code gets written. Software delivery, where code becomes running software.
The inner loop is software development. Code gets written, edited, tested, and reviewed. Coding agents work here, close to the developer and bounded by the repository. Whether they live in an IDE, a terminal, a background session, or a web workspace doesn’t change what they do. They help one person write better code faster.
The outer loop is software delivery. Code becomes software that is built, tested, secured, deployed, verified, operated, and sometimes rolled back. That includes CI, security scans, deployments, infrastructure, feature flags, incidents, and approvals.
The two are loops different. The inner loop is about individual productivity. The outer loop is about organizational execution under risk. It crosses teams, touches production, uses secrets, enforces policy, and leaves an audit trail.
An agent delivering software can’t be a coding assistant with API access. It has to run inside a system that enforces the organization’s rules.
What goes wrong without the right harness
The stakes are easier to see by starting with what breaks.
Security. An agent with broad access to deploy, provision, and push config changes is a new attack surface. Prompt injection through a PR description, a poisoned dependency, or a malicious issue comment can turn an autonomous agent into the most privileged insider threat in the company. It acts under its own identity, with its own scoped credentials, doing exactly what it’s authorized to do. The attacker just redirects the authorization. Without an identity model and governed execution, every action the agent can take becomes a potential action path for an attacker.
Compliance. An agent that ships code without the same policy gates, approvals, and audit trails humans use creates a parallel path that regulators and auditors will challenge. A single deployment that skipped EU data residency review can trigger a finding that takes quarters to close. Cyber insurers are starting to scrutinize AI governance, and some are exploring exclusions or tighter terms for poorly governed AI. Within a year or two, “we have autonomous agents deploying code without an evidence trail” will be impossible to defend. Autonomous delivery without verification is autonomous liability.
Confident bad decisions. An agent with partial context looks like it’s working. It deploys during a change freeze. It rolls out a config change that breaks an upstream service. It enables a feature flag during an incident. Each failure is locally reasonable and globally wrong. Without the full knowledge graph, the agent keeps making the wrong call.
AI-specific failure modes. Autonomous agents fail in ways that deterministic automation doesn’t. They hallucinate actions, generating and deploying a Kubernetes manifest that doesn’t match reality. They get stuck in loops, rolling back and redeploying the same change until a human kills the process. They’re confidently wrong, proposing a fix that passes a weak policy gate and breaks production an hour later. No attacker involved. Without verification strong enough to catch them, errors reach production.
All of this has happened with deterministic automation, one mistake at a time. With autonomous agents, errors happen in parallel. A coding agent with bad context can push 10 broken PRs in 10 minutes. A delivery agent without verification can deploy 20 services before anyone notices.
Speed used to be the feature. With autonomous agents, speed is also the damage multiplier.
What a software delivery agent actually needs
A software delivery agent needs four things: memory, context, tools, and verification. The shape and stakes of each element are distinct.
Suppose a team is shipping a new version of a retailer’s checkout service on Thursday. Checkout depends on payments, inventory, fraud, and identity.
Memory: a graph of how your company ships
A Software Delivery Knowledge Graph is a connected map of services, teams, pipelines, deployments, incidents, policies, scorecards, and artifacts. Nodes and edges show how they all relate.
To answer “Is checkout safe to ship Thursday?”, the agent has to know which services checkout depends on, what their scorecards look like, whether any have open critical CVEs, whether there’s a change freeze, and who’s on call Thursday night.
Tha’is a graph query. If the agent doesn’t have the graph, it’s guessing.
Context: the live signal
Memory is the durable map. Context is the live signal. Memory tells the agent how the delivery system is connected. Context tells it what’s happening now.
Back to checkout. The agent sees that a chaos experiment last week showed payments fail when its Redis cache is unavailable. It sees that yesterday’s security scan flagged a critical CVE in a library fraud detection depends on. It sees that the new version changes the same config flag that caused an incident two weeks ago.
None of this is in the pull request. All of it matters.
Context isn’t something you assemble from scratch at runtime. It accumulates in the harness long before the agent is asked to act.
Tools: governed execution
People often assume “tools” means function calls to APIs. For a software delivery agent, it means something different. The agent can deploy to Kubernetes, run a database migration, apply a feature flag, trigger a security scan, run a chaos experiment, open and close an incident. Real actions, inside your network, using your credentials, under your policies, with full audit logging.
At Harness, every action runs through a Delegate: a lightweight worker inside your environment. Your VPC, your Kubernetes cluster, your data center. The agent issues an instruction. The Delegate executes it inside your perimeter and returns the result.
Secrets are decrypted inside the Delegate. Never in the agent’s context window, never in a model provider's memory, never in an audit log.
An agent with arbitrary production access is dangerous. An agent constrained by governed execution is governable.
Verification: proving the action was safe
This is the pillar coding and personal productivity agents don’t need at this depth. Software delivery agents do.
Three mechanisms make it concrete:
- Scorecards grade services against rules the organization defines. Test coverage, SLO compliance, library currency, critical CVEs. Every rule measurable. Every score live. Thresholds set by the organization.
- Policy gates block actions until conditions are met. “No deployment without a passing scorecard.” “No EU infrastructure change without a named EU approver.” The gate sits in the pipeline. The agent can’t route around it.
- Evidence is cryptographically signed proof that each action met its policy. When an auditor asks, “prove last Tuesday’s deployment passed security testing,” the system returns a tamper-evident record.
For checkout, the Thursday release is blocked unless the scorecard passes, no critical CVEs are open, no change freeze applies, and an EU compliance approver signs off. If any of those fail, the agent cannot deploy. If they all pass, the deployment runs through a Delegate and an evidence record is written.
The rules of the organization are enforced in the harness. The agent operates inside them.
The foundation is already built
I mentioned that an agent needs memory, context, tools, and verification. The good news: a modern software delivery platform like Harness already has the foundations, because truly automated delivery has always needed those four things.
A note on our name. We called the company Harness in 2017 because the original thesis was a safety harness for code: let developers move fast without breaking things. Pipelines, policies, approvals, rollbacks, evidence. The scaffolding that lets speed and safety coexist.
That thesis hasn’t changed. The mover has. Developers are still moving fast. AI agents are moving fast too, and faster. The harness has to hold both.
Pipelines aren’t agents. Pipelines are the harness that lets agents safely act. They’re the control plane where agent actions are evaluated, constrained, and executed under policy.
The word “pipeline” carries baggage. Many people hear “script runner.” That isn’t what we mean. Harness pipelines are production orchestration engines: loops, matrix runs, parallel stages, conditions, approvals, OPA gates, rollback, retries, and deterministic-plus-agentic step-chaining.
An agent step can run inside a loop. A deterministic step can pass output to an agent, then to a policy gate, an approval, another agent, and a deployment. The agent isn’t replacing the pipeline. The agent is one kind of step the pipeline already knows how to run.
Harness pipelines execute hundreds of millions of runs a year across enterprise production systems. That isn’t a theoretical runtime for agents. It’s a runtime already hardened at scale, on real delivery, under real policy, with real rollback. That’s the difference between a script runner and a production harness for autonomous action.
The rest of the foundation maps the same way. The Delegate is how actions reach your infrastructure. The Software Delivery Knowledge Graph is the memory. Our platform modules are the tools. Scorecards, policy gates, and signed evidence are the verification. Harness AI, the intelligence layer on top, uses all four of these elements.
We didn’t set out to build an agent harness. We set out to build a software delivery platform with AI at its core. It turns out those two things are the same.
Why coding agents are a different harness
Coding agents (IDE copilots, background agents, terminal-based assistants, cloud coding sessions) are built for a different job. They know your codebase, your style, your recent commits. That’s a real harness, bounded by the repository and the developer. A software delivery harness has different scope, memory, risks, and accountability.
A coding agent’s memory is the repository. A software delivery agent’s memory is the organization.
The context gap. Ask your coding assistant: “Is it safe to deploy this checkout change to production tonight?” It can’t answer. It doesn’t know the current scorecard, the change freeze status, last week’s chaos test results, or who’s on call. None of that lives inside the developer's workspace. A coding agent can write a change. It can’t know if the change is safe to ship.
The blast radius gap. A coding agent’s bad change usually gets caught before it hurts anything: in review, in CI, in a security scan, on a policy gate. Fifteen minutes wasted, not a production incident. A software delivery agent’s worst day is customer data exposure, a production outage, or a regulatory incident. Same agent paradigm, radically different blast radius.
The safety-net gap. Both kinds of agents are moving toward less human oversight. The difference is what catches them when they’re wrong. A coding agent mistake gets caught downstream: by CI, by security scans, by policy gates, by the delivery harness itself. A delivery agent mistake has nothing downstream. It is the downstream.
The control-plane gap. Could a coding agent call Harness as a backend? Of course. It should. But the caller isn’t the control plane. The software delivery harness decides whether the request is allowed, how it executes, and what evidence is retained.
