
Kubernetes cost overruns usually come from small, invisible scheduling decisions—not the platform itself. Over-provisioned requests, poor bin packing, and fragmented node pools quietly waste cloud spend. Cost-aware scheduling, right-sizing, and smarter node selection can deliver major savings without hurting performance. Treat cost as a first-class metric with visibility into why scaling decisions happen—not just when.
Kubernetes is a powerhouse of modern infrastructure — elastic, resilient, and beautifully abstracted. It lets you scale with ease, roll out deployments seamlessly, and sleep at night knowing your apps are self-healing.
But if you’re not careful, it can also silently drain your cloud budget.
In most teams, cost comes as an afterthought — only noticed when the monthly cloud bill starts to resemble a phone number. The truth is simple:
Kubernetes isn’t expensive by default.
Inefficient scheduling decisions are.
These inefficiencies don’t come from massive architectural mistakes. It’s the small, hidden inefficiencies — configuration-level choices — that pile up into significant cloud waste.
In this post, let’s unpack the hidden costs lurking in your Kubernetes clusters and how you can take control using smarter scheduling, bin packing, right-sizing, and better node selection.
The Hidden Costs Nobody Talks About
Over-Provisioned Requests and Limits
Most teams play it safe by over-provisioning resource requests — sometimes doubling or tripling what the workload needs. This leads to wasted CPU and memory that sit idle, but still costs money because the scheduler reserves them.
Your cluster is “full” — but your nodes are barely sweating.

Low Bin-Packing Efficiency
Kubernetes’s default scheduler optimizes for availability and spreading, not cost. As a result, workloads are often spread across more nodes than necessary. This leads to fragmented resource usage, like:
- A node with 2 free cores that no pod can “fit” into
- Nodes stuck at 5–10% utilization because of a single oversized pod
- Non-evictable pods holding on to almost empty nodes

Wrong Node Choices (Intel vs AMD, Spot vs On-Demand)
Choosing the wrong instance type can be surprisingly expensive:
- AMD-based nodes are 20–30% cheaper in many clouds
- Spot instances can cut costs dramatically for stateless workloads up to 70%
- ARM (e.g., Graviton in AWS) can offer up to 40% savings
But without node affinity, taints, or custom scheduling, workloads might not land where they should.
Zombie Workloads and Forgotten Jobs
Old cron jobs, demo deployments, and failed jobs that never got cleaned up — they all add up. Worse, they might be on expensive nodes or keeping the autoscaler from scaling down.
Node Pool Fragmentation
Mixing too many node types across zones, architectures, or families without careful coordination leads to bin-packing failure. A pod that fits only one node type can prevent the scale-down of others, leading to stranded resources.
Always-On Clusters and Idle Infrastructure
Many Kubernetes environments run 24/7 by default, even when there is little or no real activity. Development clusters, staging environments, and non-critical workloads often sit idle for large portions of the day, quietly accumulating cost.
This is one of the most overlooked cost traps.
Even a well-sized cluster becomes expensive if it runs continuously while doing nothing.
Because this waste doesn’t show up as obvious inefficiency — no failed pods, no over-provisioned nodes — it often goes unnoticed until teams review monthly cloud bills. By then, the cost is already sunk.
Idle infrastructure is still infrastructure you pay for.
Smarter Scheduling: Cost-Aware Techniques
Kubernetes doesn’t natively optimize for cost, but you can make it.
Bin Packing with Intent: Taints, Affinity, and Custom Schedulers
Encourage consolidation by:
- Using taints and tolerations to isolate high-memory or GPU workloads
- Applying pod affinity/anti-affinity to co-locate or separate workloads
- Leveraging Cluster Orchestrator with Karpenter to intelligently place pods based on actual resource availability and cost
- Use Smart Placement Strategies to place non-evictable pods efficiently
In addition to affinity and anti-affinity, teams can use topology spread constraints to control the explicit distribution of pods across zones or nodes. While they’re often used for high availability, overly strict spread requirements can work against bin-packing and prevent efficient scale-down, making them another lever that needs cost-aware tuning.
