
- Integrating A/B testing and feature flags directly into CI/CD pipelines empowers developers with self-service experimentation, while maintaining enterprise governance and security.
- Standardizing experimentation workflows—including flag management, guardrail metrics, and automated verification—reduces operational bottlenecks and technical debt across large engineering teams.
- AI-powered automation enable platform teams to scale safe experimentation. Intelligent tooling provides portfolio-level visibility and ROI measurement without sacrificing control or compliance.

With the acceleration of AI-assisted coding, spurring the velocity of software releases, the challenge of ensuring stable deployments is heightened, and platform teams are feeling the hit. The State of AI-assisted Software Development DORA report measured a negative impact on software delivery stability: “an estimated 7.2% reduction for every 25% increase in AI adoption.”
The DORA report advises:
Considered together, our data suggest that improving the development process does not automatically improve software delivery—at least not without proper adherence to the basics of successful software delivery, like small batch sizes and robust testing mechanisms.
A robust testing mechanism rapidly gaining momentum is testing in production. Let’s take a closer look at how this practice boosts software delivery stability and supports the software development lifecycle (SDLC). We’ll also consider how to make testing in production, specifically A/B testing at scale, work for you.
What is testing in production?
Testing in production (TIP) means testing new software code on live traffic in active real-world environments. TIP is complementary to pre-production testing and does not replace it. It does, however, carry tangible benefits:
- Real-World Validation. Tests new features in the actual production environment, measuring performance under real-world conditions and detecting issues that staging (due to lack of data variety) cannot catch.
- Speed & Efficiency. Eliminate the need to create and maintain expensive, multi-layered staging environments for heavy testing.
- Improved User Experience. Allows teams to quickly iterate on features where they create confirmed value, by means of tight feedback loops on real user data.
- Early Issue Detection: Equips your team to spot issues early on, by testing features in production in small amounts or with limited visibility. You can resolve the errors before they escalate or affect more customers.
Feature flags are instrumental in the practice of safe testing in production because they decouple deployment and exposure at the most granular level. By means of feature flags, you implement incremental feature release techniques and unlock progressive experimentation. With carefully crafted A/B testing, you empower rapid feedback loops that confirm real feature value, validate high quality software, and increase team productivity and satisfaction.
These testing and verification capabilities are crucial as never before in this “AI moment” where AI-assisted coding enjoys wide adoption and funding.
How A/B Testing Works
A/B testing is the process of simultaneously testing two different versions of a web page or product feature in order to optimize a behavioral or performance metric, while ensuring guardrail metrics are not negatively impacted. A/B testing spans the whole spectrum of software verification: you can safely carry out architectural validation on fundamental architectural changes or gather behavioral analytics on UI variations.
Progressive experimentation with feature flags lets you roll out changes to a small slice of users first, catch problems early, and expand only when the data looks good.
The key is keeping deployment and release separate. You decouple deployment and release by delivering new features in a dormant state. Code goes out behind a flag. You validate it with real traffic.
Why A/B Testing Belongs in Your CI/CD Pipeline
A/B testing built into your CI/CD pipeline means you're making data-driven decisions based on observed metrics. Advanced feature flagging correlates statistical data, with pinpoint precision, to the actual feature variation causing the impact. Even when multiple features are rolled out concurrently, an enterprise-grade feature management platform will effectively parse the data, alert you to the impactful variant, and enable you to roll back any negative feature in seconds. The time/cost savings and safety benefits are astounding.
A/B testing provides a great experience for both marketing teams and engineers:
- Marketers can enjoy the freedom to boldly conduct business experiments and conclusively determine the features that drive key performance indicators (KPIs) and return on investment (ROI).
- Engineers can confidently improve architecture and perform code refactoring, knowing these changes will be safely measured against guardrail metrics for real-world engineering verification.
An enterprise-level platform like Harness, provides Feature Management and Experimentation, bringing flags, monitoring, and full experimentation freedom into a finely-tuned, seamless end-to-end software delivery tech stack for your platform team. Integrating A/B testing and feature flags directly into CI/CD pipelines empowers your teams with self-service experimentation while maintaining enterprise governance and security.
Progressive exposure limits the blast radius
Bundling features into cliff-jump releases put every user account at risk simultaneously. A progressive ramp—starting with just 1 or 2% of traffic, and gradually increasing—means a bug in your checkout flow only affects a fraction of users before you catch it. Progressive delivery validates that SLOs are holding before exposure expands. p95 latency spiking? Error rate creeping up? You catch it when a tiny fraction of users are affected—not thousands—and Harness CD integrates cleanly with Jenkins, GitLab, or GitHub Actions.
The deploy-and-hold pattern is the keystone. Ship code in the "off" state behind a feature flag and nothing changes for users until you're ready. Deploy at 11 AM on a Tuesday instead of 1 AM on a Sunday. No change windows, no dashboard babysitting. Code is in production, the feature is dark, and you flip the switch when you're ready to monitor it. That's the freedom of progressive experimentation with feature flags in practice.
