
Modern engineering teams have become exceptionally good at shipping software quickly.
With modern CI/CD platforms, what once required careful coordination, late-night release windows, and layers of approvals now happens almost invisibly. Pipelines execute in minutes. Releases flow continuously. The friction that once slowed everything down has been engineered away.
From the outside, it looks like progress in its purest form. Automation removed bottlenecks. Cloud infrastructure removed limits. Pipelines removed human delay. But beneath that acceleration, there is a quieter reality that only reveals itself at the worst possible moment.
Speed does not guarantee safety. And more importantly, speed does not guarantee confidence. Most teams today can answer one question with absolute certainty:
Did the deployment succeed?
Green pipeline. All checks passed. No errors.
But when you ask slightly different questions, the answers become far less certain:
Did the deployment actually make the system better? And more importantly - did it improve customer experience, accelerate transactions, and drive business outcomes, or did it quietly degrade performance and impact revenue?
That difference may sound subtle, but in practice, it is where reliability either exists - or quietly breaks. This gap between deployment success and validated system behavior is exactly where continuous verification becomes critical.
And nowhere has this been more evident than in a financial services transformation I witnessed firsthand, where a perfectly “successful” deployment slowly degraded a live payment system without anyone noticing.
When a successful deployment quietly degraded payments
A large global bank was deep into modernizing its digital payment platform. They were not experimenting. They were executing at scale. Their architecture was exactly what you would expect from a mature engineering organization. Kubernetes-based microservices, fully automated CD pipelines, Infrastructure defined as code and testing embedded across every stage. Over time, they had achieved something remarkable. Deployments had become routine. What once required weekend coordination and careful planning was now happening several times a day, almost without discussion. Releases were no longer events. They were background activities.
Their typical deployment pipeline looked something like this:
Build → Security scan → Integration tests → Deploy → Smoke tests
.png)
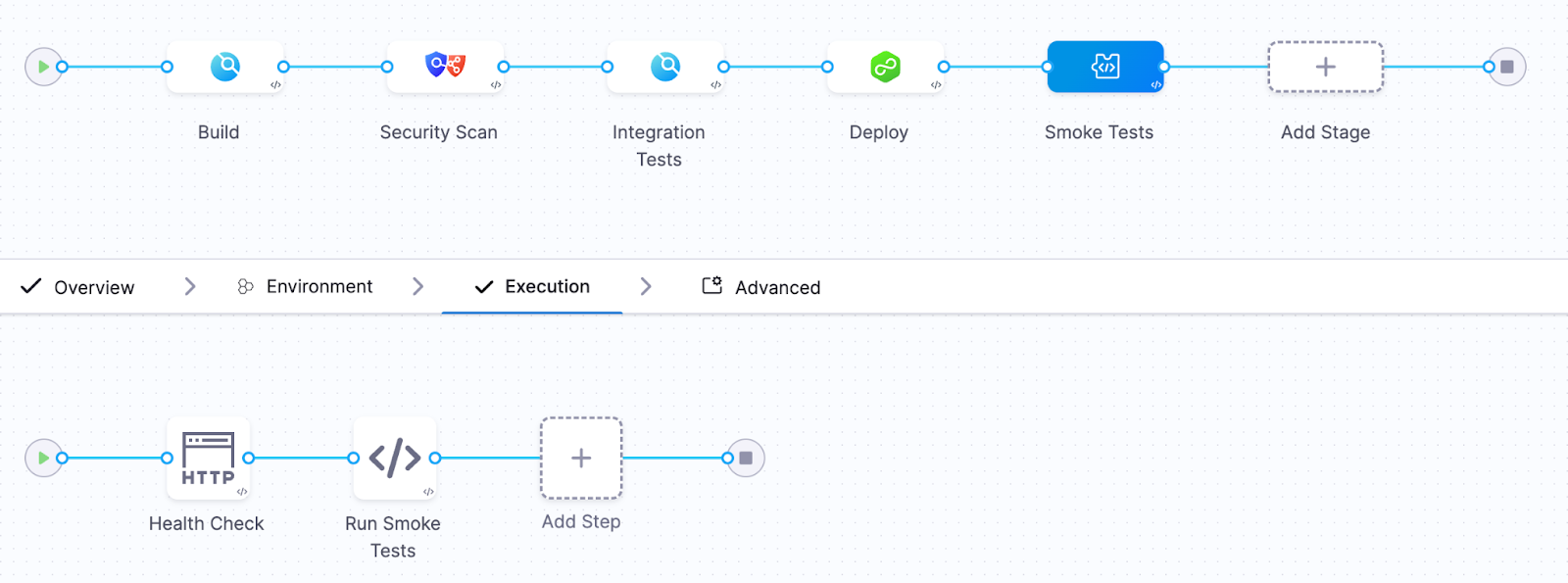
Build flowing into security scanning, into integration testing, then deployment, followed by smoke tests. It was elegant. Automated. The kind of pipeline you would proudly present at a conference. And for a while, it worked perfectly. Until one Friday afternoon…
The incident
A new version of the transaction validation service was deployed.