The preference gap. Developers are going to pick their own coding agents. Most enterprises already run two or three: Cursor on some teams, Claude Code on others, Copilot on others, whatever ships next year on yet other teams. That’s healthy. Software development is distributed by design. Software delivery is the opposite: it’s centralized. One company, one delivery control plane. One set of policies, one audit trail, one source of evidence, one place where credentials are held.
The winning pattern is the two meeting cleanly: whichever coding agent the developer picks, the deployment passes through the same delivery harness.
Why model providers aren’t the delivery harness today
Managed agents. Stateful APIs. Server-side memory. Model providers are extending into harness territory, and for many use cases, that works. For software delivery specifically, the architecture runs into a different set of constraints.
The credentials problem. Every software delivery action requires production credentials: cloud admin roles, Kubernetes service accounts, database passwords, secrets manager keys. The most sensitive assets in the company. Enterprises spend years building the controls around them: vaults, rotation, scoped access, audit trails. A model-provider-hosted agent loop would require those credentials to flow through the model provider’s infrastructure on every action. Few CISOs will approve it. Few auditors will sign off. In regulated industries, it’s often a non-starter.
The inversion. A model can be hosted anywhere. Any provider, any cloud. Execution has to happen inside the enterprise, using credentials that never leave. The model stays outside. The control plane runs inside. Intelligence can live anywhere. The control plane can’t.
The live-state problem. A software delivery agent’s answer to “Is this safe to ship?” depends on a state that changes every minute. The current change freeze. The latest incident. The newest CVE. Who’s on call right now. Whether the deployment window just closed. A model provider can reason about what you put in the prompt. It doesn’t naturally own the current state of your delivery system. A model provider knows the world. The harness has to know your world, right now.
The accountability problem. When a delivery agent does something wrong, the model provider isn’t on the incident bridge. The on-call engineer is. The platform lead is. The CTO is. The company is the one that has to explain the outage to customers, the finding to regulators, the miss to the board. Accountability can’t be outsourced. The harness that constrains the agent can’t be either.
A model provider can be the brain. It can’t be the harness for delivery.
AI for everything after code
More and more code will be written by AI. The bottleneck is shifting from code generation to safe delivery.
Coding agents help developers write code. Software delivery agents help teams safely deliver and operate it. Two harnesses. Two categories. Two sets of winners.
The foundation for software delivery is ready. The agents that need it are arriving now. The category now has a name.
We’ve always called it Harness. The idea just got bigger.
Harness Expands Infrastructure as Code Management with Native Terragrunt Support and Multi-IaC Innovation
- Harness IaCM introduces native Terragrunt support, enabling true enterprise-grade orchestration at scale.
- Teams can now manage Terraform, OpenTofu, and Terragrunt in a single platform without fragmented tooling.
- Built-in governance, policy enforcement, and approvals streamline secure infrastructure operations.
- End-to-end visibility and drift detection improve reliability across complex, multi-environment deployments.
- The launch marks a major step toward a unified, multi-IaC control plane for modern infrastructure teams.
Bringing First-Class Terragrunt Support to IaCM
“We’ve been operating in a hybrid environment with both OpenTofu and Terragrunt, and Harness has made it much easier to bring those workflows together into a single, consistent platform with IaCM. The addition of Terragrunt support is a valuable step toward simplifying how we manage infrastructure at scale.”
— Lead Platform Engineer, Enterprise Customer
Infrastructure as Code is now a standard for modern cloud operations, with most enterprises using IaC to provision and manage environments. However, as adoption grows, so does complexity. Teams are no longer managing a handful of environments. They are operating across multiple regions, accounts, and services, often at massive scale.
This is where traditional approaches begin to fall short.
As organizations scale their infrastructure, Terraform alone is often not enough. Teams adopt Terragrunt to manage complex, multi-environment deployments, but they are often forced to stitch together fragmented tooling that lacks visibility, governance, and consistency.
At Harness, we are changing that.
Today, we are excited to announce native Terragrunt support in Harness IaCM, bringing it to full parity with Terraform and OpenTofu while delivering capabilities that go beyond what is available in standalone tooling. This is more than support. It is about making Terragrunt a first-class platform for enterprise infrastructure management.
With Harness IaCM, teams can now:
- Orchestrate complex Terragrunt environments with full visibility across all units
- Apply cost estimation, approvals, and policy enforcement natively
- Detect and manage drift across environments with granular insights
- View infrastructure changes at the resource level across orchestrated deployments
Terragrunt has become a critical layer for managing infrastructure at scale because it simplifies how teams structure and reuse configurations across environments. Harness builds on that foundation with deep, native integration, enabling platform teams to operate with both flexibility and control.
This is especially important for enterprises where a single deployment spans multiple environments and services. Harness abstracts that complexity while maintaining governance, auditability, and consistency.
Extending IaCM to a Multi-IaC Future
Terragrunt is part of a broader shift toward multi-tool infrastructure strategies.
Modern teams are no longer standardized on a single IaC tool. Instead, they operate across:
- Terraform and OpenTofu for provisioning
- Terragrunt for orchestration
- CDK for developer-driven infrastructure
- Ansible for configuration and automation
This creates challenges around consistency, visibility, and governance. Harness IaCM is built for this reality. We are evolving IaCM into a unified control plane for multi-IaC workflows, where teams can manage different frameworks with a consistent experience, shared policies, and centralized visibility.
This means:
- Eliminating fragmented pipelines across tools
- Standardizing governance across environments
- Gaining full visibility into infrastructure state and changes
Instead of managing infrastructure in silos, teams can now operate from a single platform across the entire lifecycle.
What’s Next for Infrastructure as Code?
The next phase of Infrastructure as Code is not just about supporting more tools. It is about making infrastructure systems more intelligent and automated.
We are investing in two key areas:
Expanded IaC Support
We are continuing to support modern frameworks like AWS CDK, enabling developer-centric infrastructure workflows alongside provisioning, configuration, and orchestration tools.
AI-Driven Automation
We are introducing intelligence into IaC workflows to simplify tasks such as drift management and optimization. This helps teams reduce manual effort and operate more efficiently at scale.
Together, these investments move IaCM toward a unified, multi-IaC platform that combines flexibility, governance, and automation. Terragrunt has become essential for managing infrastructure at scale but until now, it hasn’t had a platform that truly supports it. As infrastructure continues to grow in complexity, our focus remains the same. Helping teams move faster, reduce risk, and scale with confidence no matter which IaC tools they use.

Building for Resilience: An Engineering Guide to the Mythos Era
The release of Anthropic Mythos and Project Glasswing marks an exciting and pivotal new chapter in software development. As the industry advances, the speed and economics of vulnerability exploitation have fundamentally shifted. What once took weeks of manual reconnaissance can now be scaled rapidly through automated models. However, this is not just a security problem to solve. It is a massive engineering opportunity to build cleaner, more robust systems. By leaning into AI-accelerated defense, engineering teams are uniquely positioned to lead the charge and redesign the landscape of modern software architecture.
Breaking Down Silos and Establishing Shared Accountability
To succeed in this new era, the traditional silos separating security and engineering must fall. Defense at machine speed requires a unified front.
- Organizations need a shared roadmap and accountability model across Engineering, Infrastructure, and Security.
- These roadmaps must be crafted jointly with clear responsibility assigned per action item.
- Every executive and their corresponding team will be affected and accountable for changing the way work is done.
- Preparations for these improvements should be treated exactly like new product features.
- Savvy customers will start to pay attention to companies who are responding to Mythos, turning your proactive resilience into a highly visible competitive advantage.
Core Engineering Imperatives
The foundation of AI-accelerated defense relies on sound, proactive engineering practices. Developers must take ownership of architectural hygiene from the ground up.
- Accelerate velocity: Teams must focus heavily on shortening patch and change cycles (such as with Harness CI and CD). The single most important metric is how quickly you can safely make changes.
- Shift left completely: You must find bugs before you ship code. Achieve this by integrating SAST, SCA, and auto-pen testing into a secure pipeline, and prefer using memory safe code languages.
- Design for resilience: Always build with breach assumed. In practice, this means implementing zero-trust, isolating services by identity, and using short lived tokens by default.
- Simplify the architecture: As you engineer and build for resilience and simplicity , take time to audit your current code base to reduce dependencies and standardize on known good services and libraries. Additionally, actively reduce and inventory what you expose.
- Pay attention runtime: Aside from bugs, engineering teams haven’t traditionally paid attention to the run-time security of their applications. Aside from the functional insights developers can glean from runtime security tools, understanding how a system is attacked can help you make better architectural and functionality decisions.
Planning for the Unexpected
Even with the best architecture, unexpected friction will occur. Resilient engineering means planning comprehensively for your ecosystem.
- Ensure you know your software dependencies and precisely who to contact in emergencies.
- Engineering teams should build technical work-arounds for times when providers or internal systems experience issues.
- Organizations must establish a surge defense capability. When faced with a severe situation, have a SWAT team established with pre-approved authority, budget, and standard operating procedures across domains and outside help.
