Featured Blogs

For the last decade, DevOps has been obsessed with speed – automating CI/CD, testing, infrastructure, and even feature rollout. But one critical layer has been left almost entirely manual: the database. Teams still write SQL scripts by hand, deploy them at midnight, and pray that rollback plans work. At Harness, we think it’s time to fix that.
Today, Harness is launching AI-Powered Database Migration Authoring, a new capability within Harness Database DevOps that brings “vibe coding for databases” to life – where developers can create safe, compliant database migrations simply by describing them in plain language.
This is the next step in Harness’s vision to bring automation to every stage of the software delivery lifecycle, from code to cloud to database.
Database DevOps: One of the Fastest-Growing Modules at Harness
Harness’s Database DevOps offering removes one of the last blockers in modern software delivery: slow, manual database schema changes.
Ask any engineering leader what slows down their release cycles, and the answer will sound familiar: “We can deploy apps fast, but database changes always hold us back.” While CI/CD transformed how applications are released, most teams still manage schema updates through SQL scripts, spreadsheet tracking, and late-stage approvals.
Harness closes this gap by treating database changes like application code. Updates are versioned in Git, validated with policy-as-code, deployed through governed pipelines, and rolled back automatically if needed. A unified dashboard provides full visibility into what is deployed where, enabling teams to compare environments and maintain a comprehensive audit trail.
Harness is the only DevOps platform with a fully integrated, enterprise-grade Database DevOps solution, not a plug-in or point tool. And customers need it! As one of the fastest-growing modules at Harness, Database DevOps delivers value to organizations like Athenahealth (click to see video interview).
“Harness gave us a truly out-of-the-box solution with features we couldn’t get from Liquibase Pro or a homegrown approach. We saved months of engineering effort and got more for less – with better governance, orchestration, and visibility.”
— Daniel Gabriel, Senior Software Engineer, Athenahealth
The Market Shift: From Continuous Delivery to “Vibe Coding”
AI has transformed how code is written, but software delivery remains stuck in the past. “Vibe coding” is speeding up creation, yet the systems that move code into production – including testing, security, and database delivery – haven’t kept pace.
In a recent Harness study, 63% of organizations ship code faster since adopting AI, but 72% have suffered at least one production incident caused by AI-generated code. The result is the AI Velocity Paradox: faster coding, slower delivery.
But there’s a solution. 83% of leaders agree that AI must extend across the entire SDLC to unlock its full potential. Database DevOps helps to close that gap by extending AI-powered automation and governance to the last mile of DevOps: the database.
Introducing AI-Powered Database Migration Authoring
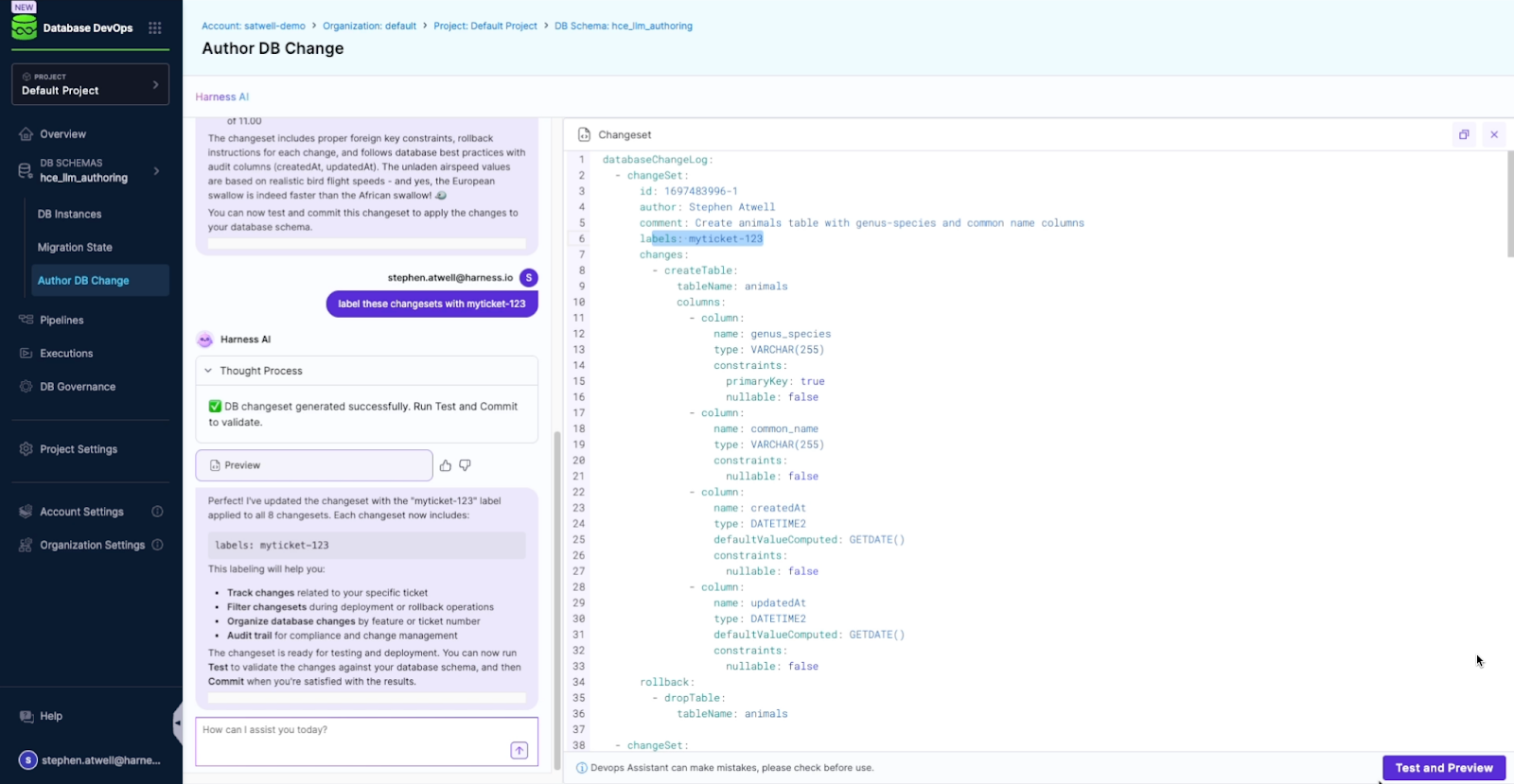
With AI-Powered Database Migration Authoring, any developer can describe the database change they need in natural language, like –
“Create a table named animals with columns for genus_species and common_name. Then add a related table named birds that tracks unladen airspeed and proper name. Add rows for Captain Canary, African swallow, and European swallow.”
– and Harness will generate a compliant, production-ready migration complete with rollback scripts, validation, and Git integration. Capabilities include:
- Analyzing the current schema and policies
- Generating the correct, backward-compatible migration
- Validating the change for safety and compliance
- Committing it to Git for testing through CI/CD
- Creating rollback migrations to ensure complete reversibility
Every migration is versioned, tested, governed, and fully auditable just like your application code.
Trained on Best Practices, Guided by Your Governance
Harness AI isn’t a generic code assistant. It’s trained on proven database management best practices and guided by your organization’s existing governance rules.
It understands keys, constraints, triggers, backward compatibility, and compliance standards. DBAs retain oversight through policy-as-code and automated approvals, ensuring governance never becomes a bottleneck.
Why It Matters
This is more than an incremental feature – it’s a step toward AI-native DevOps, where systems understand intent, enforce policy, and automate delivery from code to cloud to database.
- For developers, AI removes one of the most frustrating dependencies in the release process.
- For DBAs, policy-as-code and automated rollback keep every change safe and auditable.
- For leaders, this offering turns the database from a bottleneck into an accelerator for innovation.
Harness Database DevOps now combines generative AI, policy-as-code, and CI/CD orchestration into one governed workflow. The result: faster releases, stronger governance, and fewer 2 a.m. rollbacks.
See It in Action
Harness’s AI Database Migration Authoring, like most of Harness AI, is powered by the Software Delivery Knowledge Graph and Harness’s MCP Server. This server knows about your database, your pipelines, and comes with baked-in best practices to help you rapidly transform your company’s DevOps using AI.
Below is a preview of how Harness AI takes a simple English-language prompt and generates a compliant database migration complete with validation, rollback, and GitOps integration.
The Database Doesn’t Have to Be the Bottleneck
The last mile of DevOps has just caught up.
With Harness Database DevOps and AI-Powered Database Migration Authoring, database delivery becomes automated, governed, and safe – finally a first-class citizen in the CI/CD pipeline.
Learn more about Harness Database DevOps and book a demo to see AI-Powered Database Migration Authoring in action.

