
At 2 am, your migration goes live. By 2:07, error rates spike, and rollback isn’t an option. Cloud migrations, API rewrites, and architecture transformations rarely fail because of bad code. They fail because of how that code is released.
Most teams still rely on a “big bang” cutover where infrastructure, services, and user-facing changes go live at once. This concentrates risk into a single moment. When something breaks, rollback is slow, visibility is limited, and the blast radius is large.
This is not just anecdotal. According to BCG, more than half of transformation efforts fail to achieve their intended outcomes within three years.
The difference between success and failure is not the migration itself. It is the release strategy.
Cloud Migration Is Not a Single Change
“Cloud migration” sounds simple, but in practice, it is a layered transformation.
Most migrations combine several of the following:
- Monolith to microservices
- API or data pipeline rewrites
- Frontend or UI rebuilds
- On-prem to cloud infrastructure moves
- Introduction of new service layers
These rarely happen in isolation. Teams often try to ship them together in a single coordinated release. That coupling increases complexity and multiplies risk.
Before your next migration, list every system involved. If they are all released together, you are carrying unnecessary risk.
The Core Anti-Pattern: Big Bang Releases
The failure mode is consistent:
- A new service is deployed
- Infrastructure flips to the cloud
- A redesigned UI is released
- All at once
There is no safe way to validate behavior in production. There is no gradual exposure. Rollback often requires redeploying an old stack that may no longer be compatible.
Even worse, teams lack a reliable baseline. They cannot answer simple questions:
- Is performance better?
- Is the cost lower?
- Is reliability improved?
Without that, migration becomes guesswork.
Decoupling Deployment from Release
Modern teams are adopting a different model:
- Deploy code anytime. Release it gradually.
Feature flags provide a control layer that separates deployment from exposure. Code can exist in production without being active for all users.
This enables:
- Controlled rollout by percentage, region, or cohort
- Instant rollback without redeployment
- Real-time measurement tied to specific changes
Start by putting one service behind a feature flag and releasing it to internal users first.
Progressive Delivery for Migrations
Replace Cutovers with Progressive Rollouts
Instead of switching everything at once:
- Deploy the new system alongside the old one
- Route a small percentage of traffic
- Observe behavior
- Increase exposure gradually
If something fails, you reduce traffic or revert instantly.
This shifts migration from a single high-risk event to a series of measurable steps.
The Strangler Fig Pattern in Practice
A common migration strategy is the strangler fig pattern.
- Build new functionality alongside the legacy system
- Gradually route traffic to the new components
- Retire legacy code over time
Feature flags make this executable in production by controlling routing and exposure. But to make this work in practice, you need a control layer that can manage traffic in real time.
How Progressive Migration Actually Works
Below is a simplified view of how feature flags act as a control plane during migration:
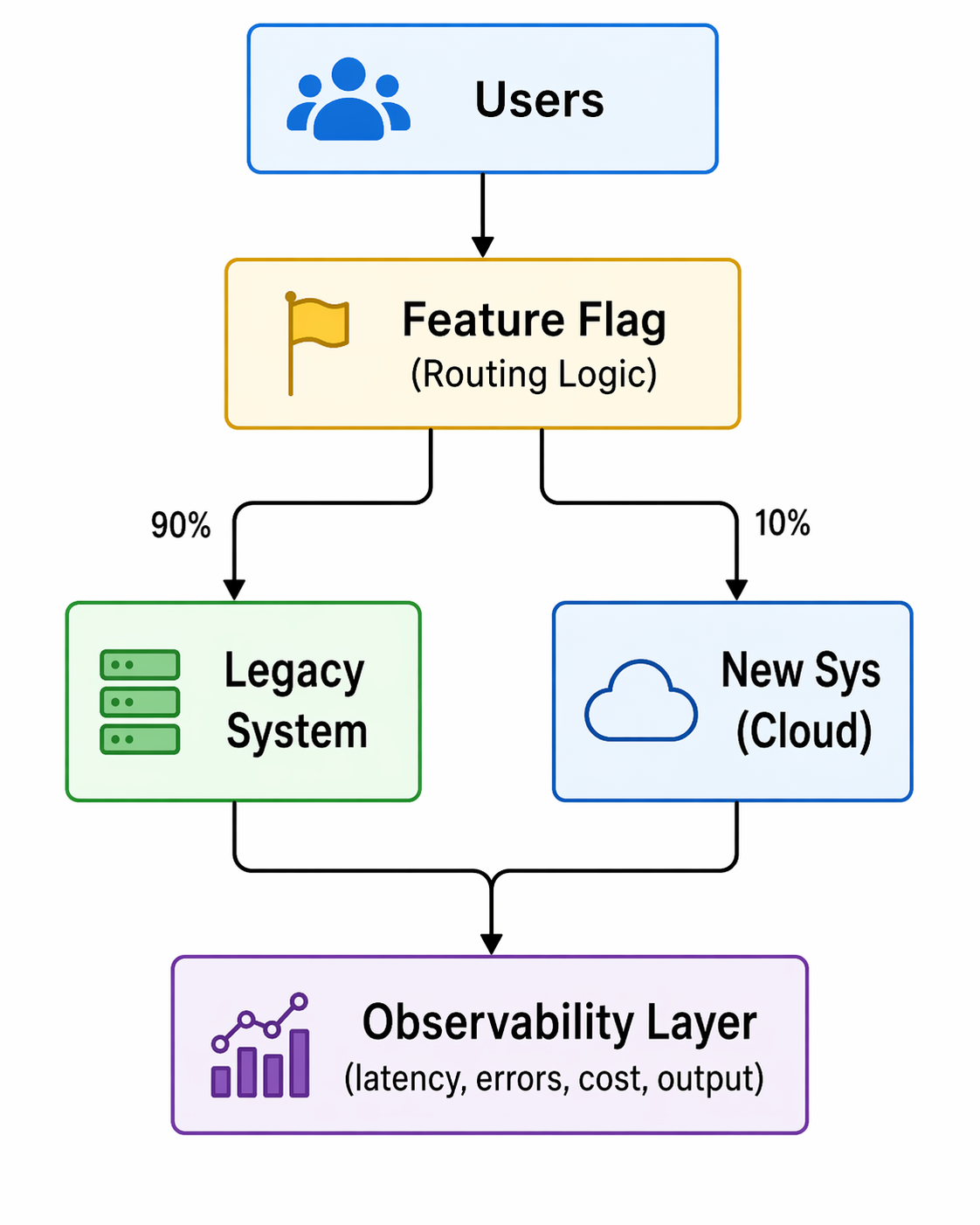
Fig: Feature-flag–driven progressive traffic routing during migration
Two things matter here:
- Routing control: traffic can be shifted gradually
- Measurement: metrics are tied to each variation
This is not just a toggle. It is a runtime decision and an observability layer.