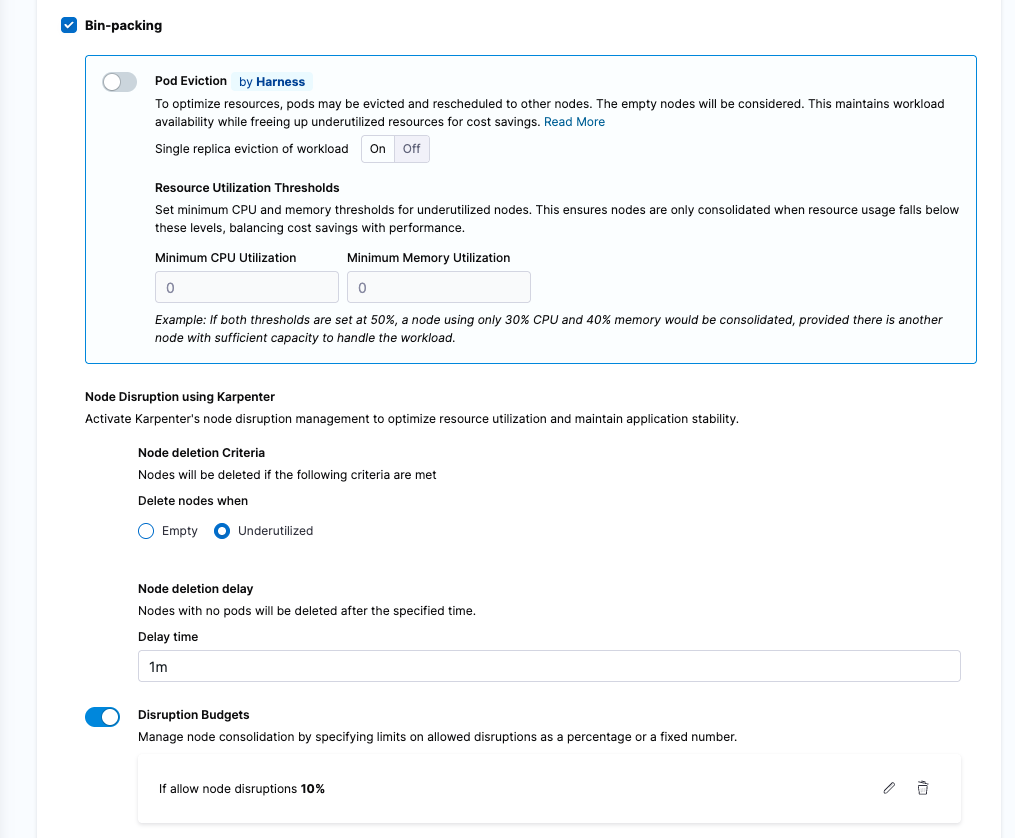
Scheduled Scaledown of Idle Resources
All of us go through a state where all of our resources are running 24/7 but are barely getting used and racking up costs even when everything is idle.A tried and proved way to avoid this is to scale down these resources either based on schedules or based on idleness.
Harness CCM Kubernetes AutoStopping let’s you scale down your Kubernetes workloads, AutoScaling Groups, VMs and many more based on either their activity or based on Fixed schedules to save you from these idle costs.
Cluster Orchestrator can help you to scale down the entire cluster or specific Nodepools when they are not needed, based on schedules
Right-Sizing Workloads
It’s often shocking how many pods can run on half the resources they’re requesting. Instead of guessing resource requests:
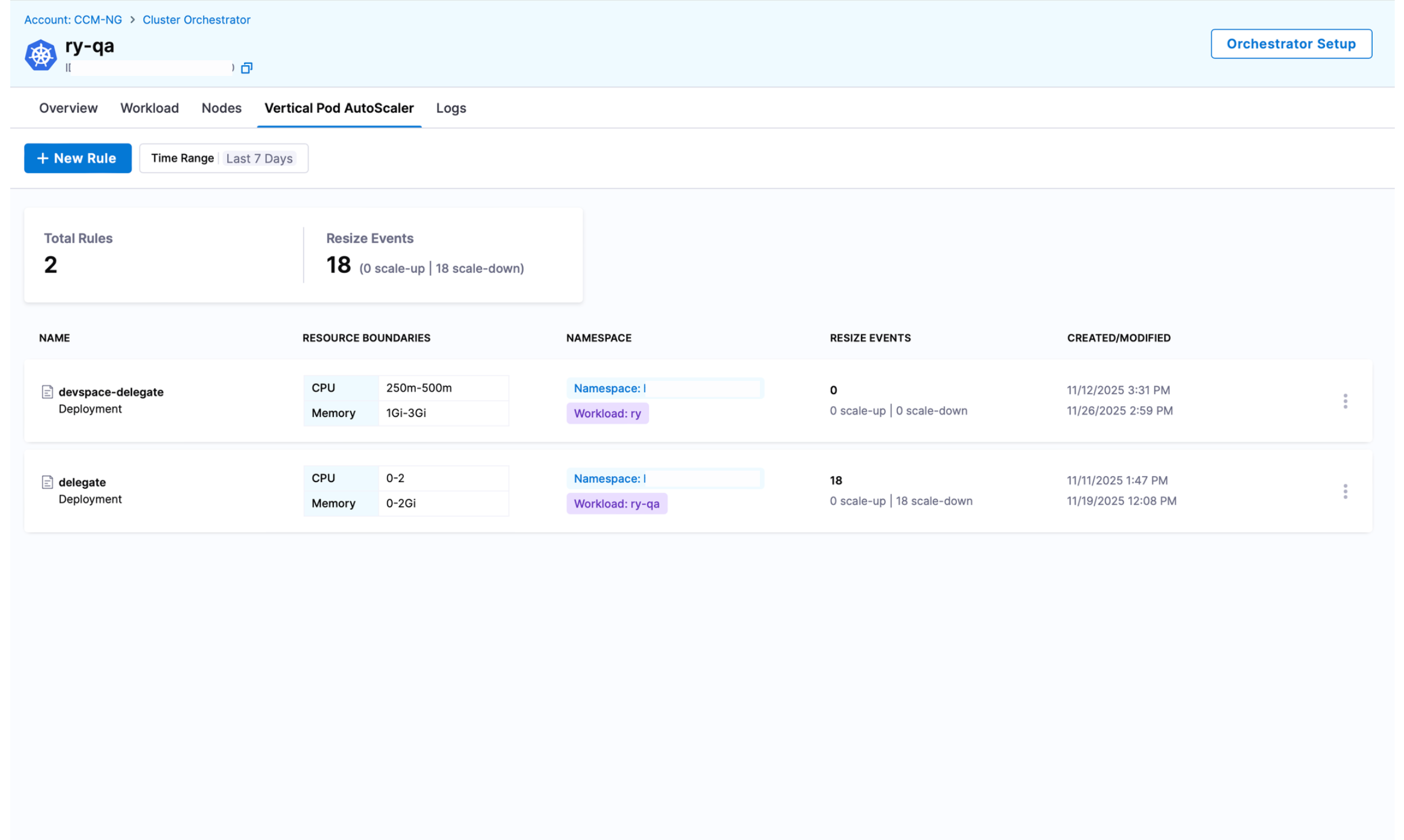
- Try Cluster Orchestrator’s Vertical Pod Autoscaler (VPA) with a single click
- Use Prometheus metrics to measure actual usage