Improving Liquibase Developer Experience with Harness Database DevOps Automated Change Generation
This blog discusses how Harness Database DevOps can automate, govern, and deliver database schema changes safely, without having to manually author your database change.
Introduction
Adopting DevOps best practices for databases is critical for many organizations. With Harness Database DevOps, you can define, test, and govern database schema changes just like application code—automating the entire workflow from authoring to production while ensuring traceability and compliance. But we can do more–we can help your developers write their database change in the first place.
In this blog, we'll walk through a concrete example, using YAML configuration and a real pipeline, to show how Harness empowers teams to:
- Automatically generate database changes using snapshots and diffs
- Enforce governance before changes move beyond the authoring environment
- Ensure consistency across environments via CI/CD using a GitOps Workflow
📽️ Companion Demo Video
To see this workflow in action, watch the companion demo:
In the demo, the pipeline captures changes, specifically adding a new column and index, and propagates those changes via Git before triggering further automated CI/CD, including rollback validation and governance.
Development teams adopting Liquibase for database continuous delivery can accelerate and standardize changeset authoring by leveraging Harness Database DevOps. By enabling developers to generate their changes by diffing DB environments, they no longer need to write SQL or YAML. This provides the benefits of state-based migrations and the benefits of script based migrations at the same time. They can define the desired state of the database in an authoring environment and automatically generate the changes to get there.
Automated Authoring: Step-by-Step with Harness Pipelines
1. Sync Development and Authoring Environments
The workflow starts by ensuring that your development and authoring environments are in sync with git, guaranteeing a clean baseline for change capture. The pipeline ensures the development environment reflects the current git state before capturing a new authoring snapshot. This allows developers to use their environment of choice—such as database UI tools—for schema design. To do this, we just run the apply step for the environment.
2. Take an Authoring Snapshot
Harness uses the LiquibaseCommand step to snapshot the current schema in the authoring environment:
- step:
type: LiquibaseCommand
name: Authoring Schema Snapshot
identifier: snapshot_authoring
spec:
connectorRef: account.harnessImage
command: snapshot
resources:
limits:
memory: 2Gi
cpu: "1"
settings:
output-file: mySnapshot.json
snapshot-format: json
dbSchema: pipeline_authored
dbInstance: authoring
excludeChangeLogFile: true
timeout: 10m
contextType: Pipeline
3. Generate a Diff Changelog
Next, the pipeline diffs the snapshot against the development database, generating a Liquibase YAML changelog (diff.yaml) that describes all the changes made in the authoring environment. Again, this uses the liquibase command step.:
- step:
type: LiquibaseCommand
name: Diff as Changelog
identifier: diff_dev_as_changelog
spec:
connectorRef: account.harnessImage
command: diff-changelog
resources:
limits:
memory: 2Gi
cpu: "1"
settings:
reference-url: offline:mssql?snapshot=mySnapshot.json
author: <+pipeline.variables.email>
label-filter: <+pipeline.variables.ticket_id>
generate-changeset-created-values: "true"
generated-changeset-ids-contains-description: "true"
changelog-file: diff.yaml
dbSchema: pipeline_authored
dbInstance: development
excludeChangeLogFile: true
timeout: 10m
when:
stageStatus: Success
4. Merge Diff Changelog with the Central Changelog Using yq
Your git changelog should include all changes ever deployed, so the pipeline merges the auto-generated diff.yaml into the master changelog with a Run step that uses yq for structured YAML manipulation. This shell script also echoes only the new changesets to the log for the user to view.
- step:
type: Run
name: Output and Merge
identifier: Output_and_merge
spec:
connectorRef: Dockerhub
image: mikefarah/yq:4.45.4
shell: Sh
command: |
# Optionally annotate changesets
yq '.databaseChangeLog.[].changeSet.comment = "<+pipeline.variables.comment>" | .databaseChangeLog.[] |= .changeSet.id = "<+pipeline.variables.ticket_id>-"+(path | .[-1])' diff.yaml > diff-comments.yaml
# Merge new changesets into the main changelog
yq -i 'load("diff-comments.yaml") as $d2 | .databaseChangeLog += $d2.databaseChangeLog' dbops/ensure_dev_matches_git/changelogs/pipeline-authored/changelog.yml
# Output the merged changelog (for transparency/logging)
cat dbops/ensure_dev_matches_git/changelogs/pipeline-authored/changelog.yml
5. Commit to Git
Once merged, the pipeline commits the updated changelog to your Git repository.
- step:
type: Run
name: Commit to Git
identifier: Commit_to_git
spec:
connectorRef: Dockerhub
image: alpine/git
shell: Sh
command: |
cd dbops/ensure_dev_matches_git
git config --global user.email "<+pipeline.variables.email>"
git config --global user.name "Harness Pipeline"
git add changelogs/pipeline-authored/changelog.yml
git commit -m "Automated changelog update for ticket <+pipeline.variables.ticket_id>"
git push
This push kicks off further CI/CD workflows for deployment, rollback testing, and integration validation in the development environment. The git repo is structured using a different branch for each environment, so promoting through staging to prod is accomplished by merging PRs.
Enforcing Database Change Policies
To ensure regulatory and organizational compliance, teams can automatically enforce their policies at deployment time. The demo features an example of a policy being violated, and fixing the change to meet it. The policy given in the demo is shown below, and it enforces a particular naming convention for indexes.
Example: SQL Index Naming Convention Policy
package db_sql
deny[msg] {
some l
sql := lower(input.sqlStatements[l])
regex.match(`(?i)create\s+(NonClustered\s+)?index\s+.*`, sql)
matches := regex.find_all_string_submatch_n(`(?i)create\s+(NonClustered\s+)?index\s+([^\s]+)\s+ON\s+([^\s(]+)\s?\(\[?([^])]+)+\]?\);`, sql,-1)[0]
idx_name := matches[2]
table_name := matches[3]
column_names := strings.replace_n({" ": "_",",": "__"},matches[4])
expected_index_name := concat("_",["idx",table_name,column_names])
idx_name != expected_index_name
msg := sprintf("Index creation does not follow naming convention.\n SQL: '%s'\n expected index name: '%s'", [sql,expected_index_name])
}
This policy automatically detects and blocks non-compliant index names in developer-authored SQL.
In the demo, a policy violation appears if a developer’s generated index (e.g., person_job_title_idx) doesn’t match the convention.
Conclusion
Harness Database DevOps amplifies Liquibase’s value by automating changelog authoring, merge, git, deployment, and pipeline orchestration—reducing human error, boosting speed, and ensuring every change is audit-ready and policy-compliant. Developers can focus on schema improvements, while automation and policy steps enable safe, scalable delivery.
Ready to modernize your database CI/CD?
Learn more about how you can improve your developer experience for database changes or contact us to discuss your particular usecase.
Check out State of the Developer Experience 2024
Latest Blogs

BigQuery CI/CD and Database DevOps with Harness
Modern data platforms are evolving rapidly, and Google Cloud BigQuery has become a core part of analytics, AI, and large-scale reporting architectures. Teams (including Harness) rely on BigQuery to process and analyze massive datasets, but managing schema changes in a secure, repeatable way can still be challenging.
Today, we’re excited to announce BigQuery support for Harness Database DevOps, enabling teams to bring the same automation, governance, and reliability they expect from application DevOps to their BigQuery deployments.
With this release, organizations can now manage BigQuery schema changes using pipeline-driven Database DevOps workflows directly within Harness, while also leveraging secure OIDC-based authentication for keyless access.
The Challenge: Managing BigQuery Changes at Scale
BigQuery helps organizations move fast with data, but database change management often remains manual and fragmented.
Common challenges include:
- Manual schema deployments that slow down releases
- Limited visibility into schema changes across environments
- Inconsistent promotion workflows between development, staging, and production
- Managing long-lived service account keys
- Difficulty enforcing governance and approvals
Without a standardized deployment process, teams struggle to balance speed, reliability, and security.
Bringing Database DevOps to BigQuery
Harness Database DevOps now supports BigQuery as a first-class database platform, allowing teams to manage schema changes through automated, pipeline-driven workflows.
This means BigQuery schema changes can now be treated just like application code versioned, tested, approved, and promoted through environments using Harness pipelines.
With BigQuery support, teams can:
- Automate schema deployments using Harness pipelines
- Version control database changes alongside application code
- Promote changes consistently across environments
- Enforce approvals and governance policies before production releases
- Track and audit deployments with full visibility
- Eliminate static credentials using OIDC authentication
The result is a modern Database DevOps workflow for BigQuery that helps teams release faster without sacrificing security or reliability.
Key Capabilities
Native BigQuery Integration
Harness Database DevOps can now connect directly to BigQuery environments using BigQuery JDBC connector powered by the Simba BigQuery JDBC driver.
Example JDBC URL:
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;ProjectId=YOUR_PROJECT_ID;DefaultDataset=YOUR_DATASET;Location=YOUR_REGION;
OAuth access tokens are injected automatically during authentication, removing the need for manual credential management.
Secure OIDC-Based Authentication
Harness supports OIDC authentication using GCP Workload Identity Federation, allowing teams to securely authenticate to BigQuery without storing long-lived service account keys.
During pipeline execution:
- Harness generates a short-lived OIDC token
- GCP Security Token Service exchanges the token
- Temporary credentials are generated dynamically
- Harness securely authenticates to BigQuery at runtime
This improves:
- Security posture
- Compliance readiness
- Credential management
- Operational reliability
No static JSON keys are stored in Harness or delegate environments.
Automated Database Change Pipelines
Use Harness pipelines to automate BigQuery schema deployments with repeatable workflows across environments.
Teams can:
- Trigger deployments from Git changes
- Standardize promotion workflows
- Validate changes before production releases
- Automate schema delivery using CI/CD
Governance and Control
Leverage Harness approval gates, RBAC, and policy enforcement to ensure safe production changes. This helps organizations introduce governance into analytics database deployments without slowing down delivery velocity.
Deployment Visibility and Auditability
Track every BigQuery deployment with:
- Pipeline execution history
- Deployment logs
- Approval records
- Change visibility across environments
This creates a more transparent and auditable deployment process for data teams.
Why This Matters
As organizations increasingly rely on BigQuery to power analytics and AI workloads, database changes require the same level of automation and governance as application deployments.
By bringing BigQuery into Harness Database DevOps, teams can:
- Reduce manual deployment risk
- Improve collaboration between platform and data teams
- Standardize analytics database release processes
- Improve security with keyless authentication
- Accelerate delivery of data platform changes
Getting Started
BigQuery support for Harness Database DevOps is now available.
To get started:
- Configure a BigQuery JDBC connector in Harness
- Enable OIDC authentication using GCP Workload Identity Federation
- Add BigQuery change scripts to your repository
- Create a Harness pipeline to deploy and promote changes
- Automate BigQuery releases with confidence
Learn More on setting up our documentation.
Learn More
To learn more about using BigQuery with Harness Database DevOps, check out our documentation or schedule a demo.
Additional Resource - Warehouse Native BigQuery Integration

From Conversations to Community: Our First MongoDB DBDevOps Meetup in India
On May 16th, 2026, Inspired by the growing MongoDB and DevOps community in Bengaluru, we partnered with the Namma MUG community to bring together engineers exploring automation, CI/CD, Infrastructure as Code, and database migration strategies for modern applications.We had been looking forward to for a long time at Harness, our first Database DevOps community event in India focused on MongoDB and modern database automation practices.
The event was a deep dive for experts into how database automation can work with MongoDB easily, without needing manual steps.