- At the company level, pre-position high-visibility incident response. This includes having pre-approved and crafted messaging triggered by established conditions.
Security as an AI-Powered Partner
To keep pace with the increased velocity of engineering teams, Security teams must also evolve their operational models.
- Security needs to leverage AI to de-toil high calorie activities.
- Practical applications include putting a model in front of your alert queue and testing it regularly.
- AI should also handle the triage and prioritization of scan findings alongside ticket ops automation.
- It is crucial to automate the technical incident response pipeline.
- By automating the bookkeeping around incidents, human decisions should be made with assistance at most.
- The ultimate goal is to find places to leverage AI and accelerate the time between incident and resolution.
Leading the Charge
Engineering leaders and developers are in the perfect position to navigate this industry inflection point. By taking ownership of these structural changes today, you ensure the long-term viability of your products and the enduring strength of your codebase. Bring your security, infrastructure, and engineering teams together into the same room and start building your shared roadmap today.

Infrastructure as Code Management: Terragrunt & Multi-IaC
What happens when your Infrastructure as Code management strategy works perfectly in dev, scales reasonably well in staging, and then quietly fractures across seventeen production workspaces because nobody documented which Terragrunt wrapper goes with which AWS account? You spend Friday afternoon reverse-engineering DRY patterns that made sense six months ago, wondering why your team is managing three different IaC execution engines with four incompatible workflow philosophies.
This scenario isn't hypothetical. It's the reality of organizations that adopted IaC incrementally, layer by layer, without a unified management approach. One team standardized on OpenTofu for new infrastructure. Another maintained legacy Terraform configurations because migration felt risky. A third discovered Terragrunt and used it to wrangle complexity across AWS regions, but now those wrappers exist outside any centralized governance model. Each decision was rational in isolation. Together, they created an orchestration problem masquerading as a tooling problem.
The actual challenge isn't choosing between Terraform, OpenTofu, or Terragrunt. It's managing their outputs, enforcing policy consistently across execution contexts, and ensuring that infrastructure changes don't outpace your ability to understand what's deployed.
The Hidden Complexity of Multi-IaC Environments
Most platform teams don't set out to run multiple IaC tools simultaneously. They inherit Terraform state from acquisitions, adopt OpenTofu for licensing predictability, and introduce Terragrunt because someone needed to stop copying backend configurations across 40 AWS accounts. The tools themselves aren't the problem. The problem is that each tool introduces its own state management assumptions, module resolution logic, and workflow expectations.
Terragrunt, for instance, exists specifically to solve Terraform's verbosity problem. It lets you define backend configurations once and reference them across environments. It supports dependency graphs so you can deploy a VPC before attempting to create subnets. These capabilities are valuable, but they also mean your actual infrastructure logic now spans two layers: the Terraform or OpenTofu code that defines resources, and the Terragrunt configuration that orchestrates execution.
When you lack centralized Infrastructure as Code management, those layers drift independently. Someone updates a Terragrunt dependency graph without realizing it breaks a downstream workspace. Another engineer modifies an OpenTofu module but forgets that three different Terragrunt configurations depend on its output structure. You don't discover these issues until a deployment fails in production, and the postmortem reveals that nobody had visibility into the full dependency chain.
Why Workflow Sprawl Defeats Governance at Scale
The typical response to multi-IaC complexity is to standardize on one tool and deprecate the others. That works if you're early in your IaC journey. It's impractical if you're managing hundreds of workspaces across regulated environments where compliance audits expect immutable infrastructure definitions and audit trails for every state change.
Here's what actually happens: platform teams create custom CI/CD pipelines for each tool. Terraform runs in Jenkins. OpenTofu runs in GitHub Actions. Terragrunt configurations use a shell script someone wrote during an incident. Each pipeline implements drift detection differently. Policy enforcement exists as scattered OPA rules that don't share a common evaluation context. When an auditor asks, "How do you prevent unapproved infrastructure changes?", the honest answer is, "We run some checks in some places, and we hope teams remember to use them."
This isn't negligence. It's what emerges when Infrastructure as Code management tooling doesn't natively support the reality of polyglot IaC environments. Teams need a system that treats OpenTofu, Terraform, and Terragrunt as execution details, not architectural boundaries. The workflow layer—plan generation, policy evaluation, approval gates, state locking—should remain consistent regardless of which engine interprets the configuration.
Infrastructure Automation Tools Need Orchestration, Not Just Execution
Running `terragrunt apply` successfully doesn't mean your infrastructure is well-managed. It means Terragrunt successfully invoked OpenTofu or Terraform and applied a configuration. The actual management work—validating inputs, enforcing cost policies, detecting drift, promoting changes through environments—exists outside the execution layer.
This is where most homegrown solutions collapse under their own weight. You build a wrapper script that runs Terragrunt with the right flags. Then you add pre-commit hooks for policy checks. Then you integrate Sentinel or OPA, but only for workspaces that someone remembered to configure. Then you add Slack notifications so people know when drift occurs, but the notifications don't include enough context to act on them. Eventually, you have a Rube Goldberg machine that works until it doesn't, and debugging requires institutional knowledge that exists in one person's head.
The fundamental issue is that IaC workflow optimization requires thinking beyond execution engines. You need orchestration that understands module dependencies, workspace relationships, and policy boundaries. You need variable management that doesn't require copying YAML files between repositories. You need drift detection that runs automatically and surfaces meaningful deltas, not raw Terraform output dumped into a log file.
Terragrunt Support as a First-Class Workflow Primitive
Treating Terragrunt as an afterthought—something teams bolt onto existing Terraform or OpenTofu pipelines—misses its architectural intent. Terragrunt exists because managing backend configurations, passing outputs between modules, and orchestrating multi-account deployments shouldn't require copying boilerplate across dozens of directories. When Infrastructure as Code management platforms support Terragrunt natively, they acknowledge this reality: the DRY principle applies to infrastructure orchestration, not just resource definitions.
Native Terragrunt support means the platform understands dependency graphs without requiring custom parsing logic. It means workspace templates can reference Terragrunt configurations directly, rather than forcing teams to flatten everything into monolithic Terraform modules. It means policy enforcement applies before Terragrunt invokes the underlying execution engine, catching invalid configurations before they generate failed plans.
This matters most in organizations running multi-region or multi-cloud architectures. A typical pattern: one Terragrunt configuration defines networking across AWS regions, another manages Kubernetes clusters, a third provisions databases. Each configuration depends on outputs from the others. Without native orchestration, teams either write brittle shell scripts to sequence these dependencies or accept that deployments sometimes fail halfway through because someone applied changes out of order.
Multi-IaC Tools Require Unified State and Policy Management
The real test of an Infrastructure as Code management platform isn't whether it runs OpenTofu or Terraform. It's whether it provides consistent state visibility, policy enforcement, and audit trails across both. If your platform requires separate workflows for each execution engine, you've automated the mechanics but not the governance.
Consider policy evaluation. A reasonable security requirement: no S3 buckets should allow public read access. With fragmented tooling, you implement this rule multiple times. Once for Terraform workspaces using Sentinel. Again for OpenTofu configurations using OPA. A third time for Terragrunt-managed infrastructure, where you're not sure which policy engine applies because Terragrunt is just orchestrating calls to Terraform or OpenTofu. When an audit occurs, you can't prove consistent enforcement because there's no unified policy evaluation layer.
The same fragmentation affects drift detection. Terraform Cloud detects drift for Terraform-managed resources. Your OpenTofu workspaces might run scheduled reconciliation jobs, or they might not—it depends on whether someone configured them. Terragrunt configurations drift silently unless you've built custom tooling to periodically run `terragrunt plan` and parse the output. The result: partial visibility across your infrastructure estate, where "managed by IaC" becomes aspirational rather than descriptive.
OpenTofu Integration and Terraform Alternatives in Practice
Organizations exploring Terraform alternatives often focus on licensing or community governance. Those considerations matter, but they don't address the operational question: how do you manage infrastructure deployed with multiple execution engines without creating parallel workflow systems?
OpenTofu integration means more than "we can run OpenTofu commands." It means workspaces provisioned for OpenTofu behave identically to Terraform workspaces at the orchestration layer. Variable sets apply consistently. Policy evaluation uses the same rule sets. Drift detection runs on the same schedule. Approval workflows follow the same governance model. The execution engine becomes an implementation detail, not a workflow boundary.
This distinction matters during migrations. Teams don't flip entire infrastructure estates from Terraform to OpenTofu overnight. They migrate incrementally, starting with non-critical workspaces and expanding as confidence grows. If your Infrastructure as Code management platform treats each engine as a separate silo, you're managing two parallel systems during the transition. If the platform abstracts execution details behind a unified orchestration layer, the migration becomes a configuration change, not an architectural overhaul.
IaC Orchestration Beyond Engine Selection
The hard problems in infrastructure management aren't technical; they're organizational. How do you ensure that 40 engineers across six teams follow the same approval process for production changes? How do you enforce cost policies without blocking legitimate deployments? How do you maintain audit trails that satisfy compliance requirements without turning every infrastructure change into a bureaucratic ordeal?