The release pipeline executed flawlessly.
Every step reported success.
- All automated tests passed
- The deployment completed successfully
- Kubernetes health checks reported that the service was ready
The pipeline marked the deployment as successful. The release moved forward. Engineers moved on to other tasks. But about twenty minutes later, something subtle began to happen. Payment processing latency began creeping upward. At first it was small.
Then the following symptoms appeared:
- payment processing latency increased by 40%
- transaction retries began increasing
- error rates slowly started climbing
Nothing catastrophic happened. The system did not crash. Pods did not fail. Containers did not restart. From the perspective of Kubernetes, everything looked healthy.
But the platform was slowly degrading. Revenue and customer experience were definitely impacted. Because the pipeline had already declared success, there was no mechanism to reconsider that decision. No feedback loop connecting real system behavior back into the deployment outcome.
The problem remained undetected for nearly half an hour. By the time engineers realized what was happening, the impact had already spread. Thousands of delayed transactions. Customer complaints increasing. Engineering teams pulled into urgent investigation.
The cause, when eventually identified, was deceptively simple. A small change in a database query. Slightly inefficient. Invisible under test conditions. But under real production load, it introduced just enough latency to ripple across the system.
Unit tests did not catch it. Integration tests did not catch it. Kubernetes health checks did not catch it. But the signals were there, visible in the observability platform. They simply were not part of the deployment decision.
A pattern I keep seeing in the field
What makes this story compelling is not that it happened. It is that it keeps happening. Over the past six months, across multiple enterprise environments, I have seen the same pattern emerge with striking consistency.
Different companies. Different industries. Different teams.
The same blind spot.
Every organization had invested heavily in observability. Their platforms were powered by tools like Datadog, Dynatrace, New Relic, AppDynamics, and Grafana.
Their systems were instrumented in depth. Metrics, logs, traces, business indicators - everything was being captured. Their dashboards were rich. Their visibility was impressive.
They could see everything. But only after the fact.
Because when I examined how deployments were validated, the story changed completely.
Pipelines relied almost exclusively on Kubernetes readiness and liveness checks, sometimes complemented by simple smoke tests. If the service started and responded, the deployment was considered successful. And that was the end of the decision process. Observability existed - but outside the pipeline.
It was a tool for humans to investigate problems, not a mechanism for the system to prevent them. In every case, the realization was the same. They had built world-class observability capabilities. But none of it was being used to decide whether a deployment should proceed.
Kubernetes health checks answer the wrong question
Kubernetes health checks are essential. They are incredibly effective at keeping systems running and enabling self-healing behavior. But they were never designed to answer the question that matters most during a deployment.
They tell you whether something is alive. They tell you whether it can receive traffic. They do not tell you whether it is behaving correctly. And that distinction is where modern incidents live.
A system can be fully operational from Kubernetes’ perspective while simultaneously degrading the experience for every user interacting with it.
