
The Five-Minute Demo Problem
Every agent demo follows the same arc. The agent calls an API. A deployment triggers. A ticket gets created. The audience is impressed.
Then someone asks a real question: "Which regions had the highest order failure rate this quarter, and are any of them linked to vendor SLA breaches?"
That question crosses four entity types — orders, fulfillment records, vendors, SLA contracts. Without structured access to the underlying data, answering it means discovering which APIs exist, paginating through thousands of verbose JSON records, inferring which field names correspond across responses, and computing aggregations in the context window. A lot of work for both the agent and the infrastructure — and the context window bears the cost.
Now consider what happens when the agent has structured data infrastructure underneath:
User: Which regions had the highest order failure rate this quarter,
and are any linked to vendor SLA breaches?
Agent → describe(type='order')
← fields: region, status, created_at, vendor_id
← aggregations: COUNT, SUM supported on status; GROUP BY on region
Agent → related_types(type='order')
← Order →[has_vendor]→ Vendor →[governed_by]→ Contract
← join keys declared: order.vendor_id = vendor.id,
vendor.contract_id = contract.id
Agent → validate(query="""
SELECT region,
COUNT(*) AS total,
SUM(CASE WHEN status='failed' THEN 1 END) / COUNT(*) AS failure_rate,
COUNT(CASE WHEN contract.sla_breached THEN 1 END) AS sla_breaches
FROM orders
JOIN vendors ON orders.vendor_id = vendors.id
JOIN contracts ON vendors.contract_id = contracts.id
WHERE created_at >= '2025-01-01'
GROUP BY region
ORDER BY failure_rate DESC
""")
← Valid. Estimated result: 6 rows.
Agent → run(query=...)
← | region | total | failure_rate | sla_breaches |
| APAC | 1247 | 0.083 | 3 |
| EMEA | 893 | 0.071 | 1 |
| NA | 2104 | 0.042 | 0 |
Agent: APAC has the highest order failure rate at 8.3% this quarter,
with 3 linked SLA breaches. EMEA follows at 7.1% with 1 breach.
North America is lowest at 4.2% with no breaches.
Four tool calls. ~800 tokens of context consumed. A correct, verifiable answer. The query is validated against a formal schema before execution, so invalid field names are caught early. The joins are declared in the relationship graph. Aggregation happens at the data layer, not in the LLM's working memory.
The structure does the heavy lifting — the agent focuses on understanding the question and interpreting the result.

Agent Quality Has Dimensions
When you evaluate agents rigorously, quality breaks down along specific dimensions. What's striking is that every one of them maps to a data infrastructure capability.
Three foundational data architecture concepts do most of the work: a domain ontology (entity types, fields, constraints), a relationship graph (declared joins with explicit keys and cardinality), and a query engine (validate-then-execute against a formal grammar). These are the primitives that take years to build. Layer on data-layer access control and a dispatch table for tool routing, and you get a complete mapping from infrastructure to agent quality:

Fig. 2 — Infrastructure capabilities map to quality dimensions
Correctness: Ontologies Turn Silent Errors Into Loud Ones
An ontology — a formal description of entity types, their fields, and their valid operations — does for agents what a type system does for code. It makes invalid operations visible before they execute.
A well-modeled field isn't just a name and a data type. It carries operational constraints: this field is numeric, measured in milliseconds, supports SUM/AVG/P95, is sortable but not groupable because it's continuous. When an agent generates GROUP BY fulfillment_time, that's a semantic error caught before execution. When it generates WHERE status = 'falied', validation returns "did you mean 'failed'?" and the agent retries.
Here's what that looks like in practice:
Agent → validate(query="SELECT region, GROUP BY fulfillment_time ...")
← Error: fulfillment_time is a continuous numeric field (milliseconds).
GROUP BY is not supported. Supported operations: SUM, AVG, P95, MIN, MAX.
Did you mean GROUP BY region?
Agent → validate(query="SELECT region, ... WHERE status = 'falied' ...")
← Error: 'falied' is not a valid value for field status.
Valid values: 'active', 'failed', 'completed', 'pending'.
// Both errors caught before any data is queried.
// The agent retries with corrected fields and gets a valid result.// Both errors caught before any data is queried.
// The agent retries with corrected fields and gets a valid result.
This is the difference between approximately right and verifiably right. With an ontology, you can prove correctness by validating the query before it ever touches the data. Errors become loud and fixable — not silent and compounding. And because correctness is now deterministic, it becomes measurable:
- ExactMatch: Does the agent's structured query return the same result as the gold query? Testable, because both are deterministic.