IaC orchestration platforms solve these problems by decoupling policy from execution. Instead of embedding governance rules in CI/CD pipelines—where they're invisible, untestable, and easy to bypass—you define them once at the platform level. Instead of writing custom scripts to sequence Terragrunt dependencies, you describe the dependency graph declaratively and let the platform handle execution order. Instead of building bespoke drift detection logic, you configure detection schedules and let the platform surface meaningful deltas.
This approach doesn't eliminate complexity. It consolidates complexity into a layer designed to manage it. Your IaC configurations remain simple: modules that define resources, Terragrunt wrappers that eliminate boilerplate, workspace configurations that specify execution context. The orchestration platform handles everything else: state locking, policy evaluation, approval workflows, audit logging, drift remediation.
Harness IaCM: Orchestration for Multi-IaC Environments
Harness Infrastructure as Code Management approaches these challenges by treating the execution engine as a deployment detail, not an architectural constraint. Whether you're running OpenTofu, Terraform, or Terragrunt, the orchestration layer remains consistent: standardized pipelines for plan generation and apply operations, unified policy enforcement across all workspaces, centralized drift detection that surfaces actionable insights.
- Native Terragrunt support means dependency graphs defined in Terragrunt configurations are understood and respected during execution. You don't need custom scripts to sequence deployments across modules or AWS accounts. The platform interprets dependencies and orchestrates execution accordingly, applying changes in the correct order while maintaining state consistency.
- The Module and Provider Registry provides a centralized source of truth for infrastructure components, whether they're Terraform modules, OpenTofu modules, or Terragrunt configurations. Variable Sets and Workspace Templates eliminate configuration duplication, letting you define environment-specific values once and reference them across workspaces. Default plan and apply pipelines ensure consistent execution patterns without requiring custom CI/CD configurations for each workspace.
- Policy enforcement happens before execution, not after. Whether you're using Terraform, OpenTofu, or Terragrunt, policies evaluate against the generated plan before any infrastructure changes occur. Drift detection runs automatically, comparing deployed infrastructure against IaC definitions and surfacing discrepancies through a unified interface. Audit trails capture every state change, policy evaluation, and approval decision, providing the compliance evidence required in regulated environments.
For teams managing infrastructure across multiple clouds, regions, or execution engines, Harness IaCM provides the orchestration layer that makes polyglot IaC environments manageable. The platform doesn't force you to standardize on a single tool. It provides governance, visibility, and workflow consistency regardless of which engine interprets your configurations.
Governance Enables Velocity in Multi-IaC Environments
The promise of Infrastructure as Code—reproducible deployments, version-controlled infrastructure, collaborative development—only materializes when you have consistent orchestration across execution engines. Running Terraform in one pipeline, OpenTofu in another, and Terragrunt through a shell script doesn't scale. It creates workflow fragmentation that defeats governance and slows teams down.
Effective Infrastructure as Code management platforms abstract execution details behind unified workflows. They treat Terragrunt as a first-class orchestration primitive, not an afterthought. They provide native support for OpenTofu alongside Terraform, recognizing that organizations migrate gradually, not overnight. Most importantly, they enforce policy, detect drift, and maintain audit trails consistently across all workspaces, regardless of which engine runs the actual infrastructure changes.
The technical lesson: orchestration complexity belongs in platforms designed to manage it, not scattered across custom scripts and fragmented CI/CD pipelines. The operational lesson: governance doesn't slow teams down when it's embedded in the workflow rather than bolted on afterward. Multi-IaC environments are manageable when you have the right orchestration layer. Without it, you're just running tools in parallel and hoping they don't conflict.
Explore how Harness Infrastructure as Code Management handles multi-IaC orchestration, or review the technical documentation or implementation details. The product roadmap outlines upcoming capabilities for workflow optimization and policy enforcement.

Where Artifacts Find Their Home

Why GitOps for MongoDB Matters: A Case for Harness DB DevOps
The Gap: Modern DevOps Stops at the Database
Most development teams today build everything around Git, and deploy with GitOps principles.
Code sits in version controlled environments, changes go through PRs, and deployments are handled through modern CI/CD. That part is pretty standard at this point, especially when using a modern DevOps platform like Harness.
MongoDB fits into that developer world and workflow pretty naturally. Data is stored in documents that look a lot like JSON, the format many developers already use in application code and APIs. Under the hood, MongoDB stores those documents as BSON, which is essentially a binary form of JSON that supports additional data types like dates, object IDs, and binary data. That means developers get a familiar model to work with, while MongoDB gets a format that is efficient for storing and querying application data.

Looks just like JSON, with native types like ObjectId and dates powered by BSON.
The tradeoff is that structure isn’t always defined upfront. Schemas change over time, and not always in a clean or consistent way.
Collections can contain documents with different shapes. Index changes can directly impact performance. These aren’t problems on their own, but they require discipline to manage safely.
MongoDB changes are often handled outside the standard development workflow, whether that’s by developers, platform teams, or database teams.
Teams rely on application-level updates or one-off scripts to backfill data, modify structures, or create indexes. These approaches work, but they’re not always consistently versioned in Git. Execution can vary across environments, and review or validation is often informal.
The result is limited visibility into what changed, when it changed, and how it was applied. Over time, that leads to inconsistencies between environments and increased risk during deployment.
Flexibility is powerful, but without proper controls it introduces risk.
To solve this, teams need to bring MongoDB changes into the same workflow they already trust for application code: Git-driven, reviewable, and automated.
What GitOps for MongoDB Actually Looks Like
GitOps for MongoDB isn’t about changing how Mongo works. It’s about changing how changes are managed.
Instead of handling updates through scripts or application logic alone, database changes are treated like application code. Index creation, schema validation rules, and migration scripts are all defined in Git and tracked over time. This includes MongoDB’s native schema validation rules, which can be versioned and applied consistently across environments.
Changes need to go through pull requests, just like any other code change. This allows developers, platform teams, and DBAs to review what’s being modified before anything runs in an environment.
From there, pipelines handle the validation and deployment. Changes are applied consistently across environments, rather than being run manually and potentially differently each time.
In practice, this means a new field, an index, or a backfill isn’t just a script someone runs once. It’s a versioned change that can be reviewed, tested, and repeated.
This isn’t about forcing rigid schemas onto MongoDB. It’s about making changes visible, consistent, and easier to manage as systems grow.
Harness DB DevOps provides the structure to do this. With Harness, we define changes as changesets, store them in Git, and deploy them through pipelines with built-in validation and policy checks.
To demonstrate how this works, we will walk through a practical MongoDB change from start to finish.
Example: Managing a MongoDB Change End-to-End
Here’s a simple example: A team needs to add a new userPreferences field to the users collection and create an index to support a new query.
Instead of writing a script and running it manually, we define the change and commit it to Git.
1. Define the change in Git
A developer creates the update as a changeset. That includes the logic to add or backfill the new field, along with the createIndex operation needed for performance. The change is committed alongside application code, like any other update.
2. Open a pull request
From there, the change goes through a pull request. Other developers or DBAs can review what’s being changed before anything runs. If something looks off, it gets caught here instead of in production.
3. Let the pipeline take over
Once the change is approved, the pipeline takes over.
The Pipeline

Before anything gets applied, the change is validated and previewed against the target environment. This helps catch issues early, whether it’s a conflict, a bad query pattern, or something that could impact performance.
This is especially important for heavy operations like index creation on massive collections, where resource contention and performance degradation are real risks. Instead of running those changes manually, pipelines can enforce safe rollout strategies like rolling index creations across replica sets, without manual intervention.
Policies are enforced as part of that same process, with required approvals, environment rules, and other guardrails checked automatically so teams aren’t relying on someone to manually verify every step.
Once everything passes, the change is deployed through the pipeline and applied consistently across environments, moving from dev to staging to production in a controlled way. No one is logging into a database to run scripts by hand.
Now, everything is tracked. You can see what was applied, where it was deployed, when it happened, and who approved it, with a full history available if something needs to be reviewed or rolled back later.
Sound familiar? This workflow should sound a lot like application delivery, where changes are versioned, reviewed, validated before deployment, and visible after.
From Manual Oversight to Guardrails
Traditionally, database changes have been tightly controlled by DBAs. They review scripts, approve changes, and sometimes execute them manually in each environment. That model helps reduce risk, but it doesn’t scale as teams grow and release more frequently.
With a GitOps approach, that control doesn’t disappear, it moves earlier in the process.
Instead of reviewing every individual change, database teams define policies and standards up front. Those rules are then enforced automatically through pipelines. Every change must pass the same checks before it reaches an environment, without requiring manual intervention each time.
In practice, this means:
- Required approvals are enforced automatically
- Deployment rules are validated before execution
- Production environments can have stricter controls than lower environments
- Policies are applied consistently across every change
The role of the database team evolves from gatekeeper to system designer. Rather than being involved in every deployment, they define the guardrails that ensure every deployment is safe.