Measure What Actually Matters
A successful migration is not defined by deployment success. It is defined by outcomes.
Key metrics include:
- Latency and throughput
- Error rates
- Infrastructure cost
- Output correctness
These metrics are not theoretical. They are what teams use to validate migrations in real production environments.
Real Example: Dual Pipeline Migration
In the Beyond the Toggle ebook, a legacy Spark batch pipeline was replaced with a streaming architecture, with a progressive rollout rather than a cutover.
- Both pipelines ran in production
- A feature flag routed traffic between them
- Metrics were compared in real time
The new system showed faster processing and lower costs before the full rollout.
From the webinar, teams often go further:
- Run both systems simultaneously
- Compare outputs for correctness
- Measure performance differences per request
This allows validation of both performance and data integrity before committing.
Define your baseline metrics before migration. If you cannot measure improvement, you cannot prove success.
Staging Lies. Production Doesn’t.
Staging environments cannot replicate production conditions. They lack:
- Real traffic patterns
- Data scale
- Edge cases
Feature flags enable safe production testing through controlled exposure.
Common Patterns
- Canary releases by percentage or region
- Cohort-based rollouts (geo, customer segment)
- Dual execution for validation
Not all canary releases are percentage-based. Some teams roll out by country or user segment first, then expand globally.
Guardrails
To make this safe:
- Automated rollback based on thresholds
- Feature-level observability
- Access control and audit logs
Decision Making: Continuous Go / No-Go
A migration is a sequence of decisions, not a single moment.
At each stage:
- Define the metric
- Measure impact
- Decide to expand or roll back
In one example from the webinar:
- A rollout reached 30% traffic
- Error rates increased
- Traffic was reduced to 20%
- The issue was isolated and fixed
- Rollout continued safely
This approach removes pressure from a single “launch moment” and distributes risk across stages.
Advanced Considerations for Developers
Feature Flag Performance and Reliability
Modern flag systems avoid becoming a bottleneck:
- Evaluations happen locally via SDKs
- Configurations are cached
- Systems continue operating even if the flag service is unavailable
This ensures minimal latency and high reliability.
Handling Complex Systems
Not all migrations are equal.
- Data pipelines and database paths require more planning
- Read and write paths may need staged transitions
- Flags still apply, but design complexity increases
The key is incremental transition, not avoidance.
Managing Flag Lifecycle and Tech Debt
Feature flags are temporary by design.
If left unmanaged, they accumulate and create complexity. Teams need:
- Visibility into flag state and usage
- Defined lifecycle policies
- Cleanup after full rollout
Emerging approaches include automation that detects stale flags and generates pull requests to remove them.
This Is a Delivery Strategy Change
Adopting progressive delivery is not just a tooling decision. It changes how teams release software.
Key considerations:
- Align with existing change management processes
- Integrate flags into CI/CD pipelines
- Maintain governance and auditability
Feature flags do not bypass controls. They enhance them by adding visibility and control at runtime.
What to Look for in a Feature Flag Platform
For migration use cases, a Feature Flag platform should provide:
- Tight integration with CI/CD pipelines
- Built-in experimentation and metrics
- Governance, approvals, and audit logs
- Developer-friendly SDKs and workflows
Flags should not feel like a bolt-on. They should be part of how software is built and released.
Conclusion: From Risk Event to Controlled Process
The biggest mistake teams make is treating migration as a moment.
It is not.
It is a controlled progression of changes, each validated in production under real conditions.
Feature flags enable this by:
- Decoupling deployment from release
- Enabling gradual exposure
- Providing real-time measurement
- Allowing instant rollback
The result is simple:
Migrations become reversible, observable, and data-driven.
Want a deeper breakdown of these patterns and real-world examples? Read the full ebook or see a demo.

All this author’s posts
Dewan Ahmed is a Principal Developer Advocate at Harness, a company that aims to enable every software engineering team in the world to deliver code reliably, efficiently and quickly to their users. Before joining Harness, he worked at IBM, Red Hat, and Aiven as a developer and QA lead.

All this author’s posts
Ryan Vila is passionate about using analytics to drive better product development. He believes modern development organizations need stronger ways to evaluate user experience and impact at a feature level—an area often overlooked even by highly agile teams.