- TaskCompletion: Did the agent answer the full question, including the SLA breach correlation? Achievable, because the relationship graph told it the join existed.
Groundedness: The Relationship Graph Is the Citation Layer
Groundedness asks: can the agent point to where its answer came from?
When every answer traces to a specific query, validated against a specific schema, executed against a specific data source — the agent can cite its work:
"Failure rate of 8.3% for APAC: computed as SUM(status='failed') / COUNT(*) on the orders table, filtered to Q1 2025, grouped by region. Joins: orders.vendor_id → vendors.id → contracts.contract_id. Source query validated against schema version 2.4.1."
The relationship graph is what makes this possible for cross-entity questions. When the agent discovers that Order relates to Vendor via vendor_id, and Vendor relates to Contract via contract_id, those aren't inferences — they're declared edges with explicit join keys, cardinality, and traversal names.
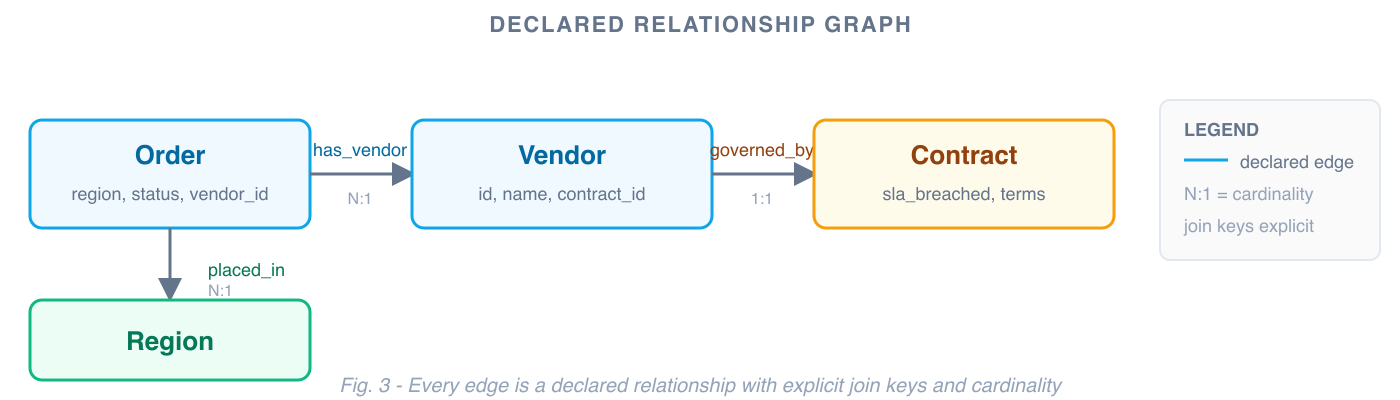
Every relationship the agent uses is traceable to a declared edge. If something looks off, you can follow the chain: was the join key correct? Was the cardinality right? Was the traversal path valid? Debugging becomes inspection, not guesswork.
This matters especially as domain complexity grows. When relationships are declared explicitly — rather than inferred from field name similarity at query time — the system scales to hundreds of entity types without losing precision.
Groundedness metrics become tractable:
- Faithfulness: Is every claim in the answer supported by data the agent actually retrieved? Yes — the query result is the sole data source, and it's logged.
- ContextPrecision: Did the agent retrieve only relevant context? Yes — schema discovery is demand-driven, not a full dump.
Safety: Access Control at the Data Layer
Agent safety is often discussed in terms of prompt injection and output filtering. Those matter. But the strongest safety posture comes from enforcing access control where the data lives.
When the data infrastructure has its own access control layer — row-level security, field-level permissions, tenant isolation — the agent inherits those constraints automatically. The data layer only returns what the user is authorized to see, regardless of what the agent requests.
This means safety isn't a bolt-on. It's architectural. A support agent querying customer data sees only their assigned accounts — not because the prompt says "only show assigned accounts," but because the data layer enforces row-level filtering before results reach the context window. PII fields are redacted at the source. Fabrication resistance follows naturally: when every answer is a validated query result, the agent is working from real data — not synthesizing from memory.
Trajectory: Guided Navigation vs. Blind Exploration
Trajectory quality asks: did the agent take a good path to the answer? Did it use the right tools in the right order?
Structured infrastructure transforms answering complex questions from open-ended planning into guided navigation. A well-behaved agent follows a predictable pattern:
1. list(type='order') // what entities are relevant? ~200 tokens
2. describe(type='order') // what fields exist? ~150 tokens
3. related_types(type='order') // how do they connect?
