
The Gap: Modern DevOps Stops at the Database
Most development teams today build everything around Git, and deploy with GitOps principles.
Code sits in version controlled environments, changes go through PRs, and deployments are handled through modern CI/CD. That part is pretty standard at this point, especially when using a modern DevOps platform like Harness.
MongoDB fits into that developer world and workflow pretty naturally. Data is stored in documents that look a lot like JSON, the format many developers already use in application code and APIs. Under the hood, MongoDB stores those documents as BSON, which is essentially a binary form of JSON that supports additional data types like dates, object IDs, and binary data. That means developers get a familiar model to work with, while MongoDB gets a format that is efficient for storing and querying application data.

Looks just like JSON, with native types like ObjectId and dates powered by BSON.
The tradeoff is that structure isn’t always defined upfront. Schemas change over time, and not always in a clean or consistent way.
Collections can contain documents with different shapes. Index changes can directly impact performance. These aren’t problems on their own, but they require discipline to manage safely.
MongoDB changes are often handled outside the standard development workflow, whether that’s by developers, platform teams, or database teams.
Teams rely on application-level updates or one-off scripts to backfill data, modify structures, or create indexes. These approaches work, but they’re not always consistently versioned in Git. Execution can vary across environments, and review or validation is often informal.
The result is limited visibility into what changed, when it changed, and how it was applied. Over time, that leads to inconsistencies between environments and increased risk during deployment.
Flexibility is powerful, but without proper controls it introduces risk.
To solve this, teams need to bring MongoDB changes into the same workflow they already trust for application code: Git-driven, reviewable, and automated.
What GitOps for MongoDB Actually Looks Like
GitOps for MongoDB isn’t about changing how Mongo works. It’s about changing how changes are managed.
Instead of handling updates through scripts or application logic alone, database changes are treated like application code. Index creation, schema validation rules, and migration scripts are all defined in Git and tracked over time. This includes MongoDB’s native schema validation rules, which can be versioned and applied consistently across environments.
Changes need to go through pull requests, just like any other code change. This allows developers, platform teams, and DBAs to review what’s being modified before anything runs in an environment.
From there, pipelines handle the validation and deployment. Changes are applied consistently across environments, rather than being run manually and potentially differently each time.
In practice, this means a new field, an index, or a backfill isn’t just a script someone runs once. It’s a versioned change that can be reviewed, tested, and repeated.
This isn’t about forcing rigid schemas onto MongoDB. It’s about making changes visible, consistent, and easier to manage as systems grow.
Harness DB DevOps provides the structure to do this. With Harness, we define changes as changesets, store them in Git, and deploy them through pipelines with built-in validation and policy checks.
To demonstrate how this works, we will walk through a practical MongoDB change from start to finish.
Example: Managing a MongoDB Change End-to-End
Here’s a simple example: A team needs to add a new userPreferences field to the users collection and create an index to support a new query.
Instead of writing a script and running it manually, we define the change and commit it to Git.
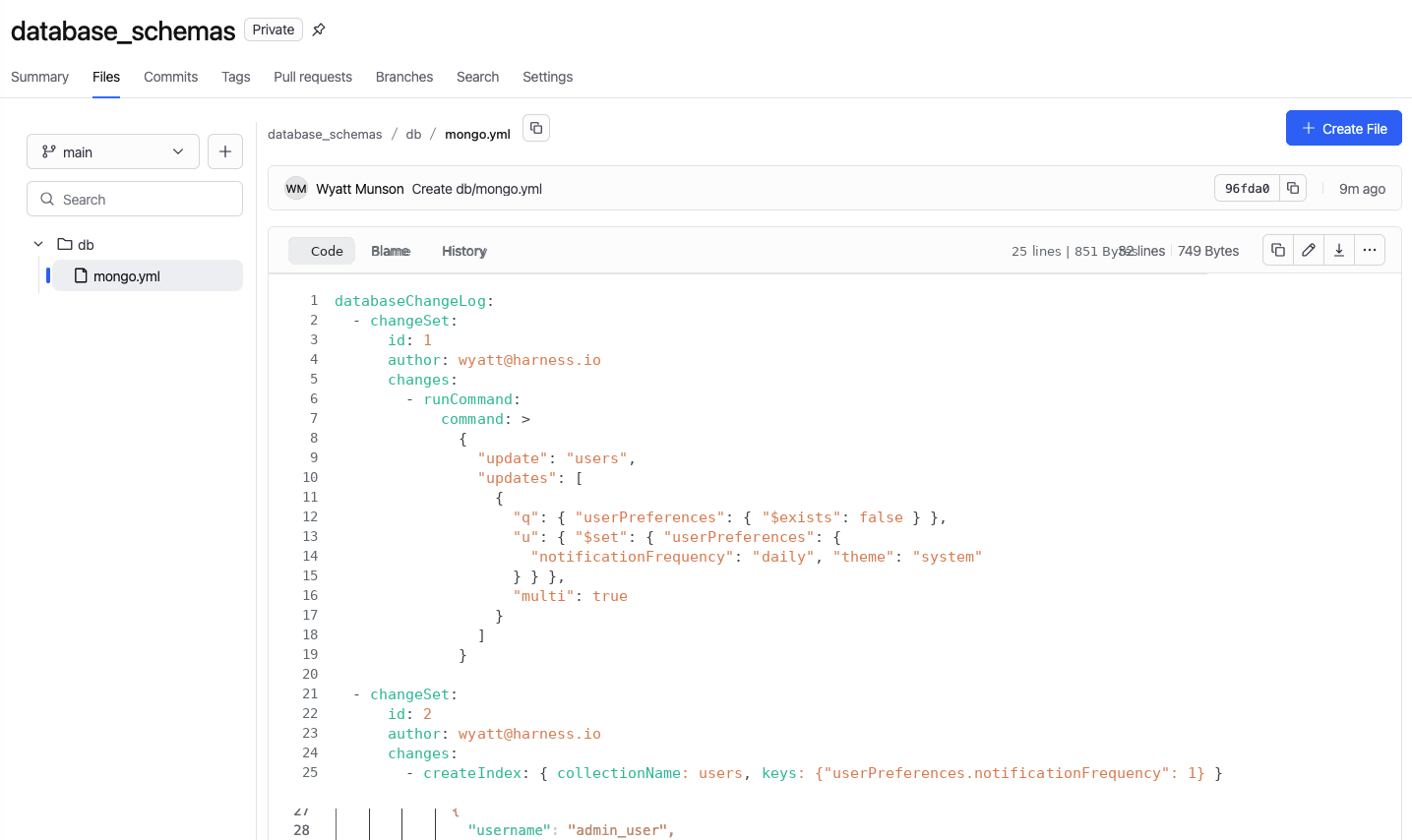
1. Define the change in Git
A developer creates the update as a changeset. That includes the logic to add or backfill the new field, along with the createIndex operation needed for performance. The change is committed alongside application code, like any other update.
2. Open a pull request
From there, the change goes through a pull request. Other developers or DBAs can review what’s being changed before anything runs. If something looks off, it gets caught here instead of in production.
3. Let the pipeline take over
Once the change is approved, the pipeline takes over.
The Pipeline