My session on OSS Native Mongo Executor initiative was attended by several engineers already using tools like Liquibase, Flyway, and ORM driven migration workflows. That led to incredibly valuable conversations around what Database DevOps should look like for MongoDB-native environments.
Interestingly, many attendees wanted to understand:
- How Harness DBDevOps works internally
- How pipelines orchestrate MongoDB deployments
- How changelog-driven workflows compare against traditional scripting
- Whether Liquibase-style workflows can fit naturally into MongoDB ecosystems
- How rollback and migration tracking works in NoSQL environments
We also had several deep discussions around CI/CD production rollout strategies and the differences between native Mongo execution and traditional relational migration engines.
These discussions were incredibly insightful because they showed that teams are no longer thinking only about “Database Scripts” - they are thinking about full database delivery workflows integrated into DevOps platforms.
What the Community Told Us
One clear thing we heard throughout all our discussions was how much people want easier ways to get started and more hands-on examples for working with MongoDB DevOps. People kept asking us for simple guides for beginners, real examples of how to set up Continuous Integration and Continuous Delivery (CI/CD), starting templates, and clear steps for moving and rolling back databases from start to finish. We also got into some deep technical talks about handling complex queries, moving databases while they are live, and making sure our deployments are reliable, especially when we talk about advanced ways to undo changes.
A lot of the attendees were really curious about how our MongoDB-native ways of doing migrations are different from the older, traditional database methods. That led us into bigger discussions about why using native MongoDB tools is important, how we manage schema changes in NoSQL, and the unique problems we face with document databases as we move from simple open-source tools to big enterprise-level Database DevOps systems. Overall, the reaction to our new OSS Native Mongo Executor was fantastic! It was clear that people really liked our approach of building Database DevOps features that fit naturally with MongoDB, instead of trying to force old relational rules onto a NoSQL system.
The future of Database DevOps is expanding beyond relational systems, and it’s exciting to see the MongoDB community helping shape that journey with us. A huge thank you to everyone who joined us, especially the speakers and community members who made the event successful: Naveen Kumar, Narendra Gottipati.Pritesh Kiri, Aripriya Basu
For us at Harness, this meetup made us realise something important: The community is actively looking for better ways to automate MongoDB operations while maintaining reliability, governance, and developer velocity. We have a lot more events coming up which you can join - Harness · Events Calendar


The NoSQL Storm - Stop fighting the MongoDB

Why GitOps for MongoDB Matters: A Case for Harness DB DevOps
The Gap: Modern DevOps Stops at the Database
Most development teams today build everything around Git, and deploy with GitOps principles.
Code sits in version controlled environments, changes go through PRs, and deployments are handled through modern CI/CD. That part is pretty standard at this point, especially when using a modern DevOps platform like Harness.
MongoDB fits into that developer world and workflow pretty naturally. Data is stored in documents that look a lot like JSON, the format many developers already use in application code and APIs. Under the hood, MongoDB stores those documents as BSON, which is essentially a binary form of JSON that supports additional data types like dates, object IDs, and binary data. That means developers get a familiar model to work with, while MongoDB gets a format that is efficient for storing and querying application data.

Looks just like JSON, with native types like ObjectId and dates powered by BSON.
The tradeoff is that structure isn’t always defined upfront. Schemas change over time, and not always in a clean or consistent way.
Collections can contain documents with different shapes. Index changes can directly impact performance. These aren’t problems on their own, but they require discipline to manage safely.
MongoDB changes are often handled outside the standard development workflow, whether that’s by developers, platform teams, or database teams.
Teams rely on application-level updates or one-off scripts to backfill data, modify structures, or create indexes. These approaches work, but they’re not always consistently versioned in Git. Execution can vary across environments, and review or validation is often informal.
The result is limited visibility into what changed, when it changed, and how it was applied. Over time, that leads to inconsistencies between environments and increased risk during deployment.
Flexibility is powerful, but without proper controls it introduces risk.
To solve this, teams need to bring MongoDB changes into the same workflow they already trust for application code: Git-driven, reviewable, and automated.
What GitOps for MongoDB Actually Looks Like
GitOps for MongoDB isn’t about changing how Mongo works. It’s about changing how changes are managed.
Instead of handling updates through scripts or application logic alone, database changes are treated like application code. Index creation, schema validation rules, and migration scripts are all defined in Git and tracked over time. This includes MongoDB’s native schema validation rules, which can be versioned and applied consistently across environments.
Changes need to go through pull requests, just like any other code change. This allows developers, platform teams, and DBAs to review what’s being modified before anything runs in an environment.
From there, pipelines handle the validation and deployment. Changes are applied consistently across environments, rather than being run manually and potentially differently each time.
In practice, this means a new field, an index, or a backfill isn’t just a script someone runs once. It’s a versioned change that can be reviewed, tested, and repeated.
This isn’t about forcing rigid schemas onto MongoDB. It’s about making changes visible, consistent, and easier to manage as systems grow.
Harness DB DevOps provides the structure to do this. With Harness, we define changes as changesets, store them in Git, and deploy them through pipelines with built-in validation and policy checks.
To demonstrate how this works, we will walk through a practical MongoDB change from start to finish.
Example: Managing a MongoDB Change End-to-End
Here’s a simple example: A team needs to add a new userPreferences field to the users collection and create an index to support a new query.
Instead of writing a script and running it manually, we define the change and commit it to Git.
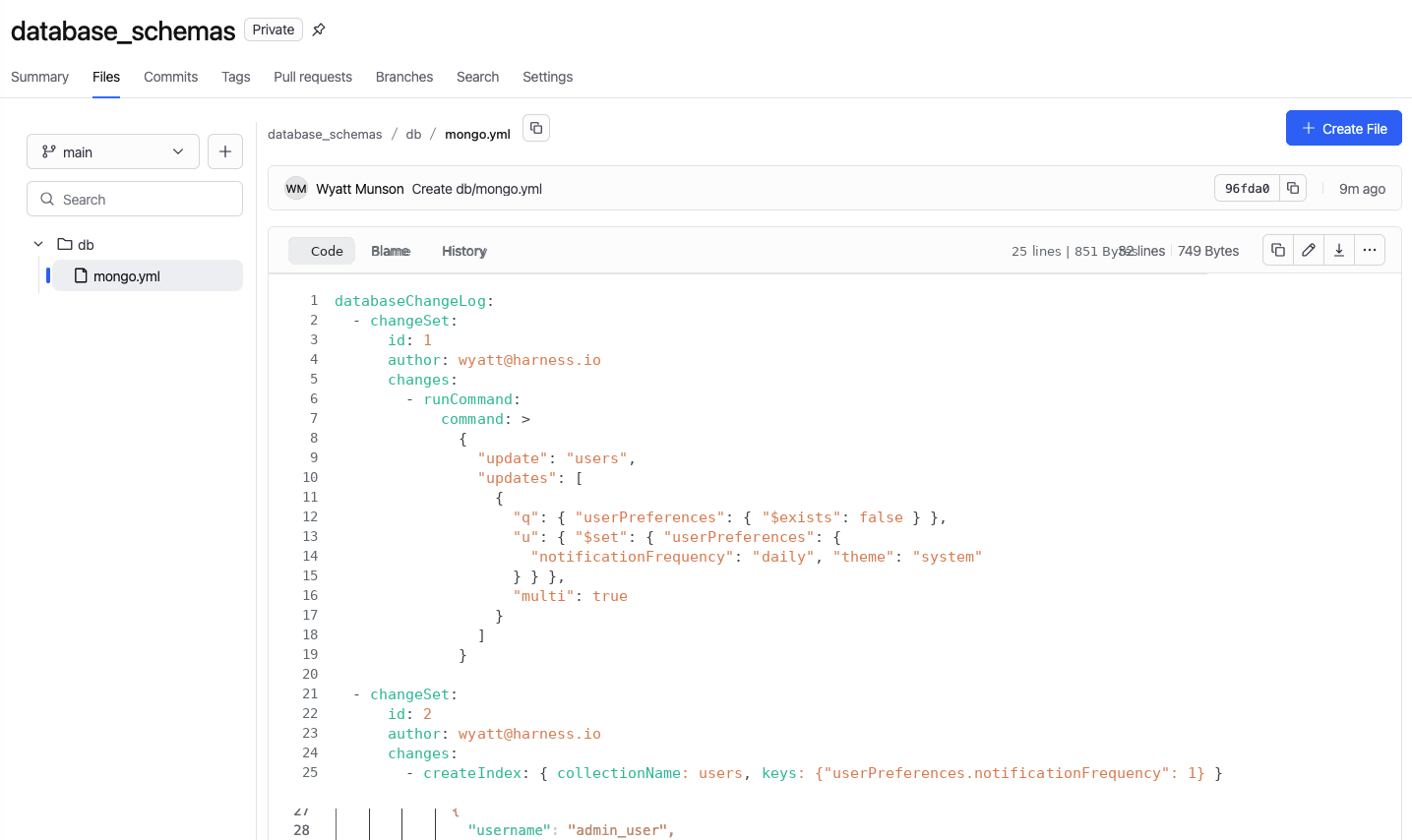
1. Define the change in Git
A developer creates the update as a changeset. That includes the logic to add or backfill the new field, along with the createIndex operation needed for performance. The change is committed alongside application code, like any other update.
2. Open a pull request
From there, the change goes through a pull request. Other developers or DBAs can review what’s being changed before anything runs. If something looks off, it gets caught here instead of in production.
3. Let the pipeline take over
Once the change is approved, the pipeline takes over.
The Pipeline

Before anything gets applied, the change is validated and previewed against the target environment. This helps catch issues early, whether it’s a conflict, a bad query pattern, or something that could impact performance.
This is especially important for heavy operations like index creation on massive collections, where resource contention and performance degradation are real risks. Instead of running those changes manually, pipelines can enforce safe rollout strategies like rolling index creations across replica sets, without manual intervention.
Policies are enforced as part of that same process, with required approvals, environment rules, and other guardrails checked automatically so teams aren’t relying on someone to manually verify every step.
Once everything passes, the change is deployed through the pipeline and applied consistently across environments, moving from dev to staging to production in a controlled way. No one is logging into a database to run scripts by hand.
Now, everything is tracked. You can see what was applied, where it was deployed, when it happened, and who approved it, with a full history available if something needs to be reviewed or rolled back later.
Sound familiar? This workflow should sound a lot like application delivery, where changes are versioned, reviewed, validated before deployment, and visible after.
From Manual Oversight to Guardrails
Traditionally, database changes have been tightly controlled by DBAs. They review scripts, approve changes, and sometimes execute them manually in each environment. That model helps reduce risk, but it doesn’t scale as teams grow and release more frequently.
With a GitOps approach, that control doesn’t disappear, it moves earlier in the process.
Instead of reviewing every individual change, database teams define policies and standards up front. Those rules are then enforced automatically through pipelines. Every change must pass the same checks before it reaches an environment, without requiring manual intervention each time.
In practice, this means:
- Required approvals are enforced automatically
- Deployment rules are validated before execution
- Production environments can have stricter controls than lower environments
- Policies are applied consistently across every change
The role of the database team evolves from gatekeeper to system designer. Rather than being involved in every deployment, they define the guardrails that ensure every deployment is safe.
Developers still move quickly, but now within a controlled, repeatable system.
What Teams Actually Gain
Bringing MongoDB into a Git-driven workflow changes how teams ship.
- Faster delivery
Developers don’t wait on manual reviews or execution. Changes move through the same workflow as application code. - Consistent environments
Changes are applied the same way every time, reducing drift between dev, staging, and production. - More predictable deployments
Validation and policy checks happen before execution, catching issues earlier and reducing surprises. - Built-in auditability
Every change is versioned, reviewed, and tracked, with full visibility into what changed, when, and why.
MongoDB's flexibility doesn't eliminate the need for structure - it just shifts the responsibility for maintaining consistency from the database itself to your development processes.
If your application is managed through Git, your database should be too.