- Analyze reports from visibility tools
Leverage Spot, AMD, or ARM-based Nodes
Make architecture and pricing work in your favor:

- Use node selectors or affinity rules to schedule less critical workloads to Spot nodes. You can use Harness’s Cluster Orchestrator to run your workloads partially in Spot instances. Spot nodes are up to 90% cheaper compared to On-Demand nodes
- Prefer AMD or Graviton nodes for stateless or batch jobs
- Separate workloads by architecture to avoid mixed pools
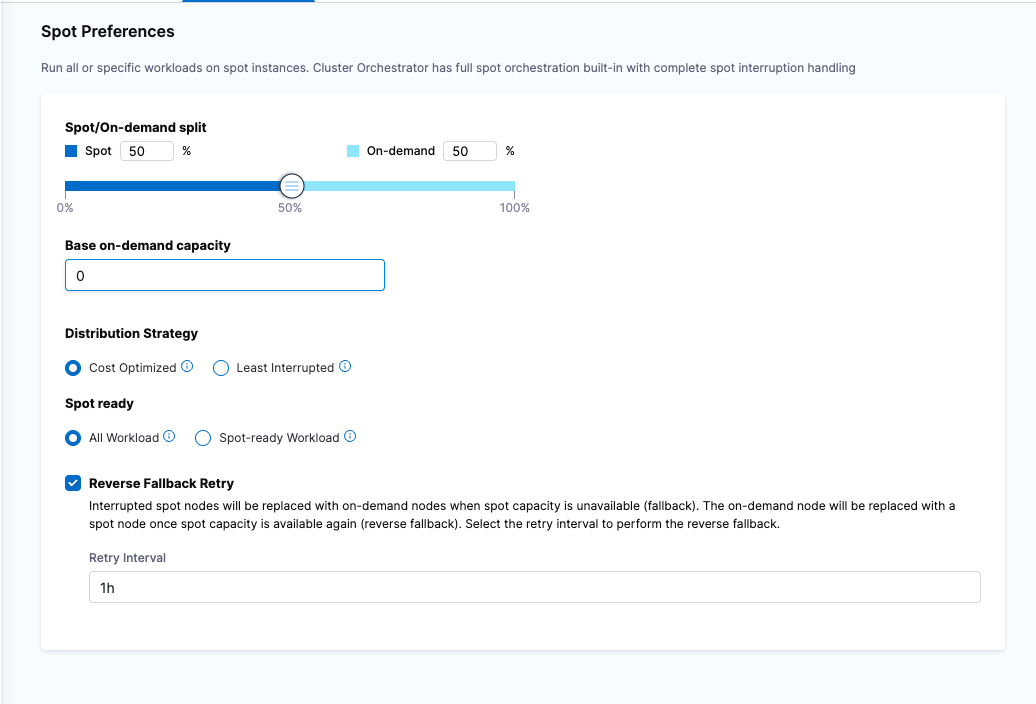
Use Fewer, More Efficient Node Pools
Instead of 10 specialized pools, consider:
- Consolidating into fewer, well-utilized pools
- Using node-level bin-packing strategies via Karpenter or Cluster Orchestrator
- Tuning autoscaler thresholds to enable more aggressive scale-down
Invisible Decisions Are Expensive
One overlooked reason why Kubernetes cost optimization is hard is that most scaling decisions are opaque. Nodes appear and disappear, but teams rarely know why a particular scale-up or scale-down happened.