Before anything gets applied, the change is validated and previewed against the target environment. This helps catch issues early, whether it’s a conflict, a bad query pattern, or something that could impact performance.
This is especially important for heavy operations like index creation on massive collections, where resource contention and performance degradation are real risks. Instead of running those changes manually, pipelines can enforce safe rollout strategies like rolling index creations across replica sets, without manual intervention.
Policies are enforced as part of that same process, with required approvals, environment rules, and other guardrails checked automatically so teams aren’t relying on someone to manually verify every step.
Once everything passes, the change is deployed through the pipeline and applied consistently across environments, moving from dev to staging to production in a controlled way. No one is logging into a database to run scripts by hand.
Now, everything is tracked. You can see what was applied, where it was deployed, when it happened, and who approved it, with a full history available if something needs to be reviewed or rolled back later.
Sound familiar? This workflow should sound a lot like application delivery, where changes are versioned, reviewed, validated before deployment, and visible after.
From Manual Oversight to Guardrails
Traditionally, database changes have been tightly controlled by DBAs. They review scripts, approve changes, and sometimes execute them manually in each environment. That model helps reduce risk, but it doesn’t scale as teams grow and release more frequently.
With a GitOps approach, that control doesn’t disappear, it moves earlier in the process.
Instead of reviewing every individual change, database teams define policies and standards up front. Those rules are then enforced automatically through pipelines. Every change must pass the same checks before it reaches an environment, without requiring manual intervention each time.
In practice, this means:
- Required approvals are enforced automatically
- Deployment rules are validated before execution
- Production environments can have stricter controls than lower environments
- Policies are applied consistently across every change
The role of the database team evolves from gatekeeper to system designer. Rather than being involved in every deployment, they define the guardrails that ensure every deployment is safe.
Developers still move quickly, but now within a controlled, repeatable system.
What Teams Actually Gain
Bringing MongoDB into a Git-driven workflow changes how teams ship.
- Faster delivery
Developers don’t wait on manual reviews or execution. Changes move through the same workflow as application code. - Consistent environments
Changes are applied the same way every time, reducing drift between dev, staging, and production. - More predictable deployments
Validation and policy checks happen before execution, catching issues earlier and reducing surprises. - Built-in auditability
Every change is versioned, reviewed, and tracked, with full visibility into what changed, when, and why.
MongoDB's flexibility doesn't eliminate the need for structure - it just shifts the responsibility for maintaining consistency from the database itself to your development processes.
If your application is managed through Git, your database should be too.

All this author’s posts
Jesse Wang is the Product Marketing Manager for Harness Database DevOps. A former full stack software engineer with go-to-market experience, he has worked with dozens of companies and spoken with countless developers on their DevOps modernization journeys.