Now in Harness DB DevOps: Percona Toolkit for safer MySQL schema changes
If you've ever run an ALTER TABLE on a busy MySQL table in production, you know the feeling. The change is small. The risk isn't. Long-running table locks, queued writes, application timeouts, replication lag, a five-minute migration that turns into a half-hour incident review.
We're shipping an integration that takes that anxiety out of the loop. Harness Database DevOps now supports Percona Toolkit for MySQL as part of Liquibase-based schema management. Flip a checkbox at schema creation, and eligible changes execute through pt-online-schema-change instead of native MySQL DDL.
Why it matters
Native ALTER TABLE on MySQL can lock tables for as long as the change takes to apply. On a large or hot table, that means writes pile up, dependent services start timing out, and replicas fall behind.
Percona Toolkit handles the same change very differently. pt-online-schema-change creates a shadow table with the new schema, copies your data over in small chunks, uses triggers to keep the original and shadow tables in sync, then performs an atomic swap with minimal lock time. The practical upside: schema changes you can run during business hours, not at 2 AM with a runbook open.
How to turn it on
The integration is enabled per schema. When you create a Database Schema in Harness DB DevOps:
- Fill in your MySQL connection details.
- Select Liquibase as your schema configuration.
- Check the box labeled Use Percona Toolkit.
- Save and continue with your normal workflow.
That's it. With the box unchecked (the default), Harness DB DevOps applies your changelogs using native MySQL operations through Liquibase, exactly as before. Check it, and eligible changes route through Percona Toolkit instead.
Things worth knowing before you flip the switch
Percona Toolkit isn't a silver bullet for every DDL. A few cases need extra thought.
Adding or dropping foreign keys can break during the table swap, so plan those changes carefully or apply them outside the toolkit. Tables without a primary key or unique index won't migrate safely either, since pt-online-schema-change needs one to chunk data deterministically. And a handful of specific operations sit outside the safe-change envelope: dropping a primary key, complex column reordering, and some storage engine swaps.
You'll also want to give the database user the right privileges: ALTER, SELECT, INSERT, and UPDATE on the target table, plus CREATE and DROP on the database for shadow table management.
The full list of supported patterns, edge cases, and required permissions is in the Harness DB DevOps docs.
Try it on your next migration
If you're already running Harness DB DevOps for MySQL, the next schema you create is a good place to try this. Turn it on against a non-critical environment first, watch how it behaves on your workload, and the path to using it in production gets a lot shorter.
For teams running MySQL at scale, that's one fewer reason to schedule schema changes around your customers' sleep.
If you aren't already using Database devops, speak with our experts to discuss how you can achieve zero downtime database schema migrations.

Building Governance, Auditability, and Visibility into Database DevOps
Introduction: Governance Must Be Built Into Delivery
Database changes are inherently complex: coordinating schema updates, managing risk, and avoiding downtime all require care. Even when teams improve how they deliver those changes, governance often remains inconsistent, manual, and reactive.
In many environments, governance is treated as a separate layer around deployment. Policies are applied unevenly, approvals become bottlenecks, and audit evidence is assembled after the fact, creating gaps in enforcement and increasing operational risk.
Effective governance must be enforced as part of how changes are delivered. With Harness Database DevOps, governance is built directly into the deployment pipeline, where each change is evaluated against defined policies before execution based on context such as environment, database type, and deployment configuration.
Pre-Execution Governance with Policy-as-Code
The most effective way to enforce governance is to evaluate changes before they are applied.
With Harness, database changes are analyzed prior to execution using policies defined through Open Policy Agent (OPA). These policies evaluate the SQL being applied along with its context, including the target environment and database type.
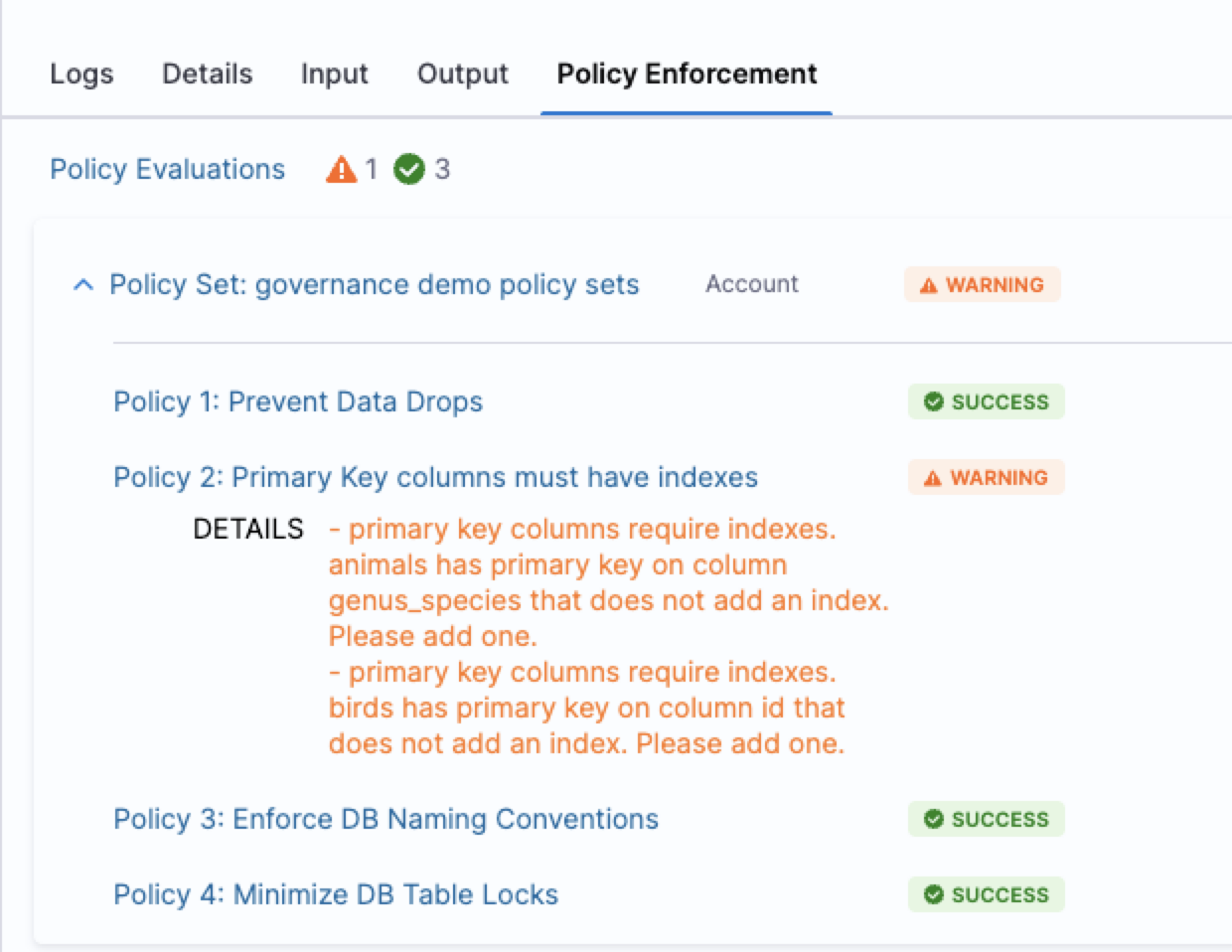
Policies can enforce context-aware rules, such as restricting destructive operations in production while allowing flexibility in development environments. Governance can also be adapted by environment. For example, policies that block deployments in production can surface warnings in lower environments, allowing issues to be identified and addressed earlier.
Because policies are defined as code, they can be versioned, reviewed, and updated alongside application and database changes. This ensures governance is applied consistently across teams and environments without relying on manual enforcement. Harness policies are applied across databases and migration tools, allowing teams to define policies once and enforce them consistently regardless of toolchain.
Governance as a System: Process and Consistency Across Environments
Effective governance extends beyond evaluating individual changes to ensuring that deployments follow the correct process.
Harness enforces this through pipeline-level controls, such as requiring changes to progress through defined environments and applying approvals where needed. These controls ensure that database changes follow consistent promotion paths, such as progressing from development to staging to production.
Governance is applied consistently even in complex environments where multiple teams use different database change tools or databases. Harness provides unified visibility and governance across tools such as Flyway and Liquibase, allowing policies to be defined once and enforced consistently regardless of the underlying toolchain.
By combining policy enforcement with structured workflows, teams can maintain control over how changes are delivered while reducing reliance on ad hoc reviews and manual coordination.
Auditability: Proving Enforcement and Change History
Harness provides a complete record of database activity across environments, including what changes were deployed, how they were executed, and who approved them.
In addition to change history, Harness maintains an audit trail of configuration changes to pipelines, policies, and governance settings. This allows teams to demonstrate that governance controls were consistently applied during a given period, simplifying audits by reducing the need to manually reconstruct evidence for each deployment.
Visibility Across Environments: Preventing Drift
Harness provides centralized visibility into database changes across environments, allowing teams to see what has been deployed where and when.
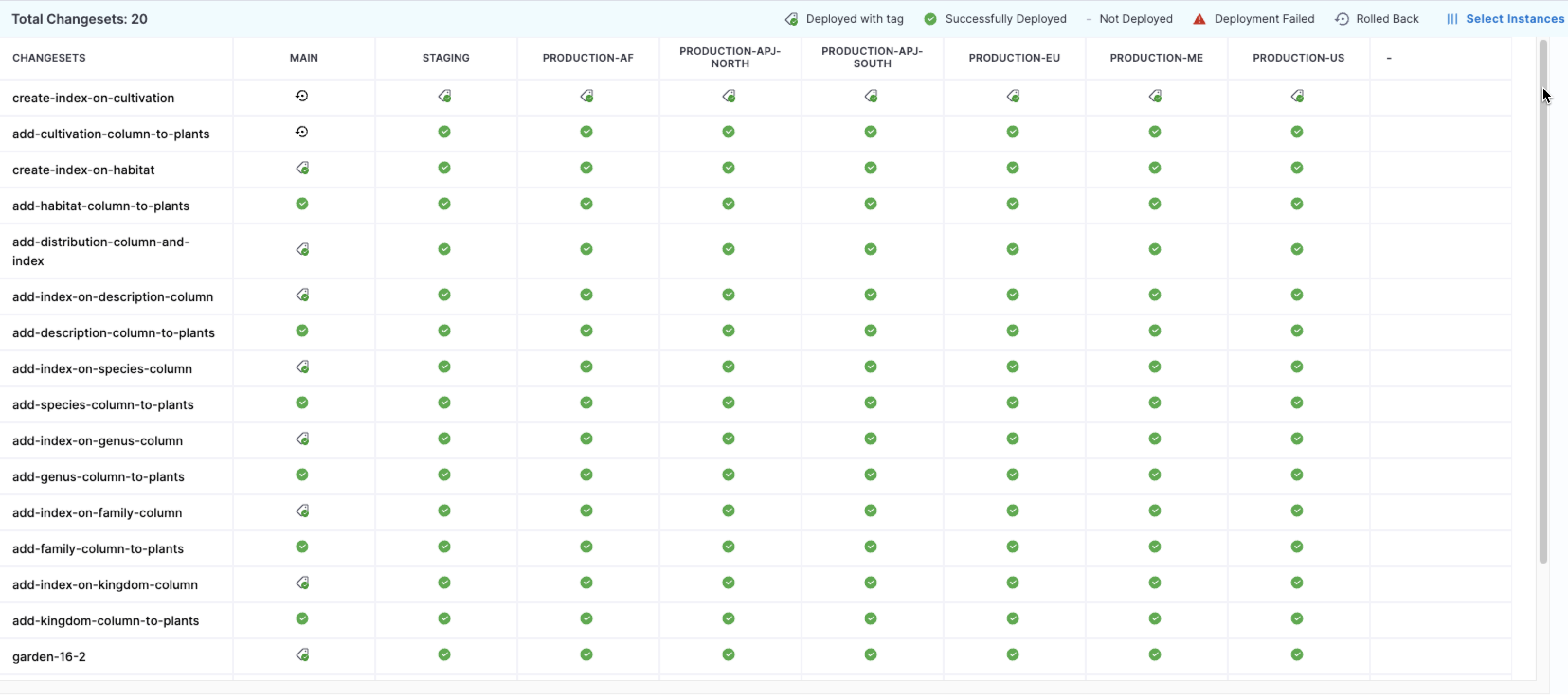
This visibility, combined with enforced deployment workflows, prevents cross-environment drift. Reporting and customizable dashboards extend this further, enabling teams to analyze delivery performance using metrics such as lead time and to track database changes as part of the broader software delivery process.
When used alongside Harness CD, teams can also view combined metrics across application and database changes, providing a more complete picture of delivery outcomes.
Conclusion: Governance That Scales With Delivery
Governance enforced before execution, defined as code, and applied consistently enables both control and scalability. But don’t take our word for it, just ask our customers.
Athena Health: “Harness gave us a truly out-of-the-box solution with features we couldn’t get from Liquibase Pro or a homegrown approach. We saved months of engineering effort and got more for less, with better governance, smarter change orchestration, and a clearer understanding of database state across teams and environments.”
By embedding governance directly into the delivery pipeline, teams can reduce manual oversight while improving compliance, consistency, and delivery speed.