Was it CPU fragmentation? A pod affinity rule? A disruption budget? A cost constraint?
Without decision-level visibility, teams are forced to guess — and that makes cost optimization feel risky instead of intentional.
Cost-aware systems work best when they don’t just act, but explain. Clear event-level insights into why a node was added, removed, or preserved help teams build trust, validate policies, and iterate safely on optimization strategies.
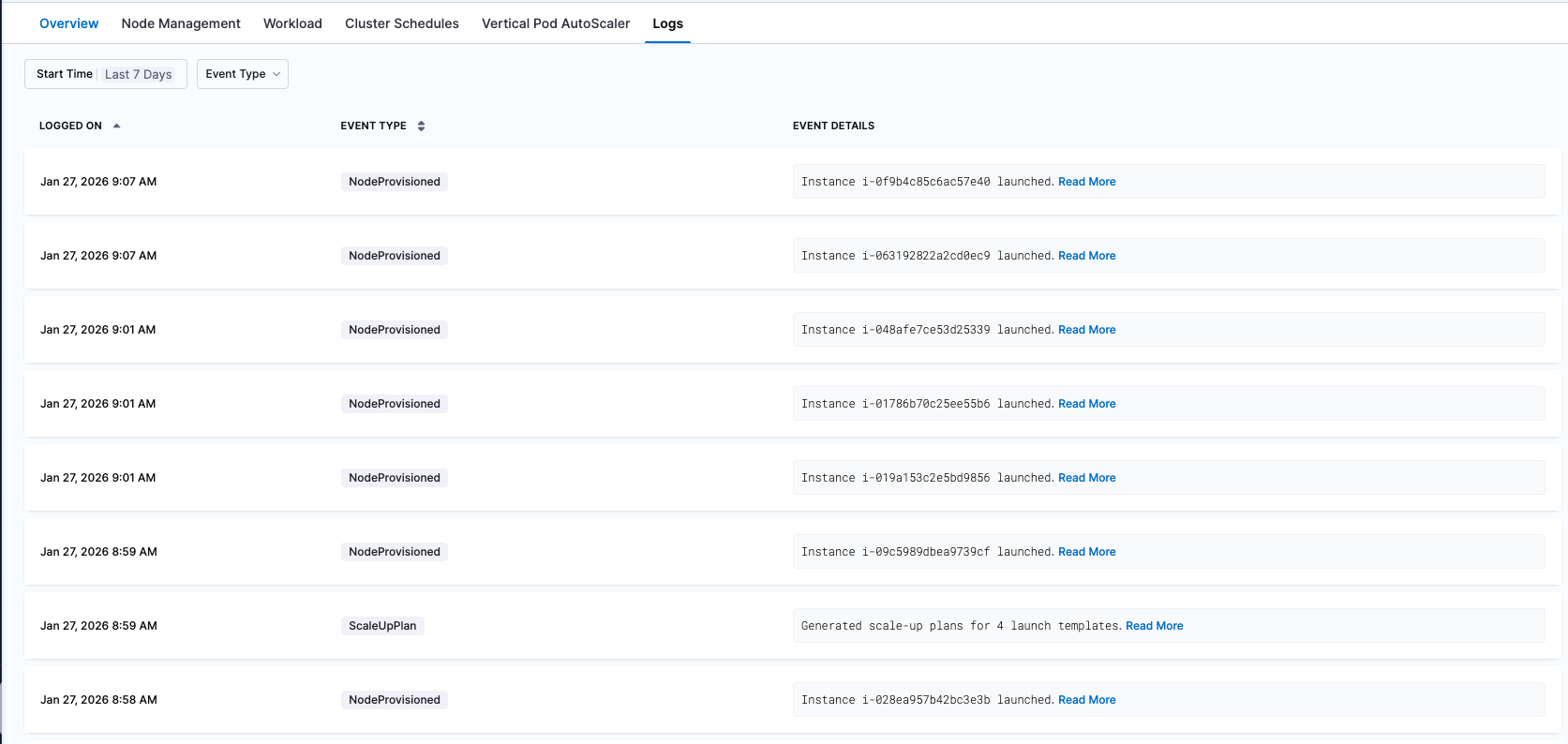
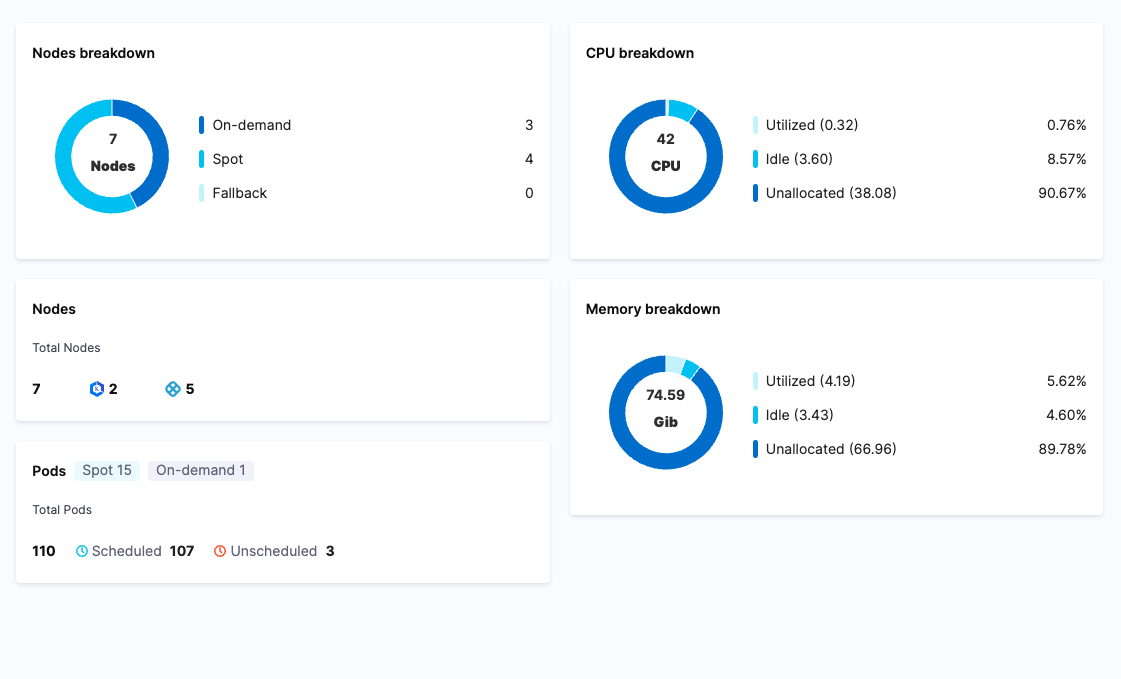
Scheduled Scale-Down of Idle Resources
One of the most effective ways to eliminate idle cost is time- or activity-based scaling. Instead of keeping clusters and workloads always on, resources can be scaled down when they are not needed and restored only when activity resumes.
With Harness CCM Kubernetes AutoStopping, teams can automatically scale down Kubernetes workloads, Auto Scaling Groups, VMs, and other resources based on usage signals or fixed schedules. This removes idle spend without requiring manual intervention.
Cluster Orchestrator extends this concept to the cluster level. It enables scheduled scale-down of entire clusters or specific node pools, making it practical to turn off unused capacity during nights, weekends, or other predictable idle windows.
Sometimes, the biggest savings come from not running infrastructure at all when it isn’t needed.

Treat Cost Like a First-Class Metric
Cost is not just a financial problem. It’s an engineering challenge — and one that we, as developers, can tackle with the same tools we use for performance, resilience, and scalability.
Start small. Review a few workloads. Test new node types. Measure bin-packing efficiency weekly.

You don’t need to sacrifice performance — just be intentional with your cluster design.
Check out Cluster Orchestrator by Harness CCM today!
Kubernetes doesn’t have to be expensive — just smarter.

All this author’s posts
Riyas P is a polyglot software engineer focused on building thoughtful, reliable, and impactful products.