I have seen systems where database latency doubles without any restart. Where memory usage slowly increases over hours. Where microservices begin retrying requests in subtle feedback loops. Where queues build silently until they become bottlenecks.
All of it happening while every pod remains in a perfectly “ready” state. Kubernetes reports success. Users experience degradation. The pipeline sees green. Reality is different. This is the illusion of a successful deployment.
The missing piece: continuous verification
Continuous verification changes the nature of the question. Instead of asking whether the deployment completed, it asks whether the system is behaving as expected.
It takes the signals already present in your preferred Observability platforms and brings them directly into the pipeline itself. Now the pipeline is no longer blind. It observes latency. Error rates. Throughput. Infrastructure signals. Even business-level indicators. It compares the behavior of the new version against a known baseline. And most importantly, it acts.
If the system begins to drift away from expected behavior, even subtly, the pipeline can stop the rollout and revert to a known good state automatically. No delay. No escalation. No manual intervention.
What the new pipeline looked like
After the incident, the platform team redesigned their approach. They integrated continuous verification using Harness with telemetry from their loved Observability tool.
Their new pipeline looked like this:
Build → Security Scan → Integration tests → Canary deployment → Continuous verification → Promote or rollback
.png)
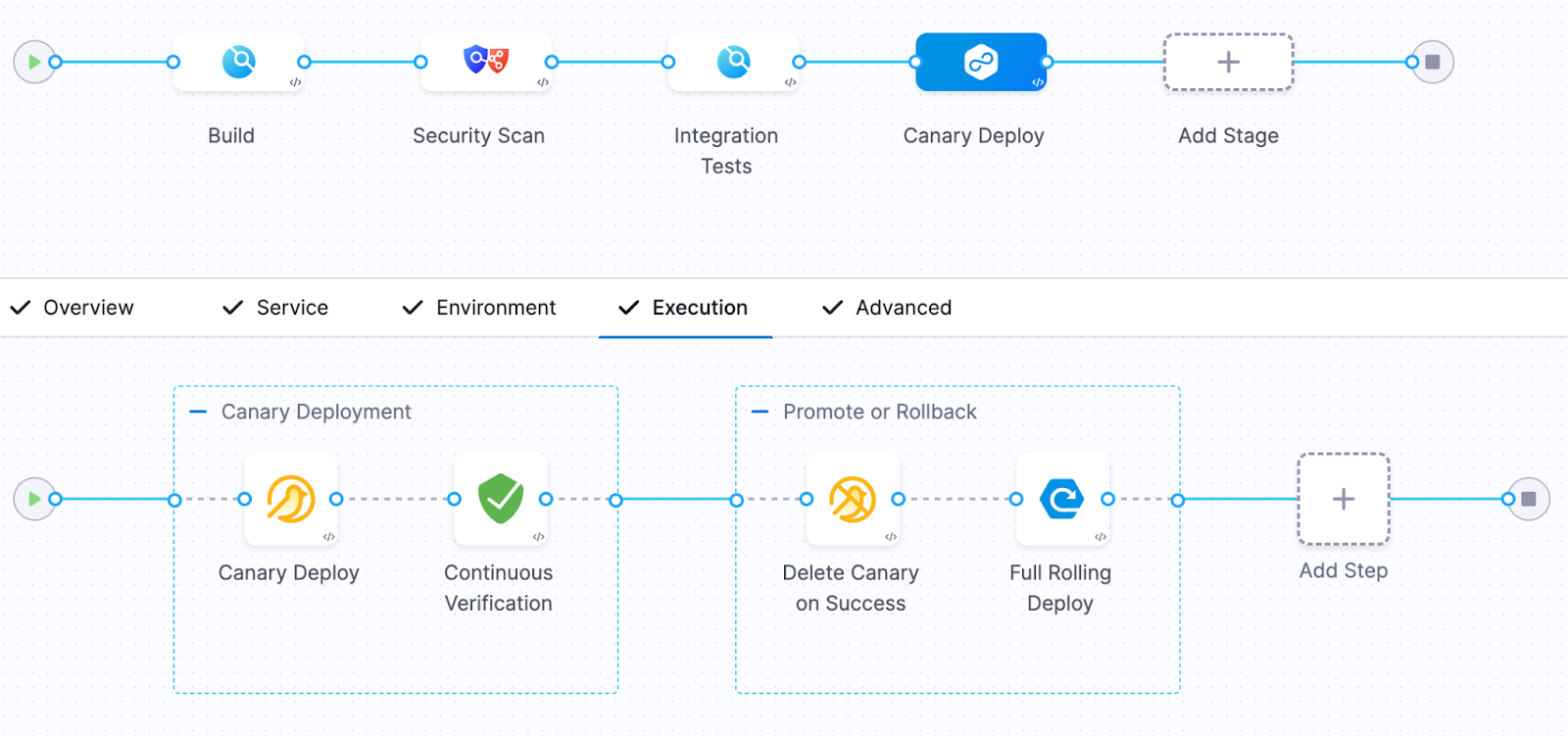
During the canary phase, only a small percentage of traffic was routed to the new version.