4. validate(query=...) // catch errors before execution
5. execute(query=...) // compact result, not raw pagesThe trajectory is predictable, short, and auditable. Five tool calls for a complex multi-entity analytical question. And because the pattern is well-defined, deviations from it are measurable:
- PlanAdherence: Did the agent follow the discover → relate → query → validate → execute pattern?
- StepEfficiency: How many tool calls did it make? Structured approach: typically 4–5 for complex analytical questions.
- ToolCorrectness: Did it use the right tools? With a dispatch table, there are only a handful of verbs to choose from. A smaller decision space leads to better choices.
The Dispatch Table Pattern
The key architectural concept here is the dispatch table. Most agent tool designs grow linearly with domain size: one tool per API endpoint, new tools for each new capability, an ever-expanding list of options the agent must choose from. The dispatch table inverts this.
Instead of one tool per endpoint, you expose a small set of generic verbs that dispatch by resource type at runtime. The agent learns four verbs. New domains register type definitions — fields, relationships, valid operations — and the existing verbs work immediately. The tool surface stays flat as capabilities grow.
Endpoint-per-tool (grows with domain):
get_orders()
list_orders()
get_vendors()
list_vendors()
get_contracts()
list_contracts()
search_orders_by_region()
filter_vendors_by_status()
get_sla_breach_count()
...Dispatch table (stays flat):
list(type='order')
list(type='vendor')
list(type='contract')
get(type='vendor', id=...)
describe(type='contract')
execute(query=...)
// new domain? register a type.
// no new tools.Why does this matter for trajectory? A smaller decision space leads to better routing decisions. When the agent must choose from four verbs instead of forty endpoints, it makes fewer wrong turns. The tool descriptions themselves consume less context. And you can test routing exhaustively — the verb space is finite and well-defined.
The dispatch table also creates a clear extension contract. New domains don't negotiate a new API surface with the agent — they register a type definition with declared fields, valid operations, and relationships. The agent's reasoning layer never changes. Only the data model grows.
Performance: Aggregation Belongs at the Data Layer
The context window has a token budget. Every token spent on raw data is a token not available for reasoning.
Structured infrastructure shifts the heavy work — aggregation, joins, filtering — to the data layer. In the running example, the agent receives a compact 6-row table (~800 tokens) instead of processing thousands of raw records. A 10-row aggregation will always be smaller than the 10,000 records it summarizes. This ratio is structural, and it holds regardless of token pricing or context window size.
The design principles follow directly:
Route to the data layer. Every question that can be answered by a server-side query should be. One structured query returning a 10-row table is more efficient than assembling the same answer from multiple API calls.
Schema discovery on demand. Don't load the full ontology upfront. Let the agent introspect the specific types it needs, when it needs them.
Keep the tool surface small. Every tool description consumes context. A dispatch table with generic verbs keeps the footprint flat.
Validate before execute. Don't waste context on executing bad queries and parsing error responses. Catch errors before they consume tokens.
Performance metrics become straightforward:
- Latency: One server-side query completes faster than multiple sequential API calls with LLM reasoning between each.
- TokenCost: Compact structured results consume a fraction of the context budget compared to raw payloads. Directly measurable, directly attributable to architecture.
- CostEfficiency: Correct answer per dollar spent. Structure improves both the numerator (quality) and the denominator (cost).
These Dimensions Reinforce Each Other
These dimensions don't improve independently. They compound.
Better trajectory — fewer, more targeted tool calls — improves performance by reducing context consumption, and improves correctness by keeping less noise in the context. Better groundedness makes safety auditable: you can prove the agent only accessed authorized data because every answer traces to a specific validated query. Better correctness reduces the need for output-layer guardrails, because an agent operating on validated schema data can't fabricate answers that don't exist in the ontology.