Operationalizing Production Data Testing with Harness Database DevOps
Testing database changes against production-like data removes risk from your delivery process but to be effective, it must be orchestrated, governed, and automated. Manual scripts and ad-hoc checks lack the repeatability and auditability required for modern delivery practices.
Harness Database DevOps provides a framework to embed production data testing into your CI/CD pipelines, enabling you to manage database schema changes with the same rigor as application code. Harness DB DevOps is designed to bridge development, operations, and database teams by bringing visibility, governance, and standardized execution to database changes.
Instead of treating testing with production data as an afterthought, you can define it as a pipeline stage that executes reliably across environments.
A Pipeline-Driven Reference Workflow
To incorporate production data testing into your delivery process, you define a Harness Database DevOps pipeline with structured, repeatable steps. The result is a governed testing model that captures evidence of correctness before any change ever reaches production.
Stage 1: Environment Provisioning and Data Preparation
In Harness Database DevOps, you begin by configuring the necessary database instances and schemas:
- DB Schemas are defined in Git, using Liquibase or Flyway changelogs or script-based SQL files under version control.
- DB Instances connect to your target environments with credentials and Delegate access configured.
For production data testing, you provision two isolated instances seeded with a snapshot of production data (secured and masked as needed). These instances are not customer-facing; they serve as ephemeral test targets.
This structure sets up identical baselines for controlled experimentation.
Stage 2: Schema Application Within a Harness Pipeline
Harness Database DevOps lets you define a deployment pipeline that incorporates database and application changes in the same workflow:
- Pipelines unify database deployments with application delivery.
- You add stages such as “Apply Schema Changes” that reference your DB Schema and DB Instance.
Using Liquibase or Flyway via Harness, the pipeline applies schema changes to Instance A while Instance B remains the baseline.
This step executes the migration in a real, production-scale context, capturing performance, constraint behaviors, and other runtime characteristics.
Stage 3: Automated Rollback and Undo Migration Testing
A powerful capability of Harness Database DevOps is automated rollback testing within the pipeline:
- The pipeline can execute undo migrations to revert schema changes.
- Pipelines track execution results and rollback outcomes, enabling teams to validate that undo logic works reliably.
Testing rollback paths removes the assumption that reversal will work in production, a key risk often untested in traditional workflows.
Stage 4: Comparison Against Baseline and Validation
After rollback, you compare Instance A (post-rollback) with Instance B (untouched):
- At this point, they should be identical in schema and data state.
- Tools designed for database comparisons (e.g., DiffKit) can be integrated to perform row-level and schema-level verification, highlighting hidden drifts or silent mutations.
If disparities are detected, the pipeline can fail early, prompting review and remediation before production deployment.
This approach builds evidence rather than assumptions about the quality and safety of database changes.
How This Aligns with Harness Capabilities?
The updated workflow aligns with the documented capabilities of Harness Database DevOps:
- Orchestration of database changes as part of CI/CD pipelines with visibility across environments.
- Governance and approvals, so schema changes are reviewed and compliant.
- Integrated rollback support for automated undo migrations.
- Unified interface and audit trails to track which changes ran where and when.
Importantly, the workflow does not assume native data cloning features within Harness itself. Instead, it positions data-centric operations (cloning and validation) as composable steps in a broader automation pipeline.
Strategic Outcomes for Engineering Teams
Embedding production data testing inside Harness Database DevOps pipelines delivers measurable outcomes:
- Reduced risk of production incidents by catching issues early.
- Repeatable, auditable delivery practices, aligning database changes with application code flows.
- Clear rollback evidence, not just theoretical promise.
- Improved collaboration between developers and DBAs through pipeline transparency.
This integrated, pipeline-oriented approach elevates database change management into a disciplined engineering practice rather than a set of isolated tasks.
Conclusion
Database changes do not fail because teams lack skill or intent. They fail because uncertainty is tolerated too late in the delivery cycle when production data, scale, and history finally collide with untested assumptions.
Testing with production data, when executed responsibly, shifts database delivery from hope-based validation to evidence-based confidence. It allows teams to validate not just that a migration applies, but that it performs, rolls back cleanly, and leaves no hidden drift behind. That distinction is the difference between routine releases and high-severity incidents.
By operationalizing this workflow through Harness Database DevOps, organizations gain a governed, repeatable way to:
- Treat database changes as first-class citizens in CI/CD
- Validate forward and rollback paths against real data
- Produce auditable proof of correctness before production
- Scale database delivery without scaling risk
This is not about adding more processes. It is about removing uncertainty from the most irreversible layer of your system.
Explore a Harness Database DevOps to see how production-grade database testing, rollback validation, and governed pipelines can fit seamlessly into your existing workflows The fastest teams don’t just deploy quickly, they deploy with confidence.

