---
Key Takeaways
- AI-generated code fails without a real delivery context
- Knowledge graphs turn fragmented DevSecOps data into operational truth
- Platform teams must move from AI-assisted to AI-operational DevOps
- Overmodeling kills ROI faster than missing data
- Context must be fresh, permissioned, and use-case driven
---
AI can generate code in seconds. It still can’t ship software safely.
That gap isn’t about model quality or prompt engineering. It’s about context, and most software organizations don’t have a system that accurately reflects how pipelines, services, environments, policies, and teams actually relate to each other.
Without that context, AI doesn’t automate delivery. It amplifies risk.
I am responsible for building the Knowledge Graph that powers Harness AI, and I see this every day, working on AI infrastructure and data platforms at Harness, and it’s a recurring theme. AI-first delivery fails not because of intelligence, but because of fragmentation.
AI Is Not the Bottleneck, Context Is
Modern engineering organizations already generate more data than any human can reason about:
- CI pipelines
- Deployment workflows
- Cloud environments
- Security policies
- Cost signals
- Incident data
Each system works. The problem is that none of them agree on what the system actually is.
When something breaks, we don’t query systems. We page people. That’s the clearest signal you’ve hit the context bottleneck. When your organization depends on a few humans to resolve incidents, you don’t have a tooling problem. You have a context problem.
From AI-Assisted DevOps to AI-Operational DevOps
Most teams today operate in AI-assisted DevOps:
- AI helps write code
- AI generates pipelines
- AI summarizes logs
That’s helpful, but shallow.
AI-operational DevOps is different. Here, AI doesn’t just assist tasks. It understands how software actually moves from commit to production, including constraints, dependencies, and governance.
The difference is a platform problem. Without a shared context layer, AI remains a collection of point optimizations. With one, it becomes an operator.
What “Context” Actually Means in Software Delivery
Context is not dashboards. It’s not a data lake. And it’s definitely not another CMDB.
In practice, context means entities and relationships.
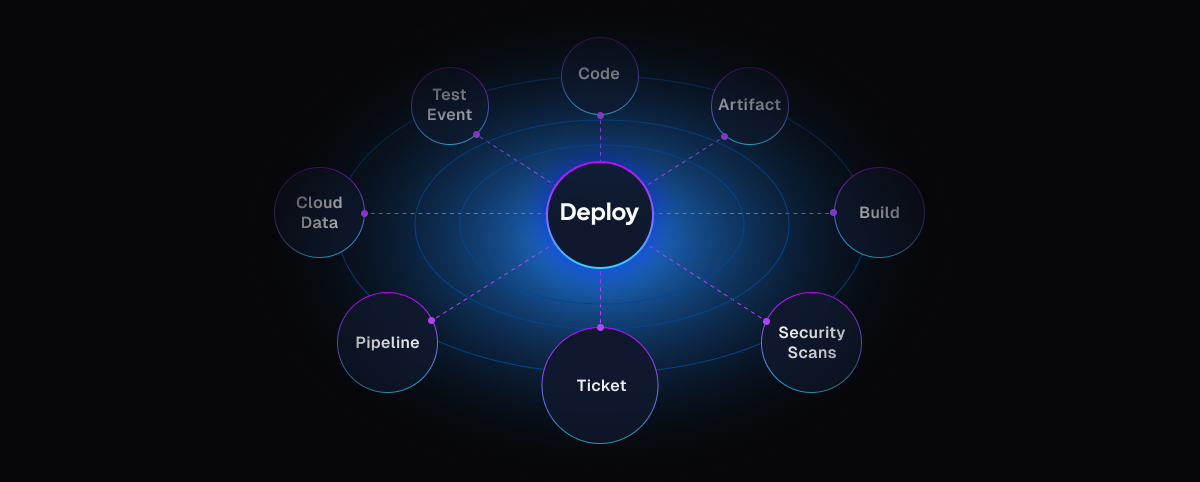
Core entities that matter
In DevSecOps environments, the most critical entities are:
- Pipelines (the workflow backbone)
- Services and artifacts
- Environments and clusters
- Policies and approvals
- Identities and permissions
Pipelines are often the natural center — not because they’re special, but because they express intent.