AI-assisted verification handles the noise
Raw telemetry is information in theory and chaos in practice. AI-powered monitoring watches flag-level metrics—not just "something is slower," but "checkout button variant B is adding 43ms of p95 latency." That specificity matters. When you have six active experiments running, your engineers are not flipping through dashboards trying to isolate which one broke something. The system tells you.
From Feature Flags to Experiments: Architecture That Works Seamlessly
If your team is already running feature flags with health monitoring, you're closer to a full experimentation platform than you might think. Targeting logic, rollout percentages, kill switches—that's already experiment infrastructure. What's missing is experiment tracking, statistical analysis, and deterministic assignment.
To implement experiments with your feature flagging:
- Build on existing flag infrastructure. Targeting, rollout percentages, and kill switches are already there. Add experiment tracking on top rather than running parallel systems. Harness Feature Management handles both in one place.
- Use stable user IDs for deterministic assignment. Consistent hashing keeps users in the same variant across sessions and devices. No drift, no contaminated data.
- Evaluate flags on the SDK side. Toggle decisions should be fast and deterministic. Local evaluation avoids remote call latency and keeps user data secure.
- Route alerts to features, not just systems. "Checkout variant B caused a +43ms p95 increase" is actionable; "Latency is up" isn't. Release monitoring with flag context makes rollback decisions take on surgical precision, and proper experimentation systems prevent sample ratio mismatch and bot traffic from skewing results.
An experimentation system built on top of your feature flagging makes A/B testing a cinch and eliminates operational bottlenecks and technical debt for your platform team.
CI/CD Workflow: Six Stages for Safe Experimentation
A/B testing doesn't have to be complicated. It can run as part of a structured rollout with automated KPI metrics and guardrails:
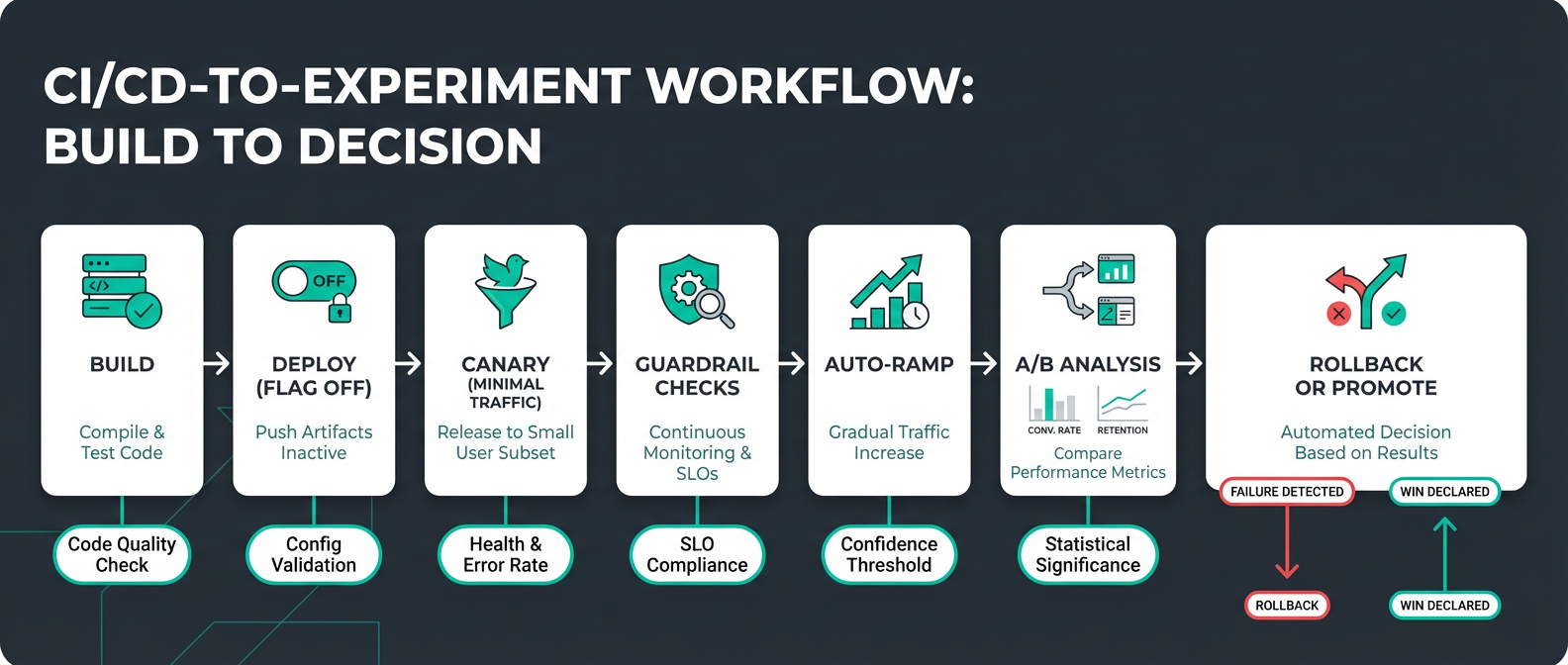
The seven stages are built into your pipeline and completed with minimal human intervention:
- Build and test. Catch issues before they ship. Pre-production unit, regression, smoke, and integration testing is incorporated into code builds and repository merges.