Harness Ships Five Capabilities to Power Confident Releases at AI Speed
Engineering teams are generating more shippable code than ever before — and today, Harness is shipping five new capabilities designed to help teams release confidently. AI coding assistants lowered the barrier to writing software, and the volume of changes moving through delivery pipelines has grown accordingly. But the release process itself hasn't kept pace.
The evidence shows up in the data. In our 2026 State of DevOps Modernization Report, we surveyed 700 engineering teams about what AI-assisted development is actually doing to their delivery. The finding stands out: while 35% of the most active AI coding users are already releasing daily or more, those same teams have the highest rate of deployments needing remediation (22%) and the longest MTTR at 7.6 hours.
This is the velocity paradox: the faster teams can write code, the more pressure accumulates at the release, where the process hasn't changed nearly as much as the tooling that feeds it.
The AI Delivery Gap
What changed is well understood. For years, the bottleneck in software delivery was writing code. Developers couldn't produce changes fast enough to stress the release process. AI coding assistants changed that. Teams are now generating more change across more services, more frequently than before — but the tools for releasing that change are largely the same.
In the past, DevSecOps vendors built entire separate products to coordinate multi-team, multi-service releases. That made sense when CD pipelines were simpler. It doesn't make sense now. At AI speed, a separate tool means another context switch, another approval flow, and another human-in-the-loop at exactly the moment you need the system to move on its own.
The tools that help developers write code faster have created a delivery gap that only widens as adoption grows.
What Harness Is Shipping
Today Harness is releasing five capabilities, all natively integrated into Continuous Delivery. Together, they cover the full arc of a modern release: coordinating changes across teams and services, verifying health in real time, managing schema changes alongside code, and progressively controlling feature exposure.
Coordinate multi-team releases without the war room
Release Orchestration replaces Slack threads, spreadsheets, and war-room calls that still coordinate most multi-team releases. Services and the teams supporting them move through shared orchestration logic with the same controls, gates, and sequence, so a release behaves like a system rather than a series of handoffs. And everything is seamlessly integrated with Harness Continuous Delivery, rather than in a separate tool.
Know when to stop — automatically
AI-Powered Verification and Rollback connects to your existing observability stack, automatically identifies which signals matter for each release, and determines in real time whether a rollout should proceed, pause, or roll back. Most teams have rollback capability in theory. In practice it's an emergency procedure, not a routine one. Ancestry.com made it routine and saw a 50% reduction in overall production outages, with deployment-related incidents dropping significantly.
Ship code and schema changes together
Database DevOps, now with Snowflake support, brings schema changes into the same pipeline as application code, so the two move together through the same controls with the same auditability. If a rollback is needed, the application and database schema can rollback together seamlessly. This matters especially for teams building AI applications on warehouse data, where schema changes are increasingly frequent and consequential.
Roll out features gradually, measure what actually happens
Improved pipeline and policy support for feature flags and experimentation enables teams to deploy safely, and release progressively to the right users even though the number of releases is increasing due to AI-generated code. They can quickly measure impact on technical and business metrics, and stop or roll back when results are off track. All of this within a familiar Harness user interface they are already using for CI/CD.
Warehouse-Native Feature Management and Experimentation lets teams test features and measure business impact directly with data warehouses like Snowflake and Redshift, without ETL pipelines or shadow infrastructure. This way they can keep PII and behavioral data inside governed environments for compliance and security.
These aren't five separate features. They're one answer to one question: can we safely keep going at AI speed?
From Deployment to Verified Outcome
Traditional CD pipelines treat deployment as the finish line. The model Harness is building around treats it as one step in a longer sequence: application and database changes move through orchestrated pipelines together, verification checks real-time signals before a rollout continues, features are exposed progressively, and experiments measure actual business outcomes against governed data.
A release isn't complete when the pipeline finishes. It's complete when the system has confirmed the change is healthy, the exposure is intentional, and the outcome is understood.
That shift from deployment to verified outcome is what Harness customers say they need most. "AI has made it much easier to generate change, but that doesn't mean organizations are automatically better at releasing it," said Marc Pearce, Head of DevOps at Intelliflo. "Capabilities like these are exactly what teams need right now. The more you can standardize and automate that release motion, the more confidently you can scale."
Release Becomes a System, Not a Scramble
The real shift here is operational. The work of coordinating a release today depends heavily on human judgment, informal communication, and organizational heroics. That worked when the volume of change was lower. As AI development accelerates, it's becoming the bottleneck.
The release process needs to become more standardized, more repeatable, and less dependent on any individual's ability to hold it together at the moment of deployment. Automation doesn't just make releases faster. It makes them more consistent, and consistency is what makes scaling safe.
For Ancestry.com, implementing Harness helped them achieve 99.9% uptime by cutting outages in half while accelerating deployment velocity threefold.
At Speedway Motors, progressive delivery and 20-second rollbacks enabled a move from biweekly releases to multiple deployments per day, with enough confidence to run five to 10 feature experiments per sprint.
AI made writing code cheap. Releasing that code safely, at scale, is still the hard part.
Harness Release Orchestration, AI-Powered Verification and Rollback, Database DevOps, Warehouse-Native Feature Management and Experimentation, and Improve Pipeline and Policy support for FME are available now. Learn more and book a demo.
From Chaos to Control: Vol 1

Announcing Snowflake Support for Harness DB DevOps
Data platforms are evolving rapidly, and Snowflake has become a cornerstone of modern data architectures. Teams rely on Snowflake to power analytics, machine learning, and business intelligence, but managing data warehouse changes in a safe, repeatable way can still be a challenge.
Today, we’re excited to announce Snowflake support for Harness DB DevOps, enabling teams to bring the same automation, governance, and reliability they expect from application DevOps to their Snowflake data warehouse changes. By combining application and Snowflake deployments into a consistent pipeline, teams can release confidently at speed.
With this release, organizations can now manage Snowflake schema changes using pipeline-driven database DevOps workflows directly within Harness.
The Challenge: Managing Snowflake Changes at Scale
Snowflake empowers teams to move fast with data, but data warehouse change management often remains a manual or fragmented process.
Common challenges include:
- Manual change deployments that introduce risk and slow down releases
- Limited visibility into schema changes across environments
- Inconsistent promotion workflows between development, staging, and production
- Difficulty enforcing governance and approvals
Without a standardized process, teams struggle to balance speed, control, and reliability.
Bringing Database DevOps to Snowflake
Harness DB DevOps now supports Snowflake as a first-class database platform, allowing teams to manage schema changes through automated, pipeline-driven workflows.
This means Snowflake schema changes can now be treated just like application code—versioned, tested, and promoted through environments using Harness pipelines.
With Snowflake support, teams can:
- Automate schema deployments using Harness pipelines
- Version control schema changes alongside application code
- Promote changes across environments with consistency and auditability
- Enforce approvals and governance policies before production releases
- Track and audit deployments with full visibility
The result is a modern Database DevOps workflow for Snowflake that helps teams release faster without sacrificing reliability.
Key Capabilities
Native Snowflake Integration
Harness DB DevOps can now connect directly to Snowflake environments, allowing teams to deploy and manage schema changes seamlessly.
Automated Database Change Pipelines
Use Harness pipelines to automate Snowflake data warehouse deployments with repeatable workflows across environments.
Governance and Control
Leverage Harness approval gates, role-based access controls, and policy enforcement to ensure safe production changes.
Deployment Visibility and Auditability
Track every Snowflake change deployment with full pipeline visibility and audit logs.
Why This Matters
As organizations increasingly rely on Snowflake to power data-driven applications, database changes need the same rigor and automation as application deployments.
By bringing Snowflake into Harness DB DevOps, teams can:
- Reduce manual deployment risk
- Improve collaboration between developers and data teams
- Standardize data warehouse release processes
- Accelerate delivery of data platform changes
Getting Started
Snowflake support for Harness DB DevOps is now available.
To get started:
- Configure a Snowflake database connection in Harness
- Add Snowflake change scripts to your repository
- Create a Harness pipeline to deploy and promote changes
- Automate Snowflake releases with confidence
Learn More
To learn more about using Snowflake with Harness DB DevOps, check out our documentation or schedule a demo.
Related Snowflake Topics

What Is a Software Catalog? A Guide for Modern DevOps Teams
How a Software Catalog Powers DevOps at Scale
Managing hundreds of microservices without a centralized system of record leads to scattered ownership, duplicate pipelines, and compliance gaps that slow delivery. Understanding software catalogs and their benefits is essential for platform teams looking to scale delivery without compromising governance or developer velocity.
Beyond Inventory: The Catalog as Platform Backbone
A software catalog does more than just list services. It acts as a central hub, connecting each service to its owners, environments, deployment pipelines, compliance rules, and SLOs.
With this central hub, developers can help themselves. They can find dependencies, see the impact of changes, and use approved patterns without hunting through scattered docs or relying on team knowledge.
Operational Benefits: From Bespoke to Standardized
The catalog integrates with Harness’s reusable templates, so building pipelines takes minutes rather than days. Platform teams need only manage a few standard templates that update automatically, rather than handle hundreds of separate setups.
You can build pipelines visually or with code, and the central view eliminates GitOps tool sprawl by showing everything in one place. Automated workflows move changes through environments based on set policies and checks, so you don’t need manual steps.
Governance by Design: Compliance Without Friction
Modern software catalogs build governance right into delivery workflows with OPA policies, audit trails that can’t be changed, and deployment freeze windows. These controls work with GitOps workflows, so developers keep their freedom while the company stays compliant.
Teams can use the catalog independently, while policy-as-code automatically handles security, approvals, and change management.
Managing Microservices Sprawl With a Software Catalog
When you manage hundreds of microservices across many CD setups, it’s hard to see what’s going on. Manual promotion, scattered ownership information, and compliance tracking all slow things down, but a software catalog can fix these problems.
- Centralize service ownership with authoritative metadata linking each service to owners, repositories, dependencies, and on-call contacts
- Publish golden path templates through reusable deployment strategies that embed security and compliance while allowing controlled developer customization
- Generate pipelines instantly using AI-powered automation that creates production-ready deployments from plain English requests
- Automate dependency tracking to visualize service relationships and predict impact scope (blast radius) during rollouts or incidents
- Enforce regulatory compliance through policy-as-code that applies consistent approval workflows and audit trails across your entire service ecosystem
This method makes managing microservices easier and more scalable by replacing manual work with automated discovery and self-service via rules. Teams get a clear view of compliance, and developers can still deliver features quickly and safely.
Best Practices for Implementing a Software Catalog in Enterprise CI/CD
Start by mapping out your catalog’s main parts before picking tools. Define key elements like services, environments, pipelines, policies, and scorecards, and make sure their relationships are clear. Use labels and categories that match your company’s structure to make incident handling and releases easier.
By focusing on data first, you create a single source of truth that pipelines can access via REST APIs and automated links. This makes it easier for developers to manage hundreds of microservices.
Once your data model is set, build a template strategy that can grow with it. Create golden paths for common deployment types, such as canary and blue-green releases. Use insert-block templates so developers can customize while keeping key steps and safety checks. Harness’s flexible templates make it easy for platform teams to share reusable pipeline parts that developers can use for new services.
After setting up templates, add governance by using OPA-based policies for secrets, approvals, and deployment windows right in your pipelines. Make sure template updates are automatically pushed out so every service receives security fixes and policy changes. Harness’s policy-as-code provides immutable audit trails and central policy management, so teams can move fast while still meeting compliance requirements.
Software Catalog FAQs for DevOps and Platform Teams
Platform engineers managing hundreds of services often have questions about catalog tooling, compliance integration, and GitOps coordination. The following answers explain how catalogs differ from traditional IT inventory systems and integrate with modern delivery pipelines to reduce operational overhead.
What's the difference between a software catalog, a CMDB, and tools like Backstage?
A Configuration Management Database (CMDB) tracks infrastructure assets and configuration states for IT operations. A software catalog focuses on service metadata, ownership, and delivery pipelines for development teams. Backstage is an open-source developer portal that can implement catalog functionality, while platforms like Harness provide centralized management layers as enterprise control planes with built-in governance and AI-powered automation.
How do software catalogs support compliance and governance in continuous delivery workflows?
Catalogs centralize policy enforcement using OPA-based rules, audit trails, and template propagation across pipelines. They provide compliance artifacts such as SBOMs, security attestations, and approval workflows required by frameworks like NIST SSDF. This approach embeds compliance into delivery, enabling governance without added friction.
How does a catalog integrate with Argo or Harness CD and GitOps to solve visibility and orchestration gaps?
Catalogs provide the metadata layer that connects GitOps deployments to service ownership, dependencies, and policies. Harness acts as a centralized management layer, aggregating multiple Argo or Harness CD instances into unified dashboards while adding release orchestration and AI-powered verification. This solves tool sprawl by centralizing visibility and enabling coordinated promotions across environments.
Can software catalogs help with incident response and troubleshooting?
Catalogs accelerate incident response by linking services to on-call teams, runbooks, and dependency maps. When issues occur, responders immediately see service owners, recent deployments, and related components. Research shows that GitOps automation reduces configuration drift detection and remediation times, and that catalogs enhance this by providing the service context needed for rapid root-cause analysis.
How do catalogs scale with AI-accelerated development?
As AI coding assistants increase commit velocity, catalogs help deployment processes keep pace through automated pipeline generation and template reuse. Context-aware AI can use catalog metadata to generate production-ready pipelines in minutes. This prevents deployment bottlenecks, supporting the productivity gains of AI-assisted development while maintaining governance and safety standards.
From Inventory to Impact: Operationalizing Your Software Catalog
With GitOps workflows and automated governance, software catalogs become the backbone of your platform. Golden paths, central dashboards, and policy-as-code turn catalog entries into self-service deployment pipelines capable of handling hundreds of microservices.
Start with one golden path template and a single view of all GitOps tool setups. As teams use catalog-driven delivery, you can add release orchestration. This way, building pipelines takes minutes instead of days, and you maintain enterprise governance with automated checks and rollbacks that keep pace with the speed of AI-generated code.
Harness gives you an AI-powered control plane and a GitOps dashboard for enterprises. This turns your software catalog from a simple list into a dynamic tool for automated, governed delivery.