The verification step analyzed key signals including:
- p95 request latency
- API error rates
- database query duration
- CPU and memory pressure
- custom business metrics
The system compared two sets of signals:
Baseline behavior (previous version)
versus
Canary behavior (new version)
If the canary version performed worse than the baseline, the system immediately rejected the release.
The next deployment
Two weeks later, another release was pushed. This time, the sequence unfolded differently. The canary deployment began. Traffic started flowing. Observability data was analyzed in real time. Within minutes, a deviation appeared. Not dramatic. Not catastrophic. But enough.
Latency began to drift beyond acceptable thresholds. This time, the pipeline saw it. And without hesitation, it rolled back. No incident. No escalation. No customer impact. Just a silent correction, executed automatically. The kind of outcome most users will never notice - but that defines operational excellence.
Why continuous verification matters
Traditional pipelines answer a binary question.
Did the code deploy?
Continuous verification answers the questions that actually matter.
Did the system behave correctly after deployment? Did it improve customer experience?
In modern systems - distributed, dynamic, deeply interconnected - failures rarely present themselves as crashes. They appear as degradation. And if your pipeline cannot detect degradation, it is only solving half the problem. Continuous verification transforms observability into an automated safety gate for releases.It closes the loop.
The measurable impact
After implementing continuous verification, the platform team observed significant improvements. But the most important improvement was not technical. It was cultural. Engineers regained the confidence to deploy frequently without fear of hidden regressions.
DevSecOps needs runtime verification
Modern DevSecOps practices have matured significantly. We validate security. We enforce compliance. We ensure code quality. But we still tend to stop validation at the moment of deployment. Continuous verification extends that validation into real system behavior. It transforms the pipeline into a closed loop. Not just build, test, deploy. But build, test, deploy, verify. And that final step is where trust is established.
The future of continuous delivery
The most advanced engineering organizations are already evolving toward a new model. Deployment decisions are no longer based solely on pre-release validation. They are informed by live system behavior.
Observability is no longer a dashboard. It becomes part of the control system.
Platforms like Harness, integrated with your Observability tools, are enabling this shift. And once teams adopt this model, the difference is profound.
Final thought
Continuous delivery solved the problem of speed. Continuous verification solves the problem of confidence.
If your pipeline stops when deployment succeeds, you are still operating with incomplete information. Because in modern software delivery, success is not defined by whether something was deployed. It is defined by whether that deployment made the system better.
And the only reliable way to answer that - automatically, consistently, and at scale - is through continuous verification. Start treating observability as a release gate - not just a dashboard!

All this author’s posts
Stefano Mazzone is a DevSecOps architect with 20+ years’ experience in software, platform engineering, and observability. At Harness, he helps enterprises build scalable, secure delivery platforms, focusing on CI/CD, governance, and data-driven reliability.