- Deploy, but keep new features inactive. Launch new features but keep them dark behind conditional statements that evaluate a feature flag. New features are in production but hidden.
- Canary at 1%. Enable the flag for a small slice of real traffic. This achieves engineering verification of new code under production traffic and processing loads. At this point, the blast radius of these issues is minimal and they are quickly isolated and resolved.
- Check guardrails. Automated monitoring reports error rate, latency, performance, and business KPIs. A powerful statistical analysis engine measures metrics for feature flag variants against the baseline, detects statistical significance, and alerts on positive or negative impact at the feature level.
- Auto-ramp. Expand the audience for each feature by progressively increasing real-user exposure as you continue to monitor guardrails, for example 1% → 5% → 25% → 50% → 75% → 100%. A deterministic feature flag assignment algorithm controls the gradual increase in audience size and ensures that users aren’t repeatedly flipped between feature variants.
- A/B Analysis. Automatically calculate metrics and generate data analysis charts for feature variant comparison. Executive dashboards show experiment velocity, win rates, and KPI lift to demonstrate ROI and guide strategic decisions.
- Auto-rollback or promote. Thresholds crossed? The system reverts a feature without waiting for a human to notice, while you sleep.
Sample sizes matter more than most teams realize
A common mistake is ramping too fast and drawing conclusions from thin data. If your sample size is too low, your experiment will be underpowered, and you will be unlikely to detect a reasonably-sized impact. Calculate that you have a large enough sample to be able to detect impacts of the size that are important to you.
Progressive experimentation requires patience. Premature conclusions produce unreliable results, and unreliable results produce bad decisions.
Governance isn't overhead, it's insurance
Every experiment should have a documented hypothesis, defined success metrics, blast radius assessment, and rollback plan before it touches production. Feature flag lifecycle management also keeps technical debt from quietly accumulating—flags that never get retired are toggle debt and a production surprise waiting to happen.
Turn Every Release Into a Measured Experiment
The goal isn't just fewer 3 a.m. incidents, though that's a welcome side effect. The real win is replacing gut feel with data at every stage of delivery.
With modern testing in production: feature flags decouple deploy from release, progressive ramps limit blast radius, AI-powered guardrails catch regressions before they spread, and centralized analytics replace the multi-tool sprawl that makes experimentation feel expensive.
Every time you release a feature you can ramp gradually up to 100% using percentage-based rollouts, alert on specific pre-decided latency increases, and enforce minimum sample sizes before promotion. Let every release become a decision backed by actual evidence, not optimism.
Harness Feature Management & Experimentation consolidates flags, release monitoring, and A/B testing, so every deployment is a controlled experiment—not a gamble.
Safe A/B Testing in Production: Frequently Asked Questions
How do you pick guardrail metrics without blocking every release?
Start with your existing SLO metrics and be conservative. Grafana's SLO guidance recommends event-based SLIs over percentiles for cleaner signals. Focus on business-critical user journeys first.
What's a practical ramp schedule for a mid-sized SaaS team?
Every team has slightly different criteria to consider before safely ramping up. Release monitoring with automated guardrails removes the need for someone to manually review metrics at each stage—which is the only way this actually scales.
How do you handle sample ratio mismatch?
Monitor assignment ratios continuously using chi-squared tests. Harness FME’s attribution and exclusion algorithm is honed to ensure accurate samples. In addition, FME reassesses experiment health in real-time, including sample ratio.
Filter bot traffic early too. Microsoft's bot detection research shows bots can skew conversion rates by 15–30%. Behavioral signals like sub-10-second session duration or unusual referrer patterns are a practical starting point for exclusion algorithms.
Should you A/B test infrastructure changes or just product features?
A/B testing works best for user-facing changes where behavior matters. Infrastructure changes are better suited to progressive rollouts with guardrail monitoring—different changes, different success metrics. Performance and reliability for engineering experiments; conversion and engagement for growth. Keep the tooling integrated in your pipeline either way.
How do you maintain consistent user experiences across devices and services?
Deterministic hashing on stable user IDs. Hash user ID plus experiment name to generate consistent assignments and make sure the same user sees the same variant whether they're on mobile, desktop, or clearing cookies every 20 minutes. Avoid session-based bucketing—it creates flickering experiences, causes re-bucketing, and erodes trust in experiment data. Lean on SDK-side evaluation for consistency that holds across your entire stack.

All this author’s posts
Experienced Marketing Operations Manager with a demonstrated history of working in the security software industry. Skilled in Lead Generation, Lead Management, B2B Marketing, Digital Marketing, and Demand Generation.