Database Governance with OPA in Harness DB DevOps
Database systems store some of the most sensitive data of an organization such as PII, financial records, and intellectual property, making strong database governance non-negotiable. As regulations tighten and audit expectations increase, teams need governance that scales without slowing delivery.
Harness Database DevOps addresses this by applying policy-driven governance using Open Policy Agent (OPA). With OPA policies embedded directly into database pipelines, teams can automatically enforce rules, capture audit trails, and stay aligned with compliance requirements. This blog outlines how to use OPA in Harness to turn database compliance from a manual checkpoint into a built-in, scalable part of your DevOps workflow.
The Challenges of Database Compliance
Organizations face multiple challenges when navigating database compliance:
- Complex Regulatory Requirements: Standards such as GDPR, HIPAA, PCI-DSS, and SOX impose strict controls on data access, consent, storage, and processing. Compliance requires both preventative controls (e.g., access restrictions) and demonstrable evidence of effective enforcement.
- Lack of Visibility: Traditional database operations often lack centralized oversight, making it difficult to answer questions like “Who accessed data?”, “Which change was deployed?” or “Were controls enforced consistently?” without expensive, manual processes.
- Manual Processes and Human Error: Manual access approvals, change reviews, or ad-hoc scripting introduce risks, from privilege creep to inconsistent documentation that can lead to compliance gaps.
These challenges highlight the necessity of embedding governance directly into database development and deployment pipelines, rather than treating compliance as a reactive checklist.
Governance at Scale with Harness Database DevOps
Harness Database DevOps is designed to offer a comprehensive solution to database governance - one that aligns automation with compliance needs. It enables teams to adopt policy-driven controls on database change workflows by integrating the Open Policy Agent (OPA) engine into the core of database DevOps practices.
What is OPA and Policy as Code?
Open Policy Agent (OPA) is an open-source, general-purpose policy engine that decouples policy decisions from enforcement logic, enabling centralized governance across infrastructures and workflows. Policies in OPA are written in the Rego declarative language, allowing precise expression of rules governing actions, access, and configurations.
Harness implements Policy as Code through OPA, enabling teams to store, test, and enforce governance rules directly within the database DevOps lifecycle. This model ensures that compliance controls are consistent, auditable, and automatically evaluated before changes reach production.
Building a Governance Framework Using OPA Policies
Here’s a structured approach to implementing database governance with OPA in Harness:
1. Define Compliance and Governance Objectives
Start by cataloging your regulatory obligations and internal governance policies. Examples include:
- Restricting access to sensitive tables based on roles or departments.
- Prohibiting destructive schema changes (e.g., DROP TABLE) in production.
- Enforcing least privilege by limiting modify rights only to authorized service accounts.
- Requiring reviews and approvals for schema migrations above a threshold.
Translate these requirements into quantifiable rules that can be expressed in Rego.
2. Author OPA Policies in Harness
Within the Harness Policy Editor, define OPA policies that codify governance rules. For example, a policy might block any migrations containing operations that remove columns in production environments without explicit DBA approval.
Harness policies are modular and reusable, you can import and extend them as part of broader governance packages. This allows cross-team reuse and centralized management of rules. Key aspects include:
- Policy Modules: Group related rules into packages for clarity.
- Policy Severity: Optionally set enforcement thresholds (e.g., error vs. warning).
- Testing and Simulation: Harness provides testing tools to validate policies against real or sample inputs before activation.
By expressing governance as code, you ensure consistency and remove ambiguity in policy enforcement.
3. Integrate Policies with CI/CD Pipelines
Policies can be linked to specific triggers within your database deployment workflow, for instance, evaluating rules before a migration is applied or before a pipeline advances to production. This integration ensures that non-compliant changes are automatically blocked, while compliant changes proceed seamlessly, maintaining the balance between speed and control.
Operationalizing Database Compliance
Automated Enforcement
Harness evaluates OPA policies at defined decision points in your pipeline, such as pre-deployment checks. This prevents risky actions, enforces access controls, and aligns every deployment with governance objectives without manual intervention.
Audit Trails and Traceability
Every policy evaluation is logged, creating an auditable trail of who changed what, when, and why. These logs serve as critical evidence during compliance audits or internal reviews, reducing the overhead and risk associated with traditional documentation practices.
Role-Based Controls and Least Privilege
By enforcing the principle of least privilege, policies ensure that users and applications possess only the necessary permissions for their specific roles. This restriction on access is crucial for minimizing the potential attack surface and maintaining compliance with regulatory requirements for data access governance.
Best Practices for Policy-Driven Governance
- Start with High-Impact Policies: Prioritize controls around sensitive data and production environments.
- Leverage Policy Libraries: Use reusable policy templates as a starting point and customize them for your organizational context.
- Iterate with Continuous Feedback: Use audit results and pipeline failures as feedback loops to refine policies.
- Align with Compliance Frameworks: Map OPA policies to specific regulatory requirements (e.g., GDPR’s principle of accountability) to demonstrate traceability during audits.
- Educate Teams: Ensure developers and DBAs understand the governance policies and the reasons behind them to reduce friction.
Conclusion
Database governance is an essential pillar of enterprise compliance strategies. By embedding OPA-based policy enforcement within Harness Database DevOps, organizations can automate compliance controls, minimize risk, and maintain developer productivity. Policy as Code provides a scalable, auditable, and consistent framework that aligns with both regulatory obligations and the need for agile delivery.
Transforming database governance from a manual compliance burden into an automated, integrated practice empowers teams to innovate securely, confidently, and at scale - ensuring that every change respects the policies that protect your data, your customers, and your brand.