Relationships are where value emerges
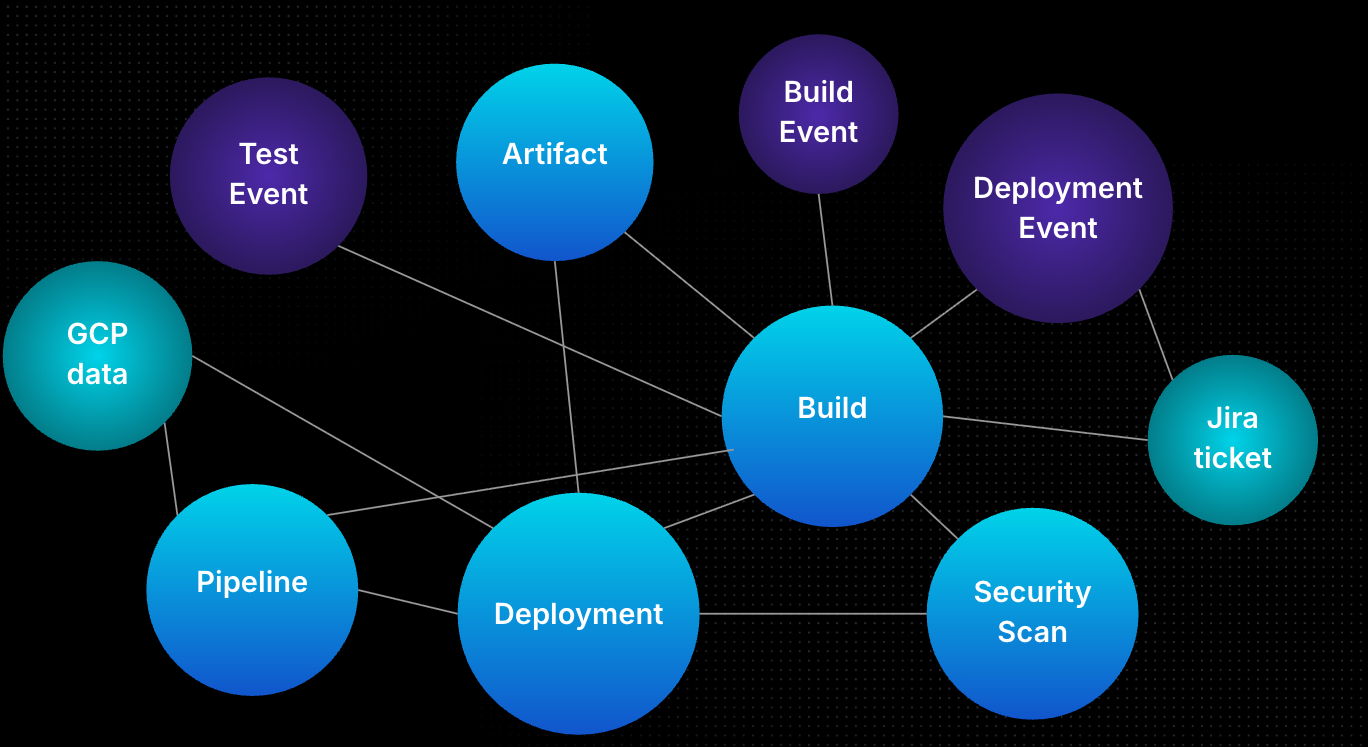
A pipeline alone isn’t context.
A pipeline links to:
- the cluster it deploys to
- The policies it must pass
- The identity running it
- the services it affects
That's the operational truth.
This is why knowledge graphs matter. They don’t store more data; they preserve meaning.
To truly transform the software development lifecycle, AI needs more than just intelligence, it needs deep, operational context. Harness AI uses a purpose-built Software Delivery Knowledge Graph to make AI fast, efficient, and exceptionally accurate. By bridging the gap between raw data and real-world delivery pipelines, we ensure that your AI operates with complete situational awareness from day one, allowing teams to ship faster without breaking things.
Why Knowledge Graphs Fail in Practice
I’ve seen three failure modes repeat across organizations:
- Overmodeling: Teams model everything before solving anything. The graph becomes academic and unused.
- Undermodeling: Teams skip key relationships, then wonder why AI gives shallow or incorrect answers.
- Stale context: Perfectly modeled data that’s a week old is useless during an outage.