Developers still move quickly, but now within a controlled, repeatable system.
What Teams Actually Gain
Bringing MongoDB into a Git-driven workflow changes how teams ship.
- Faster delivery
Developers don’t wait on manual reviews or execution. Changes move through the same workflow as application code. - Consistent environments
Changes are applied the same way every time, reducing drift between dev, staging, and production. - More predictable deployments
Validation and policy checks happen before execution, catching issues earlier and reducing surprises. - Built-in auditability
Every change is versioned, reviewed, and tracked, with full visibility into what changed, when, and why.
MongoDB's flexibility doesn't eliminate the need for structure - it just shifts the responsibility for maintaining consistency from the database itself to your development processes.
If your application is managed through Git, your database should be too.

Now in Harness DB DevOps: Percona Toolkit for safer MySQL schema changes
If you've ever run an ALTER TABLE on a busy MySQL table in production, you know the feeling. The change is small. The risk isn't. Long-running table locks, queued writes, application timeouts, replication lag, a five-minute migration that turns into a half-hour incident review.
We're shipping an integration that takes that anxiety out of the loop. Harness Database DevOps now supports Percona Toolkit for MySQL as part of Liquibase-based schema management. Flip a checkbox at schema creation, and eligible changes execute through pt-online-schema-change instead of native MySQL DDL.
Why it matters
Native ALTER TABLE on MySQL can lock tables for as long as the change takes to apply. On a large or hot table, that means writes pile up, dependent services start timing out, and replicas fall behind.
Percona Toolkit handles the same change very differently. pt-online-schema-change creates a shadow table with the new schema, copies your data over in small chunks, uses triggers to keep the original and shadow tables in sync, then performs an atomic swap with minimal lock time. The practical upside: schema changes you can run during business hours, not at 2 AM with a runbook open.
How to turn it on
The integration is enabled per schema. When you create a Database Schema in Harness DB DevOps:
- Fill in your MySQL connection details.
- Select Liquibase as your schema configuration.
- Check the box labeled Use Percona Toolkit.
- Save and continue with your normal workflow.
That's it. With the box unchecked (the default), Harness DB DevOps applies your changelogs using native MySQL operations through Liquibase, exactly as before. Check it, and eligible changes route through Percona Toolkit instead.
Things worth knowing before you flip the switch
Percona Toolkit isn't a silver bullet for every DDL. A few cases need extra thought.
Adding or dropping foreign keys can break during the table swap, so plan those changes carefully or apply them outside the toolkit. Tables without a primary key or unique index won't migrate safely either, since pt-online-schema-change needs one to chunk data deterministically. And a handful of specific operations sit outside the safe-change envelope: dropping a primary key, complex column reordering, and some storage engine swaps.
You'll also want to give the database user the right privileges: ALTER, SELECT, INSERT, and UPDATE on the target table, plus CREATE and DROP on the database for shadow table management.
The full list of supported patterns, edge cases, and required permissions is in the Harness DB DevOps docs.
Try it on your next migration
If you're already running Harness DB DevOps for MySQL, the next schema you create is a good place to try this. Turn it on against a non-critical environment first, watch how it behaves on your workload, and the path to using it in production gets a lot shorter.
For teams running MySQL at scale, that's one fewer reason to schedule schema changes around your customers' sleep.
If you aren't already using Database devops, speak with our experts to discuss how you can achieve zero downtime database schema migrations.
_%20Formula%2C%20Examples%20%26%20DevOps%20Use%20Cases.png)
Mean Time to Failure (MTTF): What It Is and Why It Matters for Platform Engineering
- Mean Time to Failure (MTTF) turns repeated failures into a signal that can be predicted, allowing platform teams to plan for the number of incidents, the amount of capacity they need, and the SLOs they can actually meet.
- To get an accurate Mean Time to Failure, you need to have clean data, clear definitions of failure, and separate short-lived components from long-lived services instead of averaging everything together.
- Connecting Mean Time to Failure with MTTR, SLOs, and AI-powered automation from Harness changes how you think about failures from random chaos to an automated control loop that runs reliability.
Your production problems aren't just random. If a Kubernetes node fails every 72 hours or your CI runners crash every 4 builds, that's a clear pattern. Mean Time to Failure (MTTF) turns these failures into data that you can control, plan for, and improve over time.
MTTF should not be a decoration on a dashboard for platform engineering leaders; it should be a decision-making tool. With the right calculations, you can set realistic SLOs, plan capacity, and cut down on developer work by focusing on the parts that break the most often. You'll get exact formulas for distributed systems, data collection patterns that avoid common mistakes, and a playbook to turn reliability improvements into measurable ROI through automated resilience practices alongside faster recovery metrics.
Stop letting unpredictable failures drain your team's time and budget. With Harness Continuous Integration and Continuous Delivery, you can turn MTTF insights into concrete pipeline changes, progressive delivery strategies, and guardrails that keep reliability improving release after release.
What Is Mean Time to Failure (MTTF)?
Mean Time to Failure (MTTF) is the average operating time of non-repairable components before failure across a population.
At a basic level:
MTTF = total operating time ÷ number of failures
If 100 CI runners each run for 50 hours during a week (5,000 runner‑hours total) and 20 runners experience at least one hard failure, then:
MTTF = 5,000 ÷ 20 = 250 hours
Historically, MTTF is used for physical assets you replace instead of fix (light bulbs, disks, sealed devices). In software, the same concept fits ephemeral resources such as:
- Short‑lived containers and pods.
- CI/CD job runners and build agents.
- Batch jobs and serverless functions that are recreated after failure.
MTTF tells you how long things run, on average, before they fail and must be replaced. MTTF is an approximation, not a strict reliability model.
MTTF vs MTTR vs MTBF in DevOps Workflows
Three reliability metrics show up in every platform review:
- Mean Time to Failure (MTTF): Measures how long non‑repairable or ephemeral components run before failing and being replaced.
- Mean Time to Repair/Restore (MTTR): Measures how long it takes to restore a service to healthy operation after a failure.
- Mean Time Between Failures (MTBF): Measures how much uptime you get between failures for systems that are repaired and returned to service.
Use them to answer different questions:
- MTTF: How often do our ephemeral components fail?
- MTTR: How quickly can we restore user‑visible services when they do?
- MTBF: How stable are our long‑lived systems between failures?
For example:
- Track MTTF for pod lifetimes or CI runner stability so you can forecast incident volume and choose when to add redundancy or auto‑healing.
- Track MTTR for customer‑facing services and tie it to SLOs and incident response.
- Track MTBF for databases or API gateways so you can plan maintenance windows and capacity around real behavior instead of theoretical SLAs.
Your platform scorecards should display all three together, alongside SLO health and error budget burn, so teams see the full reliability picture instead of optimizing a single metric in isolation.
When MTTF Applies to Software
The theoretical rules around MTTF and MTBF are straightforward; the ambiguity comes when you apply them to real cloud‑native stacks. Concrete examples help.
Where MTTF is Most Meaningful
These components typically behave like non‑repairable items:
- Pods and containers that are recreated on failure.
- CI runners and ephemeral build agents that are provisioned per job or per batch.
- Batch jobs and workers that run to completion and are never “repaired” mid‑flight.
- Serverless functions are triggered on demand and recreated automatically.
For each of these, you can treat a single lifecycle (from start to failure/termination) as one observation in your MTTF dataset.
Where MTBF (Plus MTTR) is A Better Fit
These components behave more like classic repairable systems:
- Databases and stateful services that are brought back through restart, patch, or failover.
- API gateways, control planes, and load balancers that remain logically continuous across many incidents.
- Long‑running worker pools that survive node or pod replacements.
For these, you care more about how much uptime you get between failures (MTBF) and how quickly you can restore full health (MTTR).
The Common Pitfall: Equating Infra MTTF With User Reliability
It is tempting to say “our nodes have an MTTF of 720 hours, so our service is very reliable.” That is only true if your architecture masks those failures from users. User‑facing reliability lives at the service boundary, measured via SLOs and error budgets; component MTTF is an input that helps you:
- Find noisy dependencies.
- Plan redundancy and failover.
- Decide where to add automation or chaos tests.
MTTF helps you understand where things break; SLOs and MTTR tell you how much that matters to customers.
How to Calculate MTTF for Distributed Systems
The MTTF calculation is trivial. The work is in collecting honest data across a distributed system without losing important details.
1. Define Specific Failure Events
For each component type, decide exactly what counts as “failed,” for example:
- Container exits with a non‑zero status.
- Pod enters CrashLoopBackOff or is evicted for resource pressure.
- CI pipeline reaches a terminal “failed” state (not just retried).
- Node is in NotReady for longer than an agreed threshold.
Document these in your platform taxonomy so every team logs and reports failures the same way.
2. Track Lifecycle Start and End for Each Instance
For each instance in the population you’re measuring, capture:
- Start time – when the instance began its lifecycle.