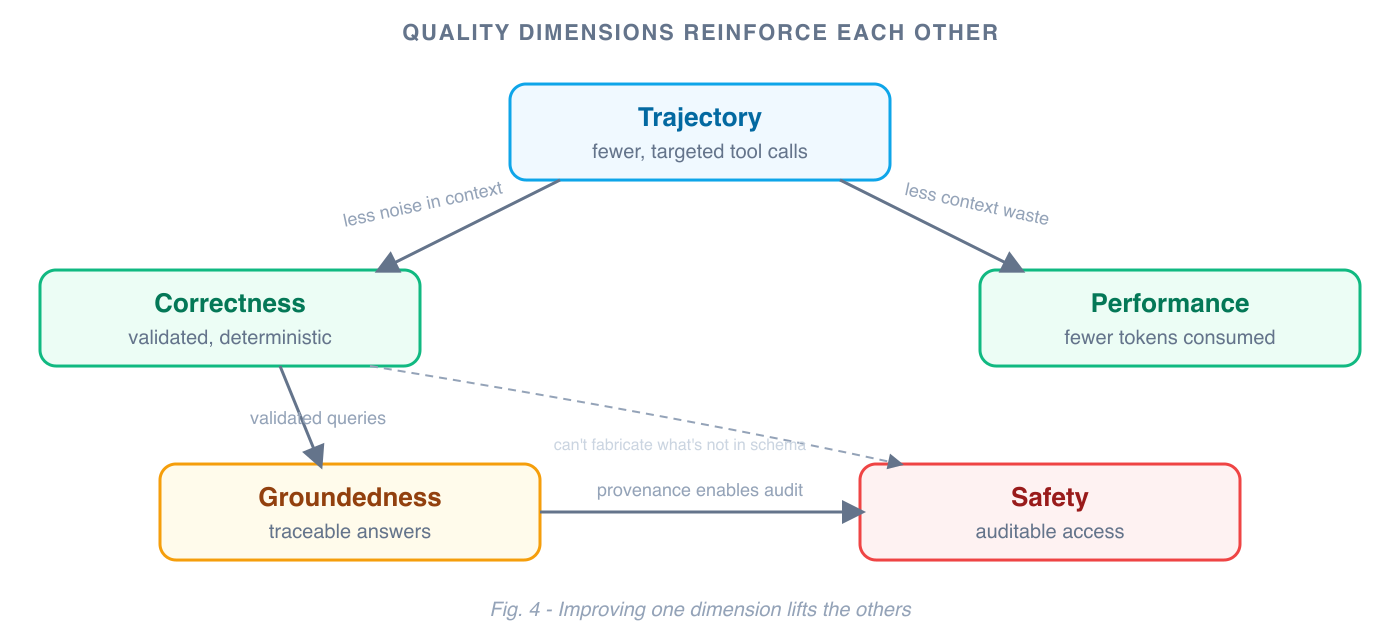
This is the core insight: investing in data infrastructure doesn't just improve one dimension of agent quality. It lifts all of them simultaneously, because they all share the same root cause — the agent's ability to operate on structured, validated, well-modeled data instead of raw API noise.
The Investment That Compounds
If you've invested in modeling your enterprise data — a domain ontology, a relationship graph, a query engine, access control at the data layer — you're most of the way to a reliable agent platform. The protocol layer (MCP, tool registration, context formatting) is weeks of work. The data infrastructure is years.
But that investment compounds in a specific way. Every new entity type added to the ontology makes every agent more capable — without changing a line of agent code. Every declared relationship in the graph is a cross-domain question that agents can now answer correctly. Every access control rule at the data layer is a safety guarantee that applies to every agent, every tool, every query.
This investment is real. Ontologies require upfront modeling and ongoing maintenance. Schema evolution — adding fields, changing relationships, deprecating types — needs a migration strategy, the same way a database schema does. Modeling judgment calls are hard: which fields are groupable, which aggregations are meaningful, what cardinality to declare. Not everything needs to be fully modeled — logs, traces, and free-text payloads can't be captured in an ontology. The goal is to model enough of the structural envelope (identifiers, timestamps, categories, relationships) that the ontology becomes the primary routing mechanism for agent queries.
These aren't AI problems. They're data modeling problems. But the organizations that build the most capable agent platforms will be the ones that took them seriously. Not because models aren't powerful — they are. But because well-modeled data infrastructure lets models do what they're best at (reasoning, synthesis, explanation) while the infrastructure handles what it's best at (validation, aggregation, access control, provenance).
The path from data platform to agent platform is shorter than most people think. The quality gap it creates — across correctness, groundedness, safety, trajectory, and performance — is structural. Structure is what makes agents reliable. And it's an investment that keeps paying off.
Further Reading
- Learn how a Knowledge Graph underpins these architectural choices to solve token cost, latency, and hallucination issues inherent to raw API access: Why Harness AI uses a Knowledge Graph.
- The shift from a linear API model to this resource-type dispatch table is visible in the design of the Harness MCP server: Harness MCP Server Redesign.
- For a holistic approach that seamlessly integrates structured data with unstructured sources like logs and documentation, explore how a hybrid Knowledge Graph and RAG system works in practice: Knowledge Graph RAG.

All this author’s posts
Sunil is an Engineering Architect focused on building production-grade AI and data platforms at scale.