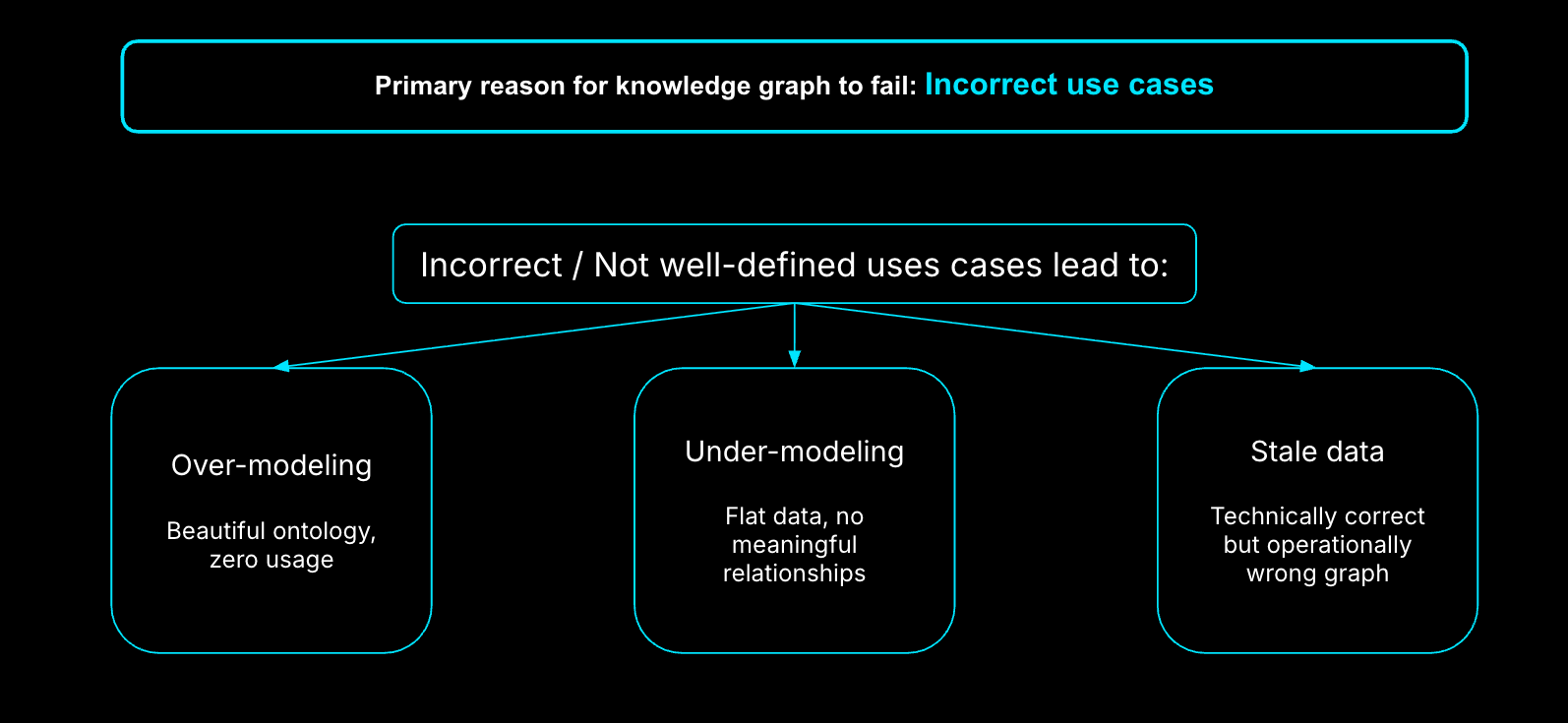
A knowledge graph only works when it’s use-case driven, minimal, and fresh.
The Minimum Viable Knowledge Graph
The fastest way to see value is not breadth, it’s focus. Start with one use case that cannot be solved by a single system.
A strong starting point:
- Root cause analysis for failed pipelines
To support that, you need:
- Git metadata
- CI/CD execution state
- Environment and access data
That’s often fewer than 10 entities. Everything else is enrichment, not day one requirements.