- End time – either the failure time or the end of your observation window.
- Instance identifier – pod name, job ID, runner ID, etc.
Then compute:
MTTF = total operating time across all instances ÷ number of failed instances
This gives you MTTF for that class (e.g., “Linux GPU runners in prod”).
3. Segment by Workload Class and Aggregate With Weights
Never pool dissimilar components into a single MTTF number. Instead:
- Group instances into workload classes (service, environment, hardware profile, or usage pattern).
- Compute MTTF for each class independently.
- When needed, roll up with weighted exposure hours, not a simple average.
Example:
- Class A: 1,000 hours, 5 failures → MTTF_A = 200 hours.
- Class B: 100 hours, 1 failure → MTTF_B = 100 hours.
Fleet MTTF (weighted) = (1,000 + 100) ÷ (5 + 1) ≈ 183 hours, not the naive (200 + 100) ÷ 2.
4. Include Right‑censored Data
Some instances will still be running when you take the snapshot. If you drop them:
- You shrink total operating time.
- You keep the same number of failures.
- Your MTTF ends up artificially low.
When censored samples are common, use basic survival analysis (like Kaplan–Meier) so that "still running" instances add to the exposure instead of being thrown away. If you give them clear timestamps and labels, observability tools and data teams can usually take care of this for you.
Using MTTF to Set SLOs and Reduce Toil
MTTF becomes strategically important when you use it to shape SLOs, error budgets, and reliability investments, not just track uptime.
1. Project Incident Volume From MTTF
If a class of components has an MTTF of 72 hours, a single instance will fail about:
8,760 hours/year ÷ 72 ≈ 121 failures/year
With multiple instances and redundancy, not every failure becomes a user‑visible incident, but you can still estimate:
- Roughly how many failures will your platform team see?
- How often will those failures stress specific SLOs or error budgets?
2. Prioritize Components That Generate the Most Toil
MTTF highlights which components generate excessive manual work:
- A CI runner class with low MTTF forces engineers to babysit builds.
- A particular pod type that fails often might drive a disproportionate share of pages.
Use this to:
- Rank components by failure frequency × human touch time.
- Focus on resilience and automation work where you retire the most pages and tickets per unit effort.
3. Translate MTTF improvements into business outcomes
Because MTTF underpins incident rates, any improvement can be tied to measurable gains:
- Fewer incidents and on‑call pages.
- Less time lost to debugging failures that do not reach customers.
- Less need for excess capacity added as a buffer against frequent failures.
Treat MTTF as a leading indicator: when you raise it on critical components, you should see downstream improvements in SLO attainment and delivery cadence.
Practical Ways to Improve Mean Time to Failure
Once you know which components have the lowest MTTF and the highest operational cost, you can systematically improve them. In modern delivery pipelines, four patterns tend to pay off quickly.
1. Stabilize CI Pipelines and Build Infrastructure
Flaky CI is one of the most common sources of low MTTF and wasted engineering time.
You can improve CI‑related MTTF by:
- Reducing test‑driven failures with Harness Test Intelligence, which selects only tests relevant to a change and helps you isolate flaky tests instead of letting them hammer your MTTF.
- Identifying failure hot spots using Harness CI analytics and insights to see which repos, branches, or services correlate with most build failures.
- Shortening build exposure windows using incremental builds, which reuse previous build outputs, reducing the time during which build infra can fail.
Result: higher MTTF for pipelines and runners, fewer broken builds, and fewer interruptions for developers.
2. Use Progressive Delivery and Rollback to Protect Service MTTF
You cannot prevent every bad change, but you can limit how many become full‑blown incidents that count against your service‑level MTTF.
Key tactics:
- Design for redundancy across environments with Harness “deploy anywhere”, so a single node or zone failure does not reset service health.
- Configure canary, blue‑green, or rolling strategies in Harness “powerful pipelines” so new versions are exposed gradually and can be rolled back quickly.
- Wire in verification steps so bad versions are caught early rather than after a significant SLO hit.
This keeps effective MTTF for user‑facing services higher, even if underlying components still fail regularly.
3. Enforce Reliability Guardrails With Pipeline Governance
Many MTTF regressions start as “just one more config change” that slips past informal reviews. Prevent those with:
- Policy‑as‑code in Harness DevOps pipeline governance, where you define rules around high‑risk changes, mandatory checks, and SLO states.
- Conditional approvals for changes that touch historically fragile services or dependencies.
- Blocks on deployments when key reliability gates, like SLO burn or unresolved incidents, are breached.
This ensures the MTTF gains you’ve earned are not eroded by ad‑hoc changes and one‑off exceptions.
4. Continuously Validate Resilience With Chaos Engineering
To sustainably raise MTTF, you need confidence that your architecture and runbooks can handle real failures, not just happy‑path tests.
By running targeted chaos experiments on the components with the lowest MTTF, you can:
- Discover previously hidden failure modes.
- Fix them before they cause production incidents.
- Demonstrate to stakeholders how your changes improve resilience over time.
Monitoring and Improving MTTF with AI‑Powered Automation
When failures happen, MTTF tells you how often they occur. AI‑powered automation helps you decide what to do next—fast—so more failures stay under control and never become major incidents.
AI‑assisted Detection and Rollback
Harness AI‑assisted deployment verification analyzes metrics and logs during and after each deployment:
- It learns what “normal” looks like for each service.
- It flags anomalies in latency, error rates, or custom SLO indicators.
- It can recommend or trigger rollback directly through your CD pipelines.
The result is fewer deployments turning into user‑visible failures and a higher effective MTTF for your services, because many problematic changes are automatically rolled back before customers notice.
On the CI side, AI‑driven analysis works with Test Intelligence and analytics to:
- Cluster failures by likely root cause.
- Surface patterns, such as a particular dependency, test suite, or environment causing repeated failures.
- Guide you toward changes that will increase MTTF for builds and jobs.
SLO‑driven Guardrails Instead of Ad‑hoc Decisions
SLOs and error budgets turn raw data into rules. Instead of making teams watch dashboards and make decisions on their own, you can:
- Use SRM to set SLOs for important services and keep an eye on how much of the error budget is being used.
- Set up pipeline rules that automatically slow down or stop deployments when SLOs are in danger.
- Direct engineering efforts toward services with a decreasing MTTF and an increasing error-budget burn.
This completes the cycle: MTTF informs SLO design. Guardrails are based on SLOs, and AI-powered verification and rollbacks work on those guardrails at machine speed.
Want to turn MTTF insights into automated reliability improvements?
Explore Harness CI/CD to reduce failure rates, enforce guardrails, and improve SLO performance.
MTTF: Frequently Asked Questions (FAQs)
MTTF can feel abstract until you have to justify reliability decisions or explain incident patterns to stakeholders. These FAQs break down the most common questions practitioners ask about MTTF and how it relates to other reliability metrics.
How is MTTF different from MTBF?
MTTF is the average time it takes for a group of parts, like pods or temporary CI runners, to fail in a way that can't be fixed. MTBF tells you how long systems you fix and put back into service, like databases or long-running services, are up and running before they break down again.
When should I use MTTF instead of MTTR?
When you need to know how often failures happen so you can plan for redundancy or auto-healing, use MTTF. Use MTTR to find out how quickly you can fix services that users can see after they go down. Both metrics work together and are usually used to help make decisions about SLOs and error budgets.
Can I trust MTTF if I only have a few failures?
MTTF estimates are very uncertain when there aren't many failures. To make the number more reliable, put similar workloads together, add up the exposure hours for each class, and think of MTTF as a range or trend instead of a single point. If a part didn't fail in your window, don't assume that it will never fail; instead, treat that as incomplete data.
What data quality issues most often skew MTTF?
Most of the time, MTTF is skewed by dropping instances that are still running when the measurement is taken (right-censoring), combining environments (staging, load, and production) into one metric, and having different or unclear definitions of failure across teams. Fixing these problems usually makes MTTF more useful than any other advanced statistical method.
When is MTTF the wrong metric for modern platforms?
MTTF doesn't work when failures are very similar or when you're measuring systems that are fixed instead of replaced. In those cases, MTBF and MTTR, when looked at through SLOs and error budgets, usually give better advice than just one MTTF value.
How does MTTF connect to business outcomes?
When the MTTF is higher on important parts, there are fewer problems, fewer pages, and less time lost by developers fixing them. You can link improvements directly to faster safe release velocity, lower downtime risk, and lower operational costs when you combine MTTF with SLOs, error budgets, chaos engineering, and AI-powered automation.

Shift Left, Protect Right: How Harness + Wiz Close the AppSec Gap
Modern application security goes from code to runtime. Vulnerabilities are found at every stage of the software development lifecycle (SDLC) - in the code developers write, open source packages they pull in, container images they build, and cloud infrastructure where it all runs. But finding vulnerabilities is no longer enough. With attack surfaces sprawling across pipelines, registries, and production environments, the harder problem is fixing the vulnerabilities that actually matter.