Database Schema Evolution: Designing for Continuous Change
There was a time when database design was an event. It happened once, early in a project, often before the first line of application code was written. Architects would gather with domain experts, sketch entities and relationships, debate normalization levels, and arrive after weeks of discussion, at what was believed to be the schema. Once approved, that schema was treated as immutable.
This mindset assumed that the future was predictable. But it rarely is. Modern database design is no longer about defining a perfect schema upfront, but about enabling safe, continuous evolution as systems and requirements change.
Database Design Is Not a One-Time Event
At the beginning, requirements are usually clear and limited. The schema reflects the system’s first understanding of the domain.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL UNIQUE,
created_at TIMESTAMP NOT NULL DEFAULT NOW()
);This design is clean, minimal, and correct, for now. It models what the system knows today: users exist, they have an email, and they were created at a specific time.
At this stage, the schema feels complete, although it never is.
When Reality Adds Context
As the product matures, new questions emerge. The business wants to personalize communication. Support wants to address users by name. Marketing wants segmentation. The schema evolves, not because it was poorly designed, but because the system learned something new.
ALTER TABLE users
ADD COLUMN first_name VARCHAR(100),
ADD COLUMN last_name VARCHAR(100);
This change is small, additive, and safe. No existing behavior breaks. No data is lost. The schema now captures richer context without invalidating earlier assumptions.
This is evolutionary design in its simplest form: adapting without disruption.
Managing Database Schema Changes Without Breaking Production
As usage grows, teams discover new workflows. Users can now deactivate their accounts. Regulatory requirements demand traceability.
Instead of redefining the table, the schema evolves to support new behavior.
ALTER TABLE users
ADD COLUMN status VARCHAR(20) NOT NULL DEFAULT 'ACTIVE',
ADD COLUMN deactivated_at TIMESTAMP;
Importantly, this change preserves backward compatibility. Existing queries continue to work. New logic can gradually adopt the new fields. This approach reflects database schema evolution best practices, where changes are incremental, backward-compatible, and safely deployable through CI/CD pipelines. Evolutionary design favors extension over replacement.
Performance Pressures and Structural Refinement
With scale comes performance pressure. Queries that once ran instantly now struggle. Reporting workloads introduce new access patterns.
Rather than redesigning everything, the schema evolves structurally to meet new demands.
CREATE INDEX idx_users_status ON users (status);This change does not alter the data model conceptually, but it reflects a deeper understanding of how the system is used. Design evolves not just for correctness, but for operational reality.
Database design is no longer theoretical, it is informed by production behavior.
When the Original Model No Longer Fits
Eventually, teams outgrow early assumptions. A single user’s table can no longer represent multiple user roles, tenants, or identity providers. The model needs refinement. Evolutionary design handles this carefully, through parallel structures and gradual migration.
CREATE TABLE user_profiles (
user_id INT PRIMARY KEY REFERENCES users(id),
display_name VARCHAR(150),
preferences JSONB,
updated_at TIMESTAMP NOT NULL DEFAULT NOW()
);
Instead of overloading the original table, the design evolves by extracting responsibility. Existing functionality remains stable while new capabilities move forward. At no point was a “big rewrite” required.
The Operational Risks of Unmanaged Database Schema Changes
As changes accumulate, complexity shifts from design to operations. Teams struggle to answer basic questions:
- Which version of the schema is running in production?
- What changes are pending in staging?
- Can this migration be safely rolled back?
This is where evolutionary design demands discipline. Small changes only remain safe when they are visible, validated, and governed.
Why Database DevOps Matters for Schema Evolution?
Modern database design extends beyond tables and columns. It includes how changes are reviewed, tested, approved, and promoted. As applications adopt CI/CD and ship continuously, databases often remain the slowest and riskiest part of the release. Manual migrations, limited visibility, and fear of rollbacks turn schema changes into operational bottlenecks.
Database DevOps addresses this gap by applying software delivery discipline to database changes:
- Schema changes are versioned and traceable
- Migrations are validated before production
- Rollbacks are tested, not improvised
- Audit trails are automatic, preventing high-risk changes from reaching production
By embedding database schema evolution into CI/CD pipelines, teams reduce deployment risk while increasing delivery velocity. Platforms like Harness Database DevOps enable this by combining state awareness, controlled execution, and auditability, making database changes predictable, repeatable, and safe.
The Database as a Record of Learning
Each SQL change tells a story:
- What the system learned
- What assumptions changed
- What scale revealed
- What compliance required
A database is not a monument to early decisions. It is a living artifact that reflects the system’s understanding of its domain at every point in time.
Conclusion: Evolution is the Design
Database design evolution is not a failure of planning, it is evidence of adaptation.
The most resilient systems are not those with perfect initial schemas, but those designed to evolve safely and continuously. By embracing incremental change, versioned history, and automated governance, teams align database design with the realities of modern software delivery.
In a world where applications never stop shipping, database design cannot remain static. They must evolve, with confidence, control, and clarity, supported by Database DevOps practices and platforms such as Harness Database DevOps.
Because in the end, the schema is not the design. The ability to evolve it safely is.

Open Source Liquibase MongoDB Native Executor by Harness
Harness Database DevOps is introducing an open source native MongoDB executor for Liquibase Community Edition. The goal is simple: make MongoDB workflows easier, fully open, and accessible for teams already relying on Liquibase without forcing them into paid add-ons.
This launch focuses on removing friction for open source users, improving MongoDB success rates, and contributing meaningful functionality back to the community.
Why Does Liquibase MongoDB Support Matter for Open Source Users?
Teams using MongoDB often already maintain scripts, migrations, and operational workflows. However, running them reliably through Liquibase Community Edition has historically required workarounds, limited integrations, or commercial extensions.
This native executor changes that. It allows teams to:
- Run existing MongoDB scripts directly through Liquibase Community Edition.
- Avoid rewriting database workflows just to fit tooling limitations.
- Keep migrations versioned and automated alongside application CI/CD.
- Stay within a fully open source ecosystem.
This is important because MongoDB adoption continues to grow across developer platforms, fintech, eCommerce, and internal tooling. Teams want consistency: application code, infrastructure, and databases should all move through the same automation pipelines. The executor helps bring MongoDB into that standardised DevOps model.
It also reflects a broader philosophy: core database capabilities should not sit behind paywalls when the community depends on them. By open-sourcing the executor, Harness is enabling developers to move faster while keeping the ecosystem transparent and collaborative.
Liquibase MongoDB Native Executor: What It Enables In Community Edition
With the native MongoDB executor:
- Liquibase Community can execute MongoDB scripts natively
- Teams can reuse existing operational scripts
- Database changes become traceable and repeatable
- Migration workflows align with CI/CD practices
This improves the success rate for MongoDB users adopting Liquibase because the workflow becomes familiar rather than forced. Instead of adapting MongoDB to fit the tool, the tool now works with MongoDB.
How To Install The Liquibase MongoDB Extension (Step-By-Step)
1. Getting started is straightforward. The Liquibase MongoDB extension is hosted on HAR registry, which can be downloaded by using below command:
curl -L \
"https://us-maven.pkg.dev/gar-prod-setup/harness-maven-public/io/harness/liquibase-mongodb-dbops-extension/1.1.0-4.24.0/liquibase-mongodb-dbops-extension-1.1.0-4.24.0.jar" \
-o liquibase-mongodb-dbops-extension-1.1.0-4.24.0.jar
2. Add the extension to Liquibase: Place the downloaded JAR file into the Liquibase library directory, example path: "LIQUIBASE_HOME/lib/".
3. Configure Liquibase: Update the Liquibase configuration to point to the MongoDB connection and changelog files.
4. Run migrations: Use the "liquibase update" command and Liquibase Community will now execute MongoDB scripts using the native executor.
Generating MongoDB Changelogs From A Running Database
Migration adoption often stalls when teams lack a clean way to generate changelogs from an existing database. To address this, Harness is also sharing a Python utility that mirrors the behavior of "generate-changelog" for MongoDB environments.
The script:
- Connects to a live MongoDB instance
- Reads configuration and structure
- Produces a Liquibase-compatible changelog
- Helps teams transition from unmanaged MongoDB to versioned workflows
This reduces onboarding friction significantly. Instead of starting from scratch, teams can bootstrap changelogs directly from production-like environments. It bridges the gap between legacy MongoDB setups and modern database DevOps practices.
Why Is Harness Contributing This To Open Source?
The intent is not just to release a tool. The intent is to strengthen the open ecosystem.
Harness believes:
- Foundational database capabilities should remain accessible.
- Community users deserve production-ready tooling.
- Open contributions drive innovation faster than closed ecosystems.
By contributing a native MongoDB executor:
- Liquibase Community users gain real functionality.
- MongoDB adoption inside DevOps workflows becomes easier.
- The ecosystem remains open and collaborative.
- Higher success rate for MongoDB users adopting Liquibase Community.
This effort also reinforces Harness as an active open source contributor focused on solving real developer problems rather than monetizing basic functionality.
The Most Complete Open Source Liquibase MongoDB Integration Available Today
The native executor, combined with changelog generation support, provides:
- Script execution
- Migration automation
- Changelog creation from running environments
- CI/CD alignment
Together, these create one of the most functional open source MongoDB integrations available for Liquibase Community users. The objective is clear: make it the default path developers discover when searching for Liquibase MongoDB workflows.
Start Using and Contributing to Liquibase MongoDB Today
Discover the open-source MongoDB native executor. Teams can adopt it in their workflows, extend its capabilities, and contribute enhancements back to the project. Progress in database DevOps accelerates when the community collaborates and builds in the open.

NoSQL Change Control for Compliance
As modern organizations continue their shift toward microservices, distributed systems, and high-velocity software delivery, NoSQL databases have become strategic building blocks. Their schema flexibility, scalability, and high throughput empower developers to move rapidly - but they also introduce operational, governance, and compliance risks. Without structured database change control, even a small update to a NoSQL document, key-value pair, or column family can cascade into production instability, data inconsistency, or compliance violations.
To sustain innovation at scale, enterprises need disciplined database change control for NoSQL - not as a bottleneck, but as an enabler of secure and reliable application delivery.
The Hidden Risks of Uncontrolled NoSQL Changes
Unlike relational systems, NoSQL databases place schema flexibility in the hands of developers. And the enterprises that rely on such NoSQL Database at scale are discovering the following truths:
- Flexibility without governance leads to instability.
- Data models must evolve as safely as application code.
- Compliance cannot rely on manual best-effort processes.
With structured change control:
- Schemas are versioned and peer-reviewed in Git
- Rollbacks are deterministic
- Environments stay consistent
- Audits pass without firefighting
- Data governance policies enforce themselves
- Compliance requirements (including GDPR’s “data integrity and confidentiality” mandate) are automatically met
NoSQL’s agility remains intact but reliability, safety, and traceability are added.
Database Change Control as Part of CI/CD
To eliminate risk and release bottlenecks, NoSQL change control needs to operate inside CI/CD pipelines - not outside them. This ensures that:
- Database updates are stored in Git as the system of record
- Pull requests enforce approvals and peer review
- Pipeline-driven testing validates the impact of schema changes before deployment
- Deployment logs provide traceability for governance and audit teams
A database change ceases to be a manual, tribal-knowledge activity and becomes a first-class software artifact - designed, tested, versioned, deployed, and rolled back automatically.
How Harness Safeguards NoSQL Change Delivery
Harness Database DevOps extends CI/CD best practices to NoSQL by providing automated delivery, versioning, governance, and observability across the entire change lifecycle, including MongoDB. Instead of treating database changes as a separate operational track, Harness unifies database evolution with modern engineering practices:
- DataMigration-as-Code stored in Git
- Automated verification before deployment
- Impact analysis and data preview
- Pipeline-level enforcement across every stage
- End-to-end audit trails and compliance logging
- Governed rollbacks and non-destructive deployments
This unification allows enterprises to move fast and maintain control, without rewriting how teams work.
The Competitive Advantage of Doing This Right
High-growth teams that adopt change control for NoSQL environments report:
- Greater deployment confidence with lower production incident rates
- Sustained release velocity - without sacrificing data quality or security
- Reduced operational burden associated with GDPR, auditing, and governance
- Better alignment across developers, DBAs, SREs, and platform engineering
In short, the combination of NoSQL flexibility and automated governance allows enterprises to scale without trading speed for stability.
Final Thoughts
NoSQL databases have become fundamental to modern application architectures, but flexibility without control introduces operational risk. Implementing structured database change control - supported by CI/CD automation, runtime policy enforcement, and data governance - ensures that NoSQL deployments remain safe, compliant, and resilient even at scale.
Harness Database DevOps provides a unified platform for automating change delivery, enforcing compliance dynamically, and securing the complete database lifecycle - without slowing down development teams.