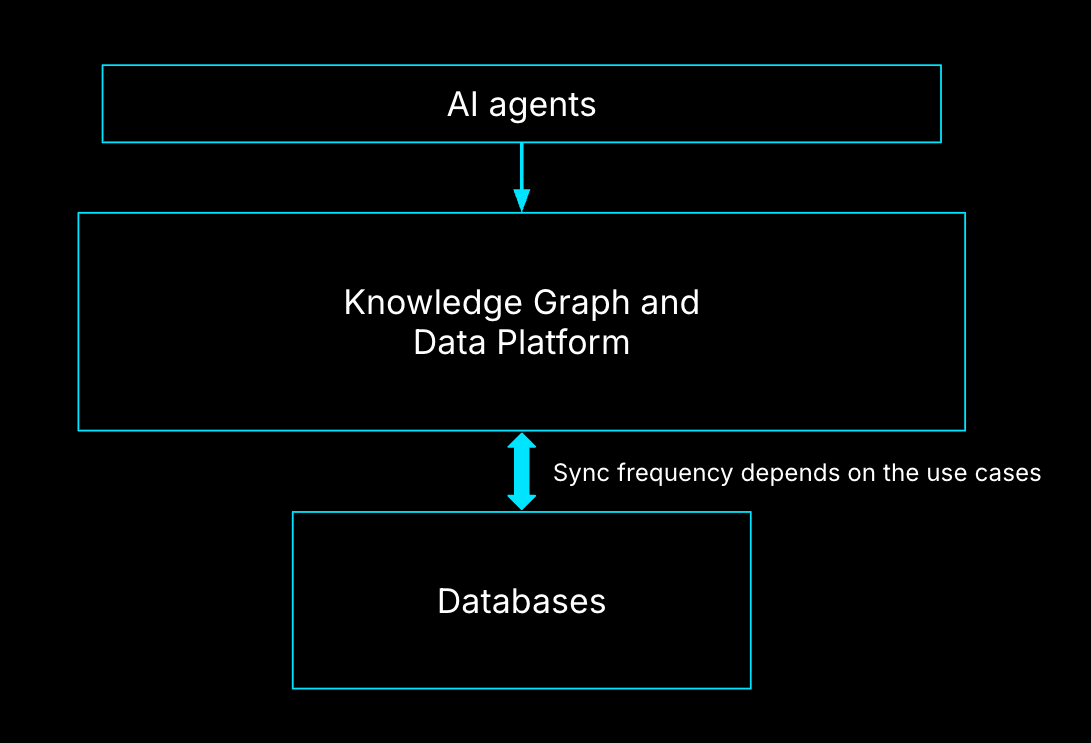
Freshness, Not Completeness, Determines Value
AI agents don’t need perfect context. They need the current context.
For delivery workflows, near real-time synchronization is often mandatory. When a deployment fails, an engineer doesn’t want last month’s answer; they want why it failed now. This is why the semantic layer matters. AI agents should interact with meaning, not raw tables.
Guardrails by Default: Policies, RBAC, and Trust
AI agents must be treated as extensions of humans, not superusers.
That means:
- RBAC applies to agents exactly as it does to people
- Policies define what context can be surfaced
- Least privilege is non-negotiable
At Harness, Policy as Code and native policy agents ensure AI can’t bypass governance — even when it’s acting autonomously.
How to Measure Whether Context Is Working
You don’t measure a knowledge graph by node count. You measure it by outcomes.
Four metrics matter:
- Answer quality (often validated using a secondary model)
- Human validation (does this reduce toil?)
- Evaluation over time (across models and versions)
- Cost efficiency (context without ROI is technical debt)
If context doesn’t improve decisions, it’s noise.
A Real AI-Driven Deployment Example
Imagine a developer says, in natural language: “Deploy this service to QA and production.”
Behind the scenes, an AI agent:
- Identifies the service and repo
- Generates a pipeline aligned with org standards
- Inserts approvals, security scans, and policies
- Validates access to target environments
If the pipeline fails, the same graph enables automated remediation:
- Was access revoked?
- Did a policy change?
- Did the artifact differ?
That’s not automation. That’s operational reasoning.
Why Cost, Rollbacks, and Incidents Demand Graph Context
Traditional dashboards tell you what happened. Knowledge graphs tell you why.
Cost spikes only make sense when linked to:
- deployment decisions
- environment selection
- service dependencies
Rollbacks are only safe when dependency graphs are understood. Rolling back a service without knowing the upstream and downstream impact is how outages cascade.
Guidance to Get Started (and What to Avoid)
Do this:
- Pick 1–2 high-impact use cases
- Model only what’s required
- Iterate through the semantic layer first
Avoid this:
- Modeling your entire SDLC upfront
- Treating the graph as a data dump
- Chasing completeness over usefulness
Context is a product, not a schema.
Conclusion
AI-first software delivery doesn’t fail because models aren’t smart enough. It fails because platforms don’t understand themselves.
Knowledge graphs give AI the one thing it can’t generate on its own: context grounded in reality, thus making them the primary pillar in AI-first software delivery context.
The future of software delivery isn't just automated; it's intelligently orchestrated. Because Harness AI uses a Software Delivery Knowledge Graph to make AI fast, efficient, and accurate, your teams can finally trust AI to handle complex operational workflows without adding risk. We’ve done the heavy lifting of mapping your operational truth so your AI can act with absolute precision.
FAQs
What’s the difference between observability and a knowledge / context graph?
Observability shows what’s happening. Knowledge/Context graphs explain what it means.
Do knowledge graphs replace existing tools?
No. They connect them.
Who owns the knowledge graph?
Everyone: platform, SRE, security, and application teams.
Is this only for large enterprises?
No. Smaller teams benefit faster because tribal knowledge is thinner.
Can AI work without a knowledge graph?
Yes, but only at the task level, not the system level.

All this author’s posts
Prateek Mittal is a PM at Harness, building and scaling the platform.