Understanding what’s important increasingly depends on correlating multiple data points. A critical CVE buried in a dependency looks very different depending on whether the vulnerable function is actually reachable, the library is used in production, or the affected service is internet-facing. Without runtime context, security and development teams are often left triaging noise instead of actually reducing risk. And fixing vulnerabilities discovered in production can be challenging without being able to follow the trail back to the repo and line of code where the vulnerability can be found.
No matter where application security lives in your organization - and increasingly, it lives in more than one place - Harness and Wiz are working together to make sure you're covered. Whether your team is shifting left from cloud security or pushing right from the development pipeline, integrating Harness and Wiz brings code and runtime findings together so you always have the context you need to act.
Shift Left, Protect Right. Who Owns Application Security?
Application security used to have a clear owner. The AppSec team ran the scanners, triaged findings, and created tickets for developers. But "shift left" has been pushing security earlier into the development process and ownership has been migrating toward the teams that actually write and ship code. Today, the DevSecOps or platform engineering team owns application security tooling in many organizations. They're the ones who know exactly where a vulnerability lives in code, who owns it, and how to get developers to fix them.
But as applications move to the cloud, cloud security and infrastructure teams have a stake in application security outcomes as well. They're the ones with visibility into what's actually running in production - what's internet-facing, what's over-privileged, what's actively being exploited. Cloud security platforms have expanded their focus from purely infrastructure and runtime back through the SDLC to code. For many cloud teams, application security isn't a handoff; it feeds into their cloud risk picture.
The result is that application security now has multiple stakeholders with different vantage points. DevSecOps teams see risk through the lens of the CI/CD pipeline and the developer workflow. Cloud security teams see it through the lens of the deployed environment and the blast radius of a breach. Neither view is complete on its own. The good news is that these teams don't have to choose between their tools or their workflows. They need integration that lets each team work in their context while sharing the signals that make both more effective.
Integrating Wiz Code into CI/CD Pipelines with Harness STO
DevSecOps teams need to expand right. SAST and SCA tools often generate more findings than any team can fix. Runtime context helps separate signal from noise. Knowing that a vulnerable service is actively internet-facing or that a dependency with a critical CVE is actually loaded in production changes how a team prioritizes. Without it, developers are left triaging based on CVSS scores alone. With it, they can focus effort where exposure is real and the risk in production is highest.
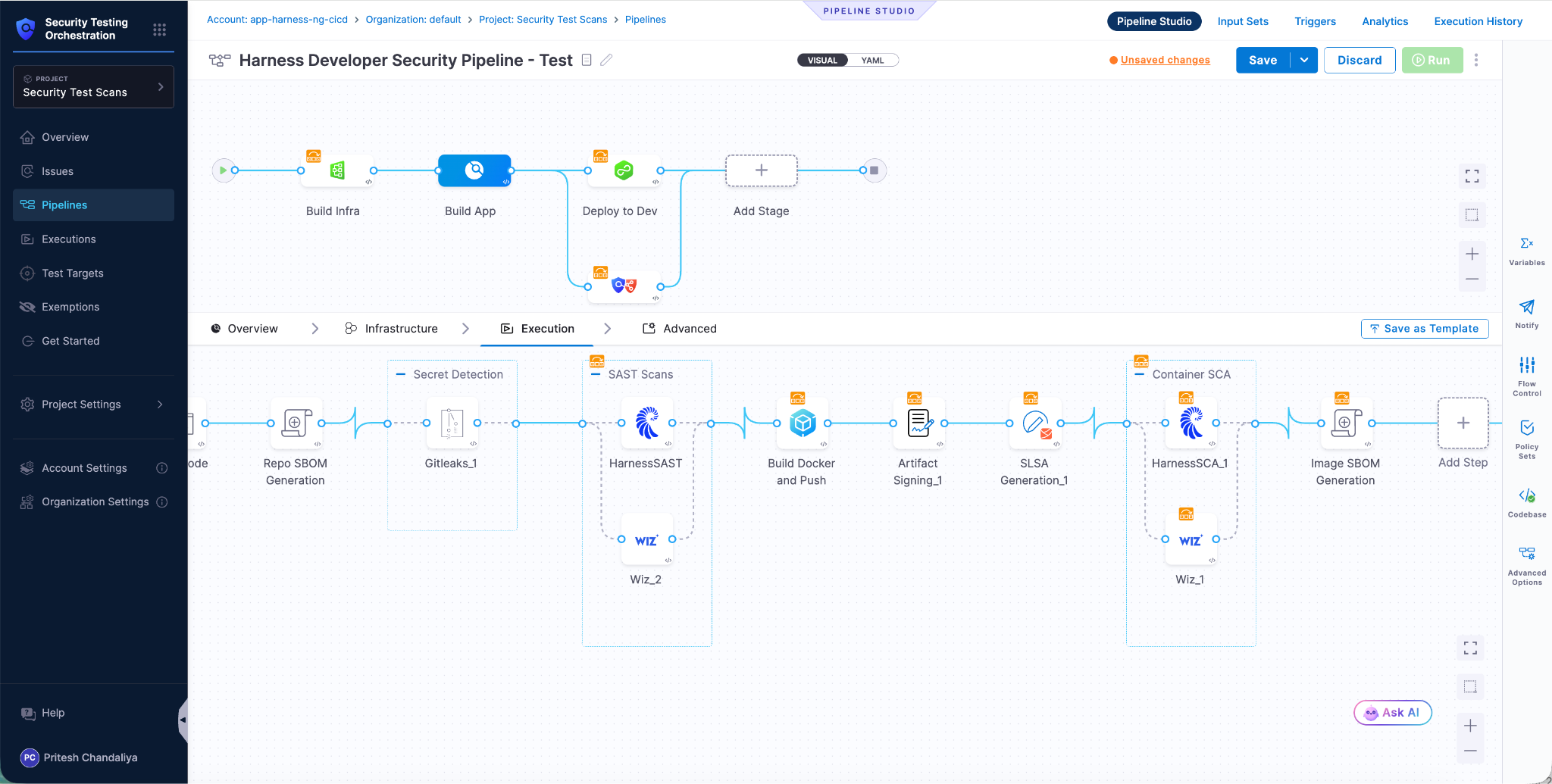
Harness Security Testing Orchestration (STO) makes it easy to orchestrate Wiz Code across your CI/CD pipelines. With a pre-built integration, you can deploy Wiz Code in just a few clicks instead of needing to create a custom integration or write custom scripts. Harness orchestrates Wiz Code alongside all your other scanners so you know your pipelines always get the required security tests, without needing to manually coordinate multiple tools.

Once Wiz Code is integrated, STO aggregates findings with other scanners in your pipeline, automatically deduplicating vulnerabilities so teams aren't triaging the same issue twice. The consolidated view means developers and security engineers can see the full picture in one place, understanding pipeline-level risk and assigning tickets to developers. In addition, Harness Policy as Code lets teams define and take action at the pipeline level instead of tool by tool, so decisions about what to fail a build on, what to flag for review, and what to pass through are applied consistently and holistically across every scan and pipeline.
Feeding Harness SAST and SCA Findings Into Wiz
Cloud security is pushing left - past runtime, past containers, all the way back to the code and open source packages that vulnerabilities originate from. The driver is enabling action. A misconfigured cloud resource or a vulnerable container image is more actionable when you can tie it back to the specific dependency introduced in a pull request, the developer who owns the code, and the pipeline that shipped it. Runtime findings without code context are just alerts. With code context, they become actionable work items that can be routed to the right person and fixed at the source.
Wiz Application Security Posture Management (ASPM) is designed to aggregate findings from across the SDLC and correlate them with runtime context - what's deployed, what's exposed, and what's actually at risk. By integrating Harness SAST and SCA scanner findings directly into Wiz, cloud security teams can connect the dots between a vulnerable open source package or insecure code pattern and the running workloads it affects. That correlation is what turns a list of CVEs into a prioritized risk picture that reflects what's actually happening in production.
For cloud security teams already working in Wiz, this integration means Harness SAST and SCA become part of their existing workflow rather than a separate tool to check. Code-level findings surface alongside runtime signals in the same platform where cloud risk is already being managed, analyzed, and acted on. Teams get broader coverage without adding friction, and the context that makes those findings meaningful - reachability, exposure, business criticality - is already there when they need it.
AppSec Is a Team Sport. Your Tools Should Be Too.
DevSecOps and cloud security teams are not generally not competing - they're looking at risk from different angles. One team lives in the development pipeline; the other lives in the cloud. Both need visibility into what the other sees to do their jobs well. When those views are siloed, findings get duplicated, priorities diverge, and the vulnerabilities that matter most fall through the cracks between teams.
Harness and Wiz close that gap from both directions. DevSecOps teams get runtime signals from Wiz Code inside the pipeline context where they already work, so they can prioritize fixes based on real-world exposure. Cloud security teams get code-level findings from Harness SAST and SCA inside the risk context where they already work, so they can trace production risk back to its source. Each team keeps their workflow. Both teams get the full picture.
The right combination of these integrations depends on how your organization is structured, where application security ownership sits today, and where you want it to go. If you're a Wiz customer evaluating how Harness SAST and SCA fit into your security program, or a Harness customer looking to bring runtime context into your pipelines, contact your Harness account team to understand how you can map the integrations to your specific environment.

Eliminate Manual Authentication Configuration for Fast & Effective API Security Scanning
Application security testing tools promise coverage and accuracy, but teams often struggle just to get started. One of the biggest friction points in dynamic application security testing is configuring authentication correctly so a scanner can even access a target application, let alone API endpoints that power the functionality.
Whether it’s API keys, bearer tokens, or custom auth flows, setting up authentication for scans frequently requires trial-and-error and engineering support. This reality of scanning configuration slows down security validations, delays insights, and makes it difficult to integrate with AI-driven tooling that depends on fast, accurate access to API endpoints.
Today, we’re excited to introduce AI-Powered Custom Authentication Generation—a new capability designed to eliminate this friction and help teams move from setup to security insights faster than ever.
What’s New: AI-Powered Authentication Generation
With this release, teams can now generate and refine authentication configurations using natural language and LLMs. Instead of manually configuring authentication logic or relying on additional support, users can simply describe their requirements and let AI handle the rest.
The average time to configure authentication for API security testing is measured in seconds, whereas older manual approaches can take hours and require extensive trial-and-error.
Here are a few highlights:
- Use Natural Language to Create Auth Scripts: Generate fully functional authentication configurations by describing your needs in plain English.
- Support for Common Auth Types: Easily create configurations for API keys, JWTs, Bearer tokens, and more.
- Iterative Refinement with AI: Update and fine-tune authentication logic by prompting the system instead of time-consuming scripting or manual adjustments.
- Inline Visibility and Change Tracking: Steps taken by AI to generate auth flows are audited, and testing runs are logged fully to maintain transparency and control.
Why is Authentication Setup Difficult Historically?
Authentication setup has long been one of the most frustrating parts of security scanning. Access control mechanisms are already complex due to security hardening used to protect applications and APIs. Successfully automating authentication flows so a machine can access an app or endpoint raises the bar substantially.
Some of the common pain paints include:
- Manual configuration slows down work: Teams often need to consult different documentation, dashboards, and code to define authentication flows correctly. Even small mistakes can cause scans to fail silently or produce incomplete results.
- Lack of standardization creates confusion: Each application or API may use slightly varied access control mechanisms and authentication material, including headers, tokens, cookies, and custom flows. Practitioners must rebuild the logic from scratch each time due to inconsistent implementation.
- Iteration is painful and time-consuming: If something doesn’t work, fixing it usually requires manually editing scripts, rerunning scans, and debugging errors. Oftentimes, additional help from support or engineering teams is needed.
- Limited visibility makes troubleshooting harder: When authentication fails, it’s not always clear why. Without clear feedback or context, teams spend valuable time diagnosing issues rather than improving their security posture.
What should be a simple prerequisite, gaining authenticated context into an application, becomes a major bottleneck to dynamic application security testing.
How AI-Powered Authentication Changes the Game
The new AI-powered authentication feature in Harness API Testing removes these barriers entirely by reworking how authentication config is created and managed.
Generate Authentication in Seconds
Users can navigate to the authentication configuration page, select the custom option, and simply describe what they need. For example:
“Generate an API key-based authentication hook where the token <token> is injected into the request header <authorization>.”
With a single click on “Generate with AI,” the system produces a complete, ready-to-use authentication script. This functionality eliminates the need to write or stitch together configurations manually.
Support for Multiple Authentication Types
The feature supports a range of common authentication mechanisms, including:
- API key-based authentication
- JWT-based authentication
- Bearer token authentication
This flexibility ensures teams can quickly configure access regardless of how their application or API is secured. Learn more details about the supported authentication types.
Refine Without Rewriting
Authentication requirements often evolve. Instead of starting over, users can iteratively refine their configurations using natural language prompts.
For example, if you want to change how credentials are injected into the auth flow, you can simply say:
“Change the injection type to header name.”
By selecting “Refine with AI,” the system updates the existing configuration accordingly—no manual edits required.
Built-In Transparency
Every AI-generated or modified configuration includes inline comments that explain what changed. These comments make it easier for teams to:
- Understand how authentication is implemented
- Review updates confidently
- Maintain control over their configurations
Additionally, no credentials are stored in logs or persisted in prompts. Any sensitive authentication material is masked and encrypted at rest.
Faster, More Reliable Scans
By reducing setup errors and simplifying authentication configuration, this Harness API Testing feature directly improves scan success rates. Teams can spend less time troubleshooting authentication issues and more time analyzing real security findings.
Unlocking Faster, Smarter Security Workflows
This release is more than just a usability improvement. It’s a foundational step towards enabling AI-driven security workflows.
By removing the friction of authentication setup, teams can:
- Onboard new applications for testing faster
- Integrate seamlessly with AI-powered testing and analysis tools
- Reduce dependency on manual scripting and support interventions
- Achieve more consistent and reliable scan coverage
Ultimately, this translates to a faster time-to-value and a more scalable approach to dynamic application security testing.
Get Started Today
AI-Powered Custom Authentication Generation is available immediately with your existing Harness subscription. You can find related technical documentation here.
Current Customers: Log in to your dashboard today to start exploring your threat data in a whole new dimension.
New to the Platform? If you aren't yet protected, contact us to schedule a personalized demo.

What if your Legal moved as fast as your business? At Harness, ours does!
There is a version of the Legal team that exists in most companies: thorough, careful, and quietly overwhelmed. Good lawyers are spending their days on tasks that really should not require a lawyer at all.
We decided early on that this was not the team we wanted to be.
At Harness, the AI-first approach is not just saved for the engineering team. It is how every team operates, including Legal. That means we stopped asking “should we use AI?” a long time ago and started asking “how do we build with AI?” The result is a Legal team that does not just use AI tools. It develops them. We close faster, advise smarter, and frankly, have more fun doing it!
Our AI legal stack
Every tool in our stack has a job. Here is what that looks like in practice:
- Contract review and redlining: This is where we are headed this year. The vision: we work from our own templates, so AI already knows what good looks like. It runs the first review, benchmarks the contract against our standards, and surfaces only the deviations worth our attention. Not every deviation is a problem. We focus on the relevant ones.
- Legal research: Finding the relevant law (the correct statute, regulation, or court decision) for a specific situation is the real challenge, not just finding the general law itself. Our AI tools are trained on comprehensive legal datasets to quickly filter out irrelevancies, ensuring we arrive at the precise answer faster and are supported by verifiable sources.
- Knowledge management: We are building a system where years of institutional know-how live in searchable, AI-powered playbooks, giving teams across Harness answers to common legal questions instantly, without filing a request or waiting for a callback.
- Data discovery and privacy compliance: Before you can be compliant, you need to know what you are actually dealing with. We use AI to discover and map all data currently being processed across the business: what it is, where it lives, and how it flows. That visibility makes it possible to track, manage, and meet our legal obligations, including privacy requirements for personal data.
- M&A project management: An AI-assisted platform provides a secure, structured home for our M&A work. When the pace picks up and the details multiply, nothing falls through the cracks.
- Regulatory compliance intake: Every new product goes through a single AI-assisted form before launch. Privacy, AI regulation, cybersecurity, accessibility: one entry point, no gaps.
- Building AI agents: This is the part most people do not expect. Our lawyers are not just using AI. They are learning to build with it, developing agents that handle specific legal tasks end-to-end. We are not waiting for the legal tech market to catch up with what we need. We are building it ourselves.
What it actually changes
The honest answer: the relationship between Legal and the rest of the business.
Turnarounds that used to take days take hours. Quality has gone up, not down. And because teams can self-serve answers to routine questions through our Legal Playbooks, the requests that do reach us are the ones that genuinely need us. We spend less time being a checkpoint and more time being a partner. That is a different job, and a more meaningful one.
We take the guardrails seriously
Moving fast with AI does not mean being reckless about it:
- Every output gets reviewed by a qualified attorney before it goes anywhere.
- We only use approved, enterprise-grade tools.
- Sensitive data never touches a public AI model.
- And we treat every AI-generated output as a starting point, not an answer, checking it against real sources before we rely on it.
What makes this more than a policy is the culture around it. We run regular sessions where the team shares what they are learning: tools worth trying, prompting approaches that actually work for legal drafting, and ways to get more out of what we already use. When one person figures something out, everyone benefits. That collective curiosity is what stops this from becoming shelfware and keeps it genuinely evolving.

If this is what Legal looks like at Harness, imagine the rest.
Every team here operates this way. Not because they are told to, but because it is genuinely a better way to work. If you are looking for a company where AI is woven into how things actually get done, not just what gets announced, we are hiring!
The Modern Software Delivery Platform®
Need more